Cloudserver memory leak #1069
Comments
|
Hi @descrepes, Thank you for your bug report! If at least one of the Zenko locations is an AWS-S3-compatible location, it might be due to a socket leak issue that we are currently fixing for the next patch release of Zenko, that can happen when connection errors/timeouts occur on the connections to the AWS-compatible backend. The leaked sockets usually retain some data in their TCP buffers, causing a memory leak as well. Not guaranteed it is the same issue that you are witnessing, but once we have the fix ready you may give it a try and see if the memory leak is resolved for you. Another idea could be to instrument the running cloudserver process with |
|
@descrepes in the meantime, if you would like to try out a provisional fix before we release a patch, you can apply the following patch to cloudserver 8.2 and re-build the image (the actual fix is in a branch in Arsenal repository, hence this is just a dependency update, and it actually also contains another fix for a cloudserver worker crash): |
|
Hi, I rebuild the image with the patch applied to 8.2 but the memory leak is still here: |

|
Hi, We upgraded to 8.2.7 and we still have the memory leak. Regards. |
|
@jonathan-gramain one important thing to note is that we are mostly using Azure Blob as backend. Regards. |
|
I can send you some nodejs profiling memories if it helps :) |
|
It is possible that there is also a memory leak in the Azure Blob backend. Please send the nodejs profiling ! |
|
Closing this as it was confirmed offline that this issue has been fixed in 1.2.2 |
Bug Report Information
Memory leak in Cloudserver since 8.1
Description
We upgraded two Zenko instances to 1.2 one month ago and we noticed a lot of cloudserver pod restarts.
It happen on both instances. One of the instance have 3 locations and 3 cloudserver pods. The other have more than 30 cloudserver pods and more than 100 locations.
Steps to Reproduce the Issue
Deploy the latest zenko chart.
Look at cloudserver restarts and grafana cloudserver dashboard.
We tested the 8.1.20 and 8.2.6.
Actual Results
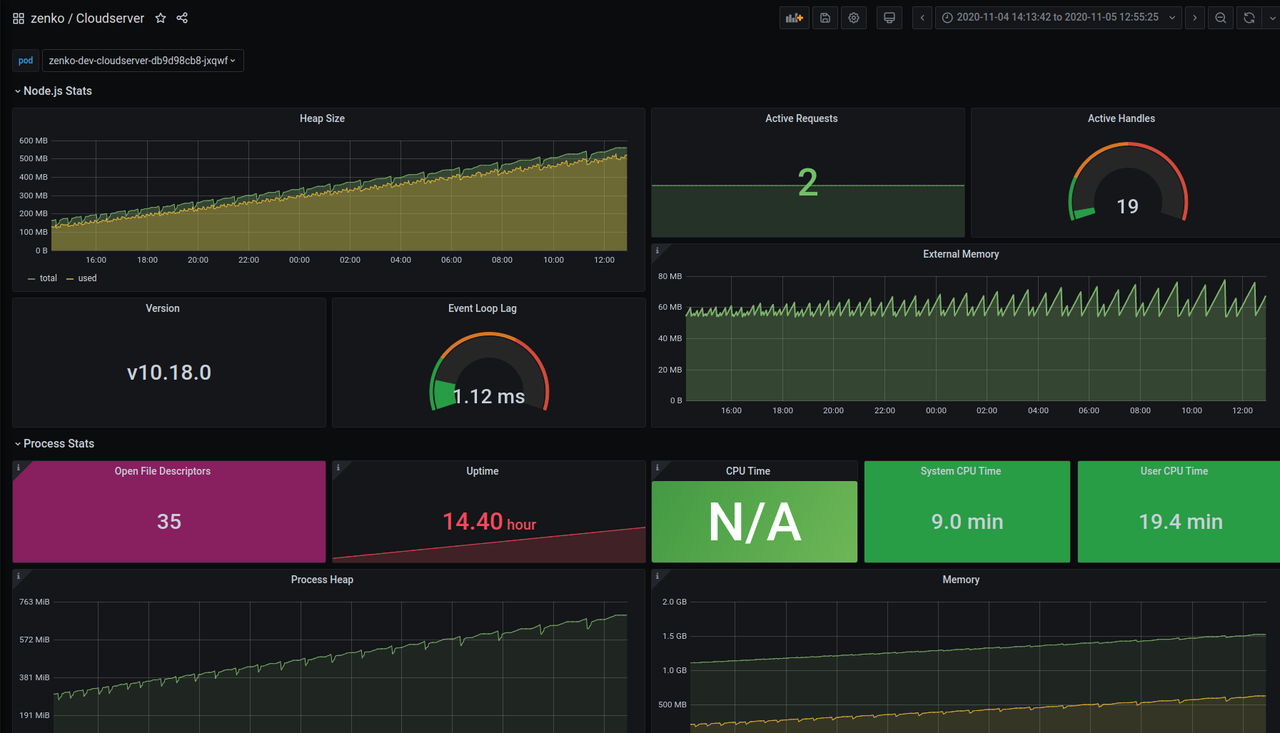
8.2.6 metrics:
8.1.20 metrics
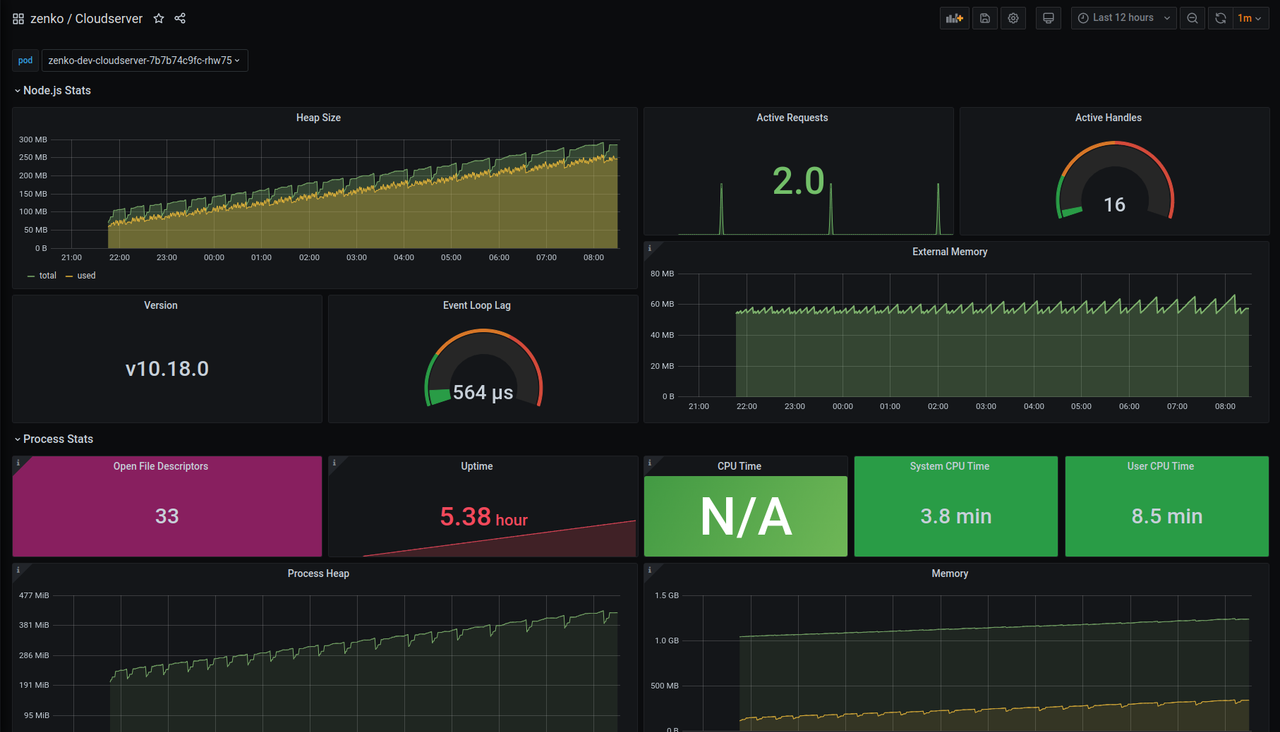
You can see on both 8.1.20 and 8.2.6 that the heap is still growing. And it end with a pod restart with a NodeJS stacktrace:
Expected Results
Like in 8.0, pods should not restart and the heap size should not grow to reach OOM.
8.0.22 metrics:

Additional Information
Let us know how your deployed example is configured. Tell us your:
we also tested the latest-8.2 docker image and observed the same symptoms as the 8.2.6 and 8.1.20.
Regards
The text was updated successfully, but these errors were encountered: