Bugfix: attribute naming consistency, drop_cols #219
Conversation
Within the scikit-learn ecosystem, it is standard practice to name the attributes like the init arguments. In this way the get_parms method can get the attributes. From sklearn version 24 onwards this is required behavior.
|
To eleborate on the issue: it is specifically concerned with the DataFrameMapper. It turned up when I embedded it in a scikit learn Pipeline. The warning can be found here: https://github.com/scikit-learn/scikit-learn/blob/0fb307bf3/sklearn/base.py#L209 |
|
<Incorrect explanation, for the real reason check the comment after this one> The test seemed to have incorrectly passed in the past as in testing the get_params method is used. As the attribute name != argument name, the get_params for drop_cols would have returned None, and the object would not have been cloned correctly. In addition, this evaluation might be why the test is failing: For the Dataframe Mapper, we give the init argument None to drop_cols. During initialization this will be set to a newly created list (drop_cols=drop_cols or [ ]). When creating the clone somethings like this must be going on; we get 'None' as input argument, as a result a new list will be created during initialization which is a different object as the list from the instance to which we are comparing too. |

|
The problem is in the following statement: drop_cols or [ ] if the columns are empty the or statement will go for the second (which is a newly created list) While if they are populated it goes for the first: (empty list evaluates to False while a populated list evaluates to True) |
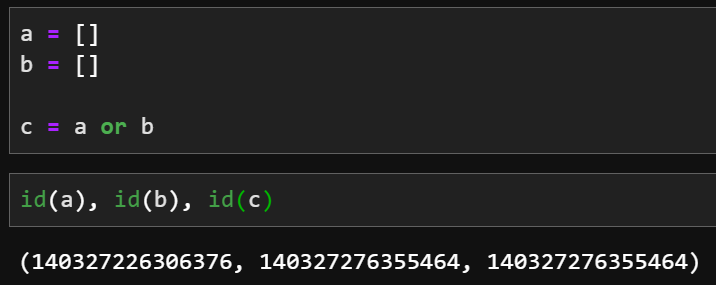

|
This fix does two things:
|
|
@VHeusinkveld thanks for changes. Please let me review it by tomorrow and get back to you. |
There was a problem hiding this comment.
Hi @VHeusinkveld
Thanks for explaining the issue and fixing it . Can you please add your name to the list of contributors and bump the version number from 2.0.1 to 2.0.2 (in sklearn_pandas/initi.py)
Regards,
Ritesh
|
@ragrawal all things should be updated now. |
Within the scikit-learn ecosystem, it is standard practice to name the attributes like the init arguments. In this way the get_parms method can get the attributes. From sklearn version 24 onwards this is required behavior.