/
index.qmd
404 lines (259 loc) · 12 KB
/
index.qmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
---
filters:
- roughnotation
format:
revealjs:
appearance:
appearparents: true
code-line-numbers: false
code-link: false
code-copy: false
# callout-appearance: simple
# syntax-definitions:
# - ./docs/python.xml
scrollable: true
title-block-style: none
slide-number: c
title-slide-style: default
chalkboard:
buttons: false
auto-animate: true
reference-location: section
touch: true
pause: false
footnotes-hover: true
citations-hover: true
preview-links: true
controls-tutorial: true
controls: false
logo: "https://raw.githubusercontent.com/saforem2/llm-lunch-talk/main/docs/assets/anl.svg"
history: false
highlight-style: "atom-one"
css:
- css/default.css
- css/callouts-html.css
theme:
# - white
# - css/light.scss
- css/common.scss
# - css/syntax-light.scss
self-contained: false
embed-resources: false
self-contained-math: false
center: true
default-image-extension: svg
code-overflow: scroll
html-math-method: katex
fig-align: center
mermaid:
theme: dark
# revealjs-plugins:
# - RevealMenu
menu:
markers: true
themes:
- name: Dark
theme: css/dark.scss
highlightTheme: css/syntax-dark.scss
- name: Light
theme: css/light.scss
highlightTheme: css/syntax-light.scss
themesPath: './docs/css/'
gfm:
author: Sam Foreman
output-file: "README.md"
---
# Creating Small(-ish) LLMs[^slides-gh]
::: {layout="[ 50, 50 ]" layout-valign="center"}
::: {.col1}
[**LLM Tutorial / Workshop**]{.dim-text}
[Argonne National Laboratory]{.dim-text}
[Building 240, Room 1501]{.dim-text}
<br>
<br>
[[{{< bi person-badge >}}Sam Foreman](https://samforeman.me)]{style="font-weight: 600;"}
[2023-11-30]{.dim-text style="font-size: 0.8em;"}
- [{{< iconify line-md github-loop >}}`brettin/llm_tutorial`](https://github.com/brettin/llm_tutorial)
- [{{< iconify line-md github-loop >}}`saforem2/`](https://github.com/saforem2)
- [{{< iconify line-md github-loop >}}`nanoGPT`](https://saforem2.github.io/nanoGPT) (GitHub)
- [{{< bi easel >}} `LLM-tutorial`](https://saforem2.github.io/LLM-tutorial) (slides)
:::
::: {.col2 style="font-size: 0.6em; text-align: center;"}
::: {style="text-align: center;"}

[LLMs have taken the ~~NLP community~~ **world** by storm[^llm-animation]]{.dim-text style="font-size: 0.7em;"}
:::
::: {style="text-align:center;"}
{width="250px"}
:::
:::
:::
[^llm-animation]: [{{< iconify line-md github-loop >}}`Hannibal046/Awesome-LLM`](https://github.com/Hannibal046/Awesome-LLM)
[^slides-gh]: [{{< iconify line-md github-loop >}}`saforem2/LLM-tutorial`](https://github.com/saforem2/LLM-tutorial)
# Emergent Abilities {background-color="#FBFBFD"}
::: {width="66%" style="text-align: center;"}
<img src="https://github.com/saforem2/llm-lunch-talk/blob/main/docs/assets/emergent-abilities.gif?raw=true" height="75%" />
[Emergent abilities of Large Language Models](https://arxiv.org/abs/2206.07682) @yao2023tree
:::
# Training LLMs
::: {layout="[ 50, 40 ]" layout-valign="center"}
::: {#fig-evolution}

Visualization from @yang2023harnessing
:::
::: {}

:::
:::
# Life-Cycle of the LLM {auto-animate=true}
::: {layout="[ 45, 55 ]" layout-valign=center}
::: {#column-one}
1. Data collection + preprocessing
2. **Pre-training**
- Architecture decisions:
`{model_size, hyperparameters,`
`parallelism, lr_schedule, ...}`
3. Supervised Fine-Tuning
- Instruction Tuning
- Alignment
4. Deploy (+ monitor, re-evaluate, etc.)
:::
::: {#column-two}
::: {#fig-pretrain-two}
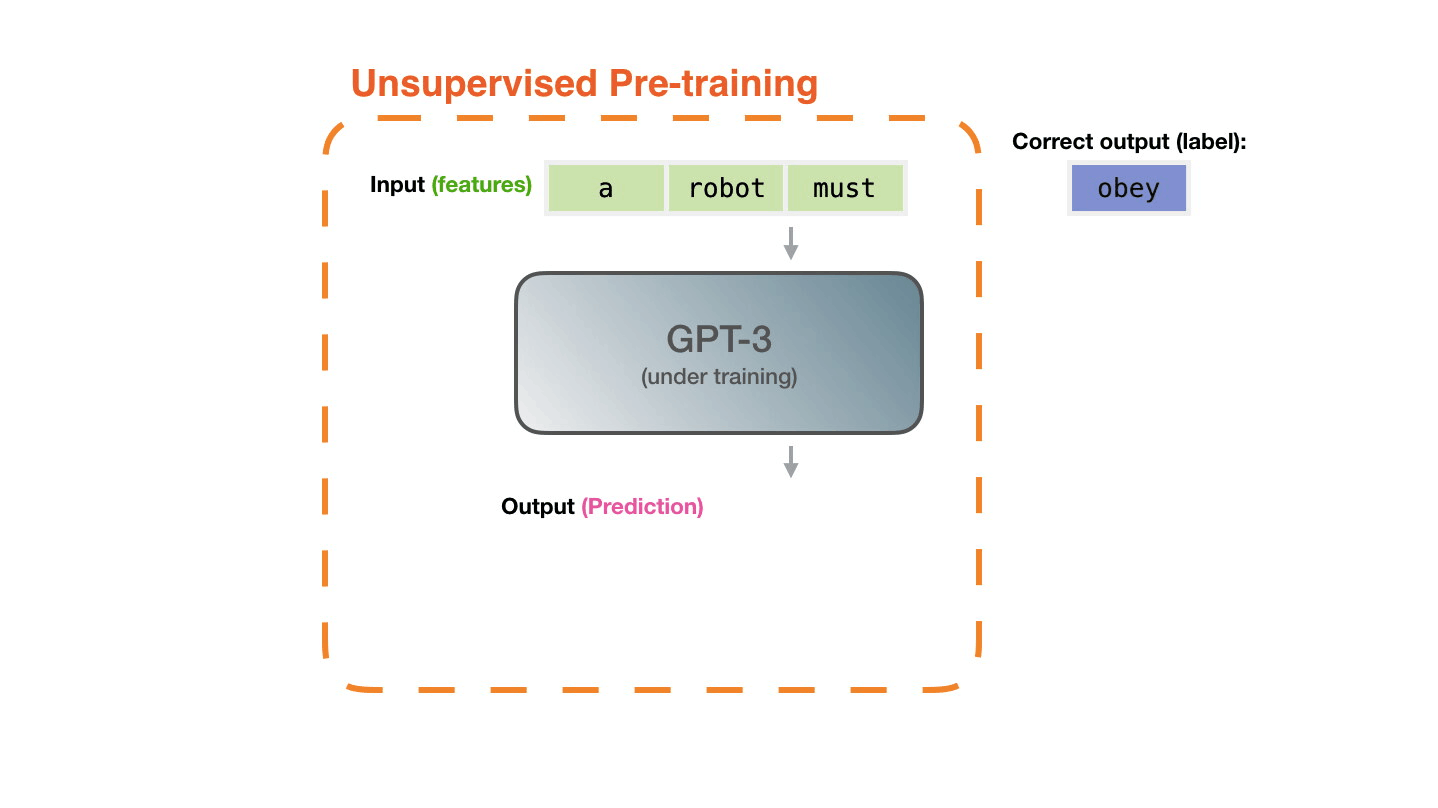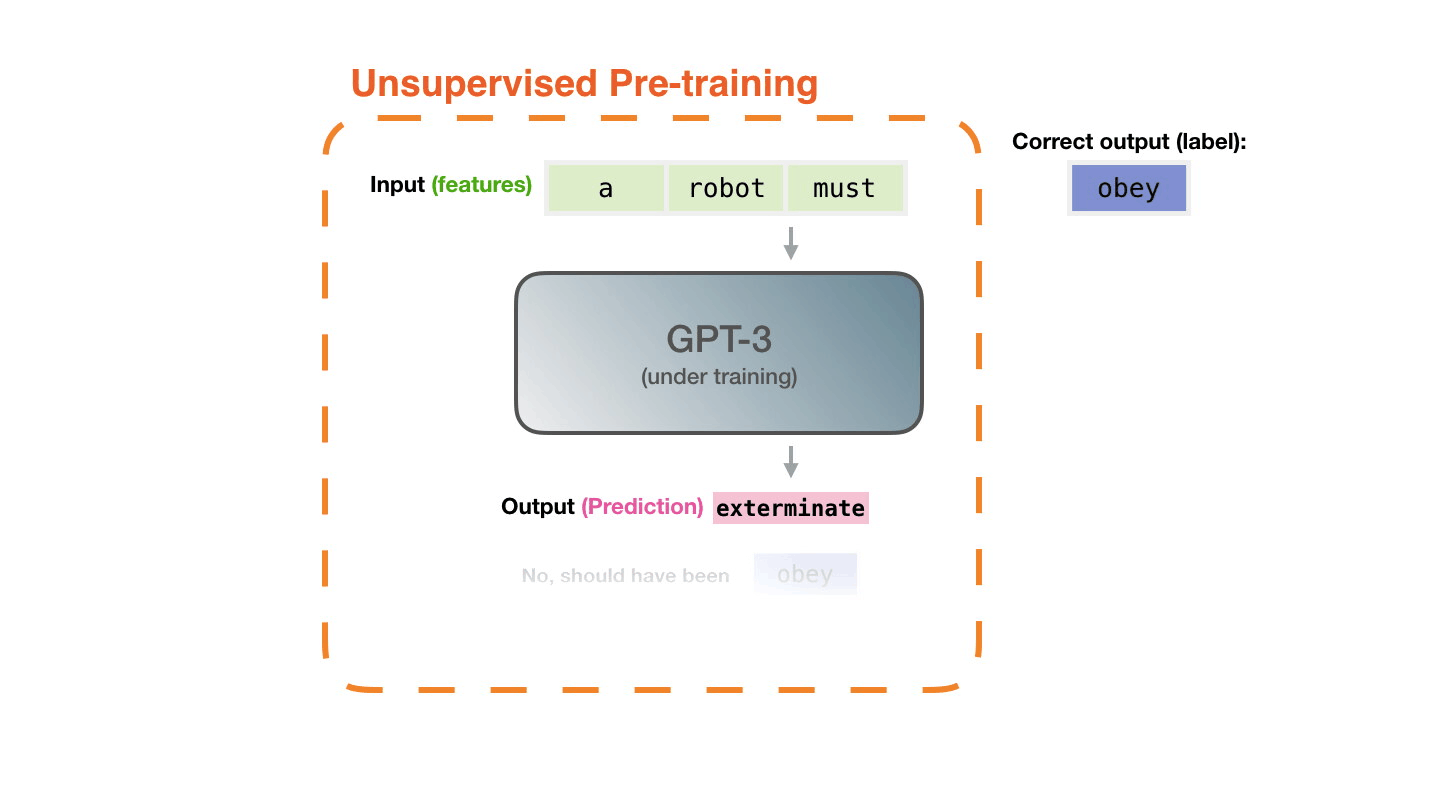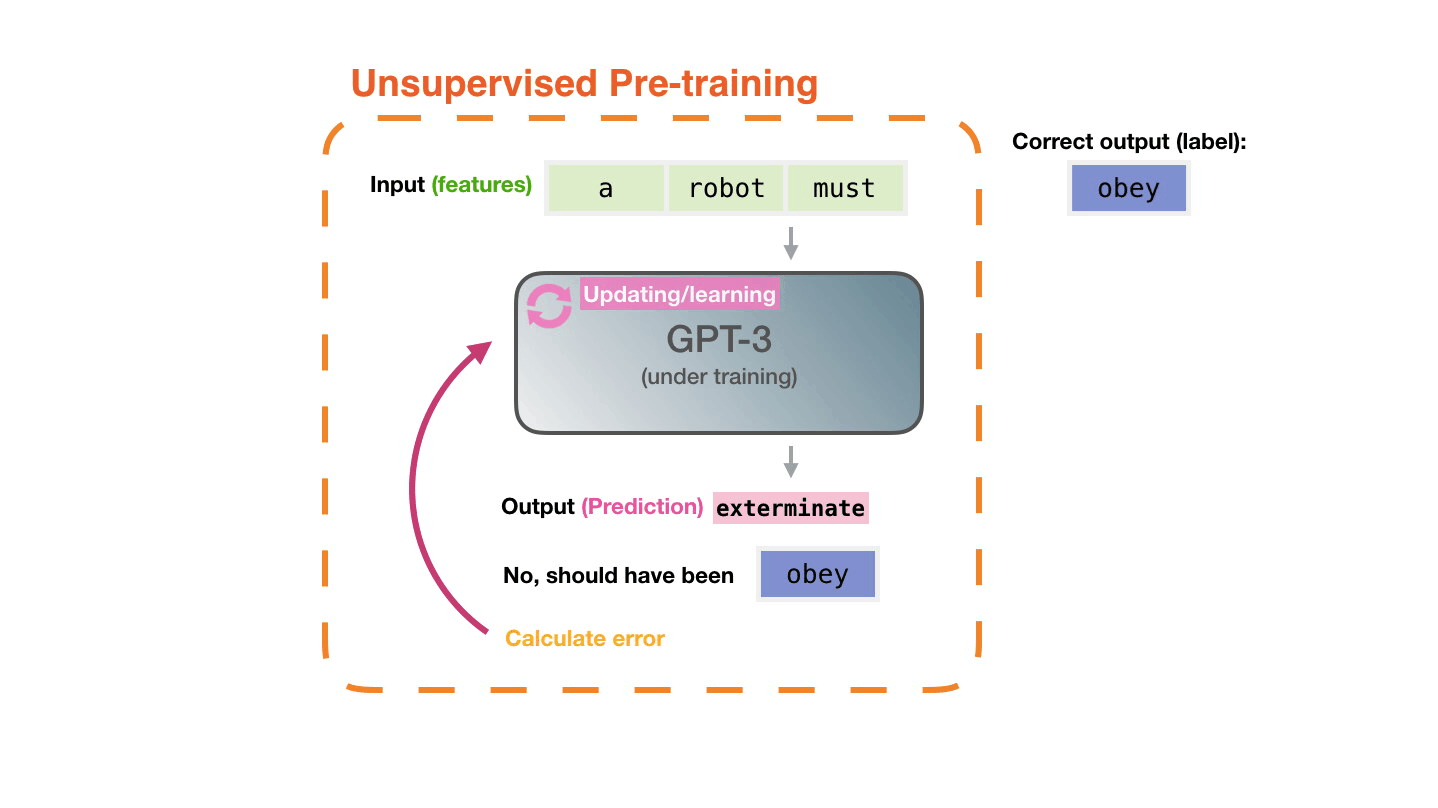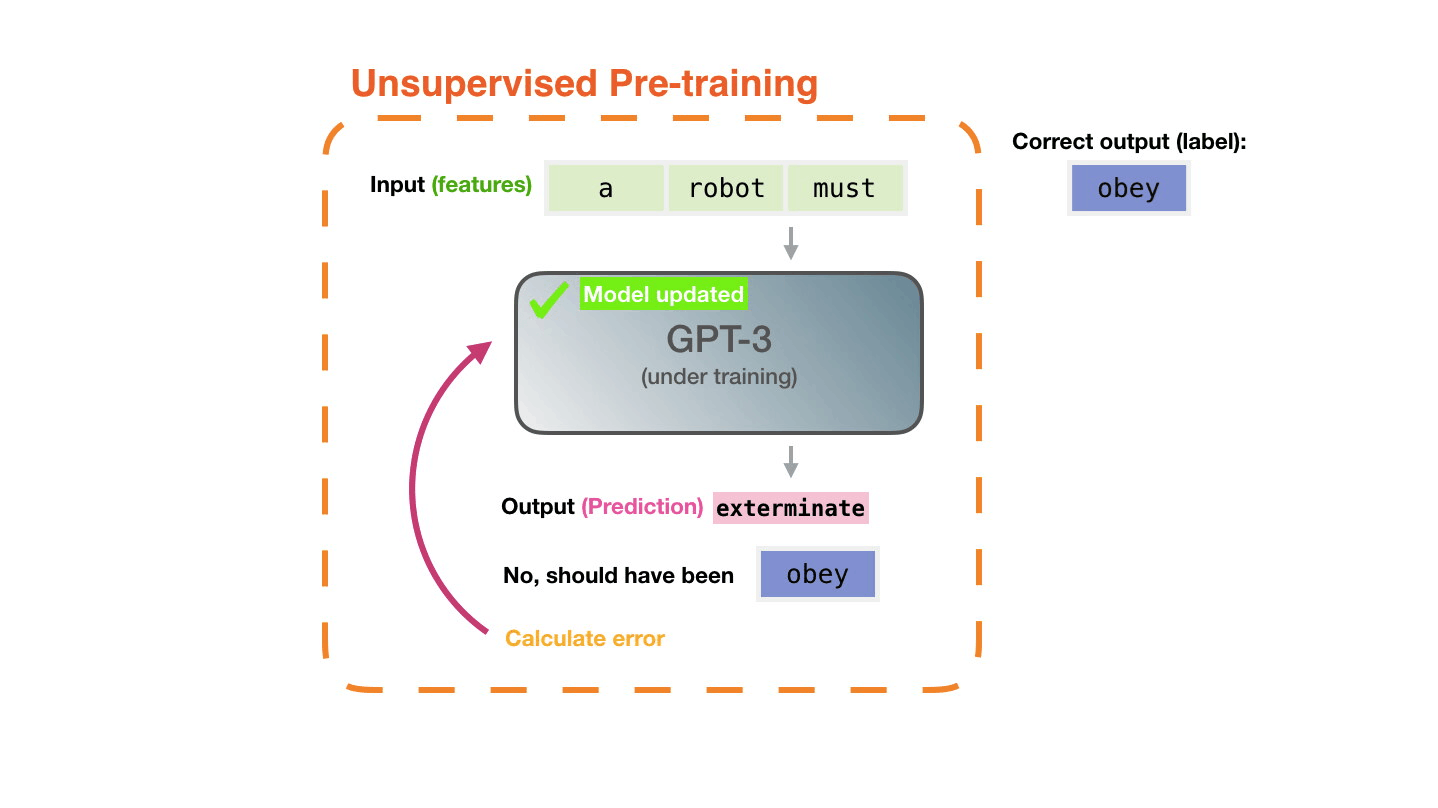
**Pre-training**: Virtually all of the compute used during pretraining phase[^il-transf].
:::
:::
[^il-transf]: Figure from [The Illustrated Transformer](http://jalammar.github.io/illustrated-transformer/)
:::
# Forward Pass
::: {#fig-forward-pass}
<video data-autoplay src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"></video>
Language Model trained for causal language modeling. Video from: [🤗 Generation with LLMs](https://huggingface.co/docs/transformers/main/en/llm_tutorial)
:::
# Generating Text
::: {#fig-generating-text}
<video data-autoplay src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"></video>
Language Model trained for causal language modeling. Video from: [🤗 Generation with LLMs](https://huggingface.co/docs/transformers/main/en/llm_tutorial)
:::
# Life-Cycle of the LLM: Pre-training {auto-animate=true}
::: {#fig-pretrain-two}

**Pre-training**: Virtually all of the compute used during pretraining phase
:::
# Life-Cycle of the LLM: Fine-Tuning {auto-animate=true style="font-size: 0.8em;"}
::: {#fig-pretrain-two}
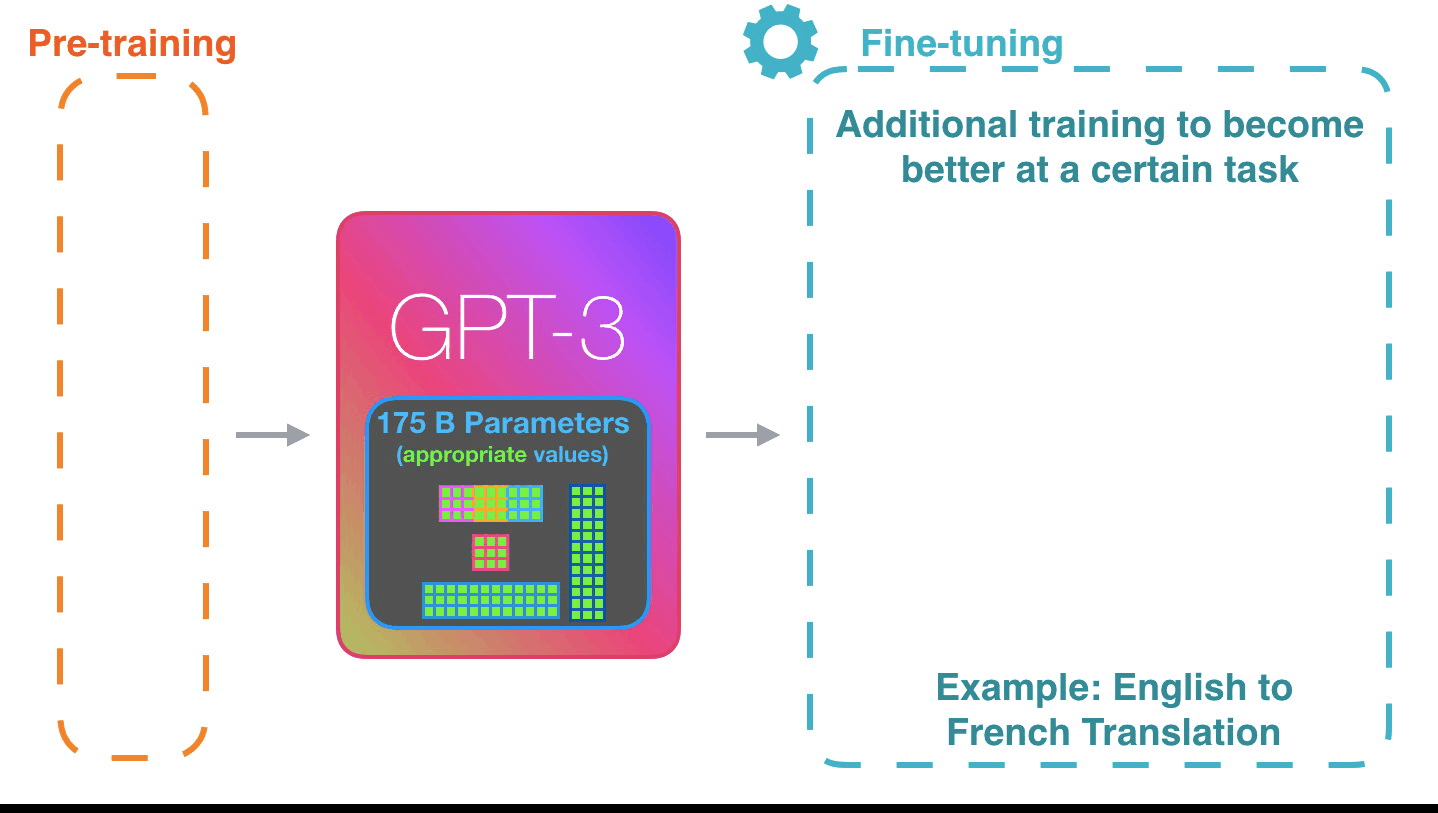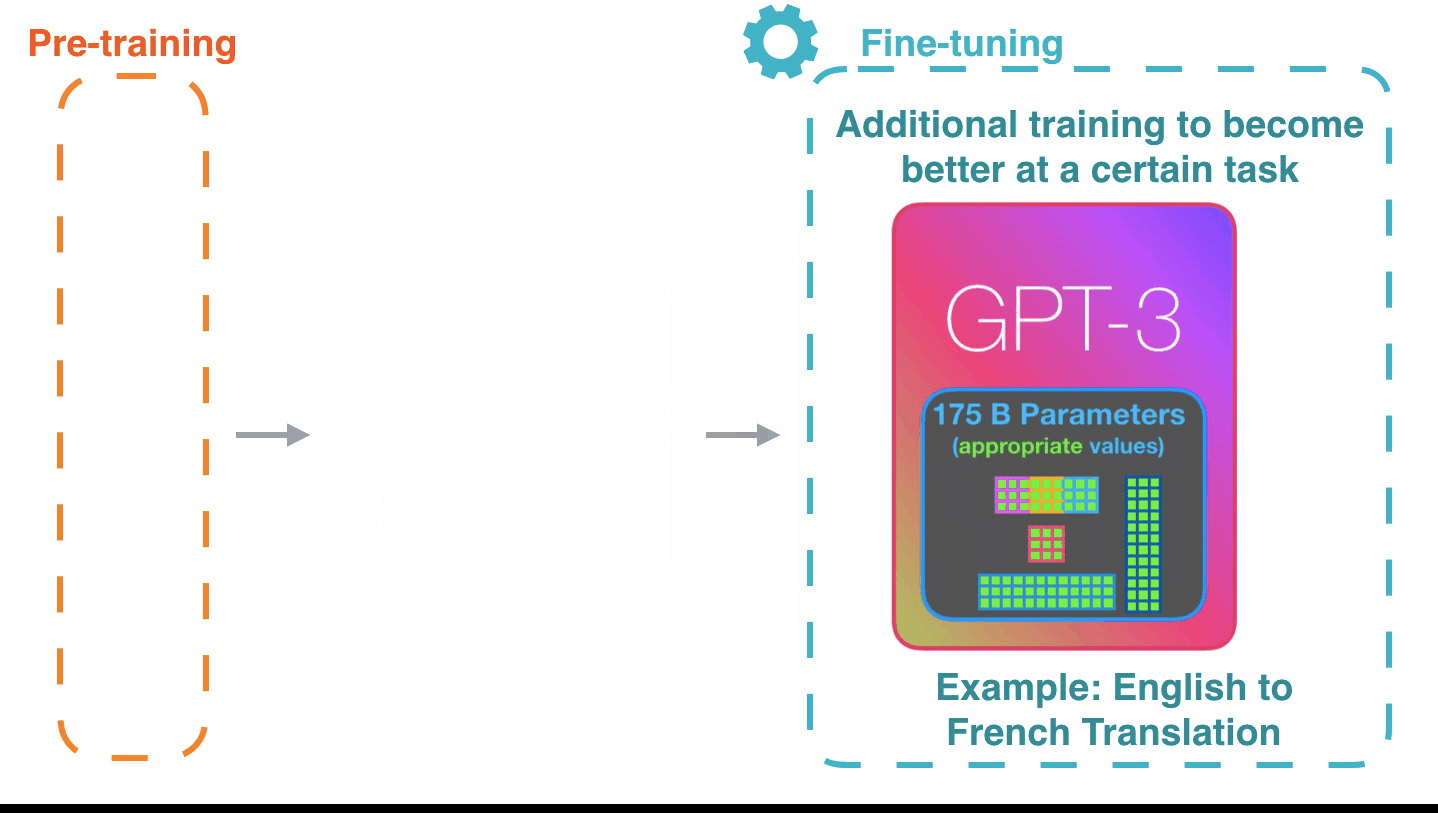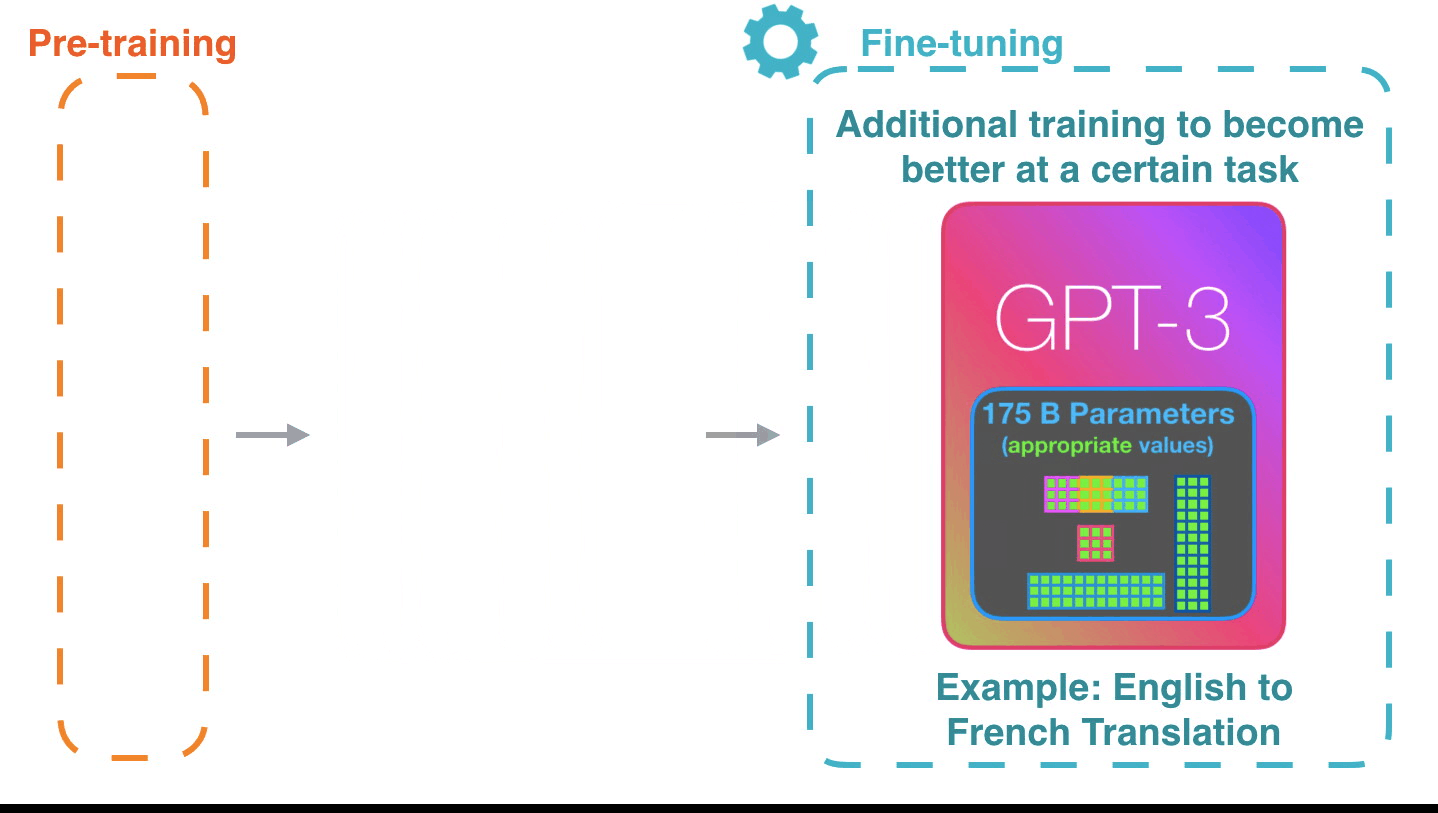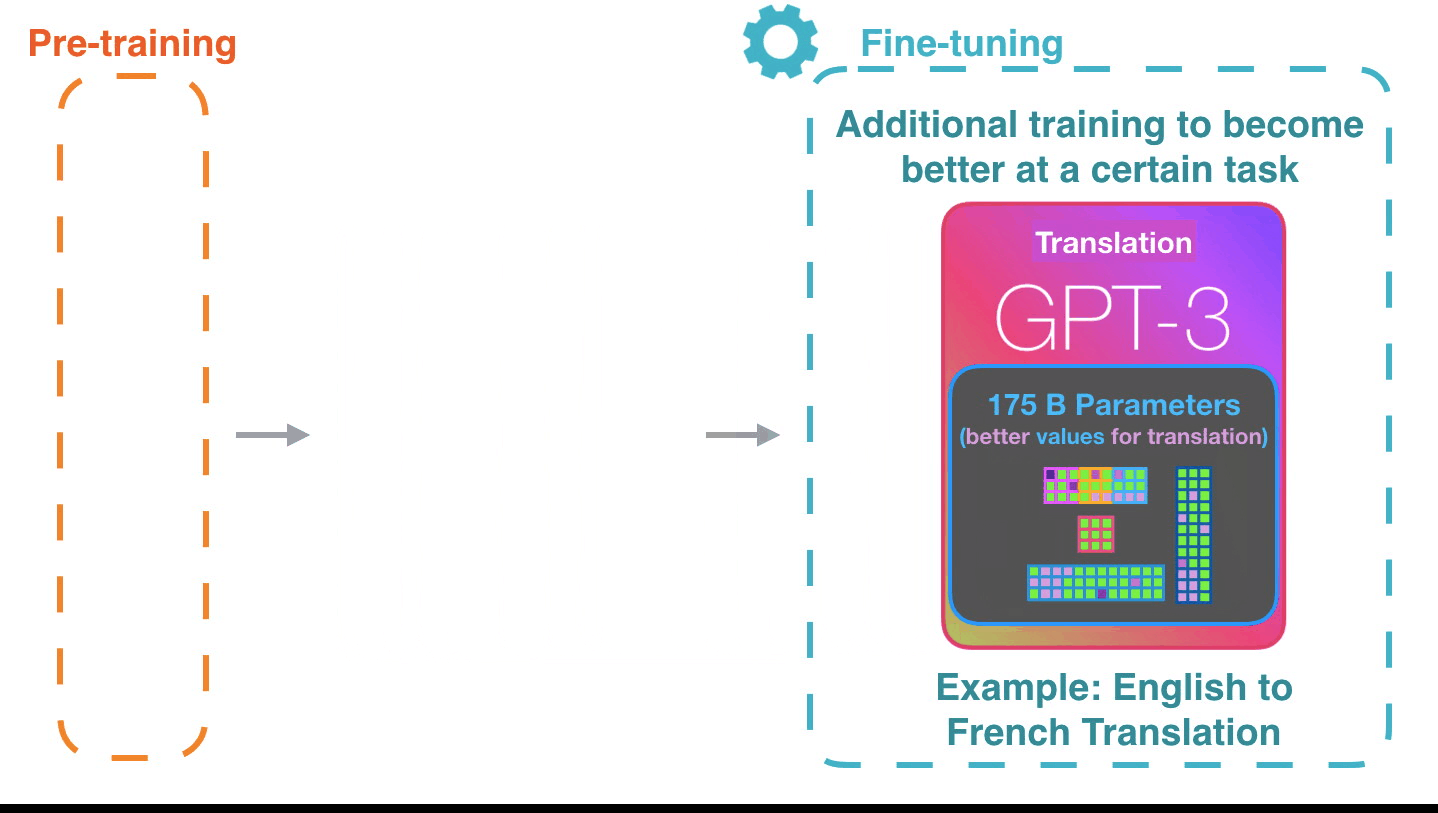
**Fine-tuning**[^ill-transf1]: Fine-tuning actually updates the model's weights to make the model better at a certain task.
:::
[^ill-transf1]: Figure from [The Illustrated Transformer](http://jalammar.github.io/illustrated-transformer/)
# Assistant Models {.centeredslide background-color="#181D29"}
[]{.preview-image style="text-align:center; margin-left:auto; margin-right: auto;"}
# [{{< iconify line-md github-loop >}}`saforem2/nanoGPT`](https://github.com/saforem2/nanoGPT)
<!-- - [{{< iconify mdi github-face >}} `saforem2/nanoGPT`](https://github.com/saforem2/nanoGPT) -->
- Fork of Andrej Karpathy's `nanoGPT`
::: {#fig-nanoGPT}

The simplest, fastest repository for training / finetuning GPT based models.
:::
# Install
```bash
git clone https://github.com/saforem2/nanoGPT
cd nanoGPT
mkdir -p venv
python3 -m venv venv --system-site-packages
source venv/bin/activate
python3 -m pip install -e .
python3 -c 'import ngpt; print(ngpt.__file__)'
# ./nanoGPT/src/ngpt/__init__.py
```
# Dependencies
- [`transformers`](https://github.com/huggingface/transformers) for
{{< iconify noto hugging-face >}} transformers (to load `GPT-2` checkpoints)
- [`datasets`](https://github.com/huggingface/datasets) for {{< iconify noto
hugging-face >}} datasets (if you want to use OpenWebText)
- [`tiktoken`](https://github.com/openai/tiktoken) for OpenAI's fast BPE code
- [`wandb`](https://wandb.ai) for optional logging
- [`tqdm`](https://github.com/tqdm/tqdm) for progress bars
# Quick Start
- We start with training a character-level GPT on the works of Shakespeare.
1. Downloading the data (~ 1MB) file
2. Convert raw text to one large stream of integers
```bash
python3 data/shakespeare_char/prepare.py
```
This will create `data/shakespeare_char/{train.bin, val.bin}`.
# [{{< iconify fa-brands github >}} `model.py`](https://github.com/saforem2/nanoGPT/blob/master/src/ngpt/model.py) {height="100%"}
<!-- ::: {style="font-size: 0.75em;"} -->
::: {.panel-tabset style="font-size: 0.75em; width: 100%!important; height: 100%!important;"}
### `GPT`
```{.python include="model.py" code-line-numbers="true" start-line=131 end-line=342}
```
### `LayerNorm`
```{.python include="model.py" code-line-numbers="true" start-line=32 end-line=40}
```
### `CausalSelfAttention`
```{.python include="model.py" code-line-numbers="true" start-line=43 end-line=98}
```
### `MLP`
```{.python include="model.py" code-line-numbers="true" start-line=100 end-line=128}
```
:::
# [{{< iconify fa-brands github >}} `trainer.py`](https://github.com/saforem2/nanoGPT/blob/master/src/ngpt/trainer.py) {height="100%"}
::: {.panel-tabset style="font-size: 0.75em; width: 100%!important; height: 100%!important;"}
### `get_batch`
```{.python include="trainer.py" code-line-numbers="true" start-line=233 end-line=258}
```
### `estimate_loss`
```{.python include="trainer.py" code-line-numbers="true" start-line=270 end-line=283}
```
### `_forward_step`
```{.python include="trainer.py" code-line-numbers="true" start-line=312 end-line=320}
```
### `_backward_step`
```{.python include="trainer.py" code-line-numbers="true" start-line=322 end-line=340}
```
### `train_step`
```{.python include="trainer.py" code-line-numbers="true" start-line=342 end-line=403}
```
:::
# Hands-on Tutorial
::: {.panel-tabset style="font-size: 0.9em; width: 100%!important; height: 100%!important;"}
#### 📒 Shakespeare
- [](https://colab.research.google.com/github/saforem2/nanoGPT/blob/master/notebooks/ngpt-shakespeare.ipynb)
- [Web Version](https://saforem2.github.io/nanoGPT/quarto/shakespeare.html)
- [`ngpt-shakespeare.ipynb`](https://github.com/saforem2/nanoGPT/blob/master/notebooks/ngpt-shakespeare.ipynb)
#### 📒 GPT-2 Small
- [](https://colab.research.google.com/github/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2-yelp.ipynb)
- [`ngpt-gpt2-yelp.ipynb`](https://github.com/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2-yelp.ipynb)
- Uses `yelp_review_full` dataset
#### 📒 GPT-2 Medium
- [](https://colab.research.google.com/github/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2.ipynb)
- [Web Version](https://saforem2.github.io/nanoGPT/quarto/gpt2-medium.html)
- [`ngpt-gpt2.ipynb`](https://github.com/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2.ipynb)
#### 📒 GPT-2 XL
- [](https://colab.research.google.com/github/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2-xl.ipynb)
- [Web Version](https://saforem2.github.io/nanoGPT/quarto/gpt2-xl.html)
- [`ngpt-gpt2-xl.ipynb`](https://github.com/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2-xl.ipynb)
#### 🔗 Links
- [📊 [Slides](https://saforem2.github.io/LLM-tutorial/#/llms-tutorial-workshop)]{style="background-color:#f8f8f8; padding: 2pt; border-radius: 6pt"}
- [🏡 [Project Website](https://saforem2.github.io/nanoGPT)]{style="background-color:#f8f8f8; padding: 2pt; border-radius: 6pt"}
- [💻 [`saforem2/nanoGPT`](https://github.com/saforem2/nanoGPT)]{style="background-color:#f8f8f8; padding: 2pt; border-radius: 6pt"}
:::
# {background-iframe="https://saforem2.github.io/nanoGPT"}
# Links
1. [{{< fa brands github >}} Hannibal046/Awesome-LLM](https://github.com/Hannibal046/Awesome-LLM/blob/main/README.md) [[](https://awesome.re)]{.inline-image}
2. [{{< fa brands github >}} Mooler0410/LLMsPracticalGuide](https://github.com/Mooler0410/LLMsPracticalGuide)
3. [Large Language Models (in 2023)](https://docs.google.com/presentation/d/1636wKStYdT_yRPbJNrf8MLKpQghuWGDmyHinHhAKeXY/edit#slide=id.g238b2698243_0_734https://docs.google.com/presentation/d/1636wKStYdT_yRPbJNrf8MLKpQghuWGDmyHinHhAKeXY/edit#slide=id.g238b2698243_0_734)
4. [The Illustrated Transformer](http://jalammar.github.io/illustrated-transformer/)
5. [Generative AI Exists because of the Transformer](https://ig.ft.com/generative-ai/)
6. [GPT in 60 Lines of Numpy](https://jaykmody.com/blog/gpt-from-scratch/)
7. [Better Language Models and their Implications](https://openai.com/research/better-language-models)
8. [{{< fa solid flask-vial >}}]{.green-text} [Progress / Artefacts / Outcomes from 🌸 Bloom BigScience](https://bigscience.notion.site/ebe3760ae1724dcc92f2e6877de0938f?v=2faf85dc00794321be14bc892539dd4f)
::: {.callout-note title="Acknowledgements"}
This research used resources of the Argonne Leadership Computing Facility,
which is a DOE Office of Science User Facility supported under Contract DE-AC02-06CH11357.
:::
# References
::: {#refs}
:::