Bug in train_test_split #22979
Comments
|
I found that when I sort the index and print it it seems to be the index from 0 - samplesize, with a few indexes missing ....
|
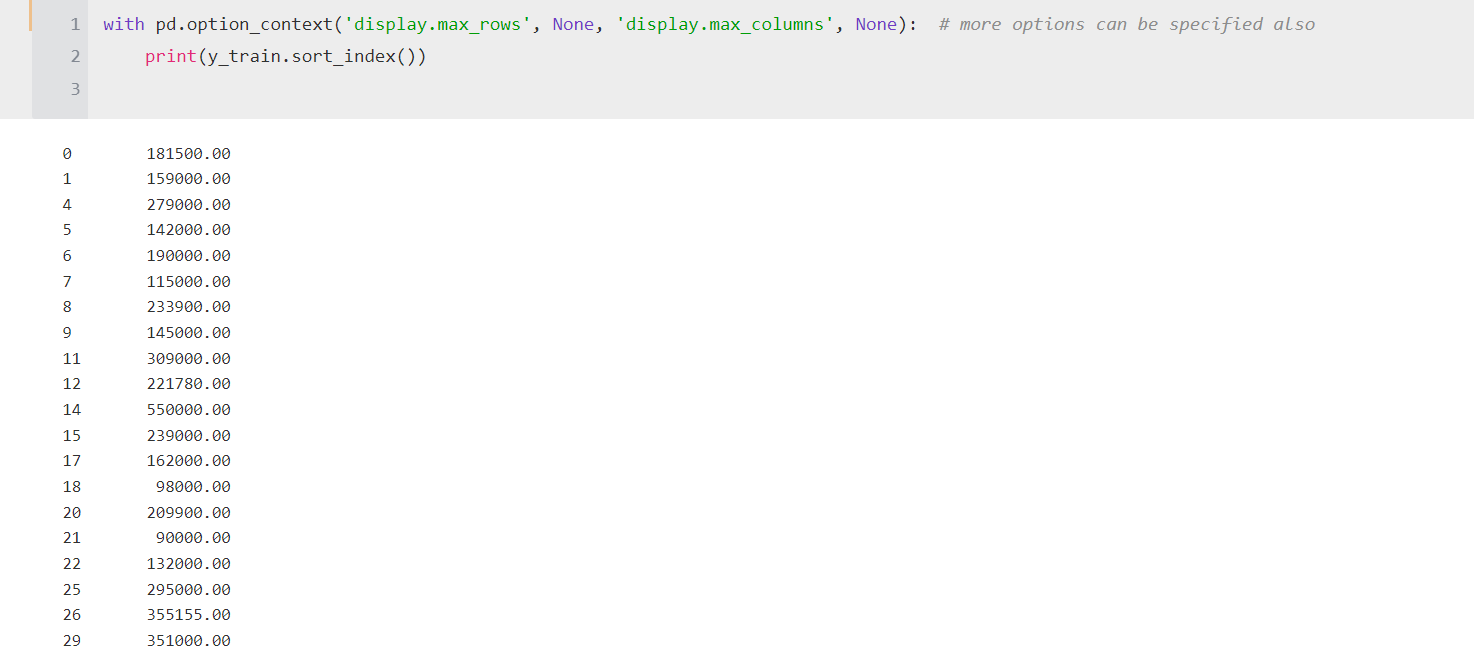
|
Thanks for the report @nilslacroix. Could you come up with a minimal reproducer that exhibits the issue you're facing (https://scikit-learn.org/dev/developers/minimal_reproducer.html#minimal-reproducer) ? |
|
Hi I tried to reproduce the error with another dataset but it works just fine with toy examples- I am really baffled here. But after train_test_split is called, y_train (and y_test as well) are reindexed beginning at 0 and randomly mixed, which
For comparison reason I wrote this reproducer, but this yields correct indeces. This is even more strange since the only difference is the dataframe, which is fed into the function. Maybe you guys have a clue why this could happen? #load dataset
from sklearn.datasets import load_diabetes
import pandas as pd
X, y = load_diabetes(return_X_y=True)
#convert to pandas, since I use pandas dataframes
X = pd.DataFrame(X)
y = pd.DataFrame(y)
#simulate my randomized dataset which is put into train_test_split
#randomize both dataframes with the same seed, so the index is in the same order
X = X.sample(frac = 1 , random_state=seed)
y = y.sample(frac = 1 , random_state=seed)
#print if index is equal before train_test_split
print(X.index.equals(y.index))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=seed)
print(X_train.index.equals(y_train.index)) |

|
This issue is hard to debug without a reproducer. If you can not share your dataset, can you write a reproducer that generates a Dataframe around the size of your dataset to reproduce your issue? |
|
Sorry just realised I wrote the same thing again. I can not reproduce the error to be honest, not with some toy df. It is also size independent because the error occasionally happens when I sample only like 100 samples from the whole dataframe. I really think this is memory related or some strange jupyter notebook bug, since it works again as soon as I restart and clear the notebook. I just do not see any other way since I compare the indeces right before and after calling the function |
|
I found the culprit. I used Intel® Extension for Scikit-learn to speed up the computation. Turns out that when I import it with this bug appears. And even others, for example I just saw that the scoring method of SVR with a poly kernel produced different scores a few seconds later with the same X, y sets , without changing the parameters. |
|
I am closing this issue because it is a |
|
Should we have a tag for issues that are due to this package rather than sklearn? |
In recent memory, I think this is the first issue related to If we really want to label this issue, there is a more generic class of issues: "upstream library". Depending on the issue, it may or may not be an issue with scikit-learn itself. |
|
As an update: This is related to sklearnex for sure. The problem is hardware related. When using AMD CPUs, the functions and class which are replaced by sklearnex (for example train_test_split and estimators) producte wrong indeces and inconsistent scores instead of giving a warning. I think thats the part that is problematic, and that it advertises such a boost in performance without telling it is a hardware dependent library. May lead to future cases of such problems. |
Describe the bug
I am pretty confident I found a bug in train_test_split. When using train_test_split multiple times in a row it produces wrong indexes in X_train and y_train.
Steps/Code to Reproduce
Using this code at the first time in Jupyter notebook produced the correct result with two identical indexes.
X_train, X_test, y_train, y_test = train_test_split(df, target, test_size=0.2, random_state=seed)I confirmed this with:
X_train.index.equals(y_train.index)After loading the dataset in the variable
dfagain and getting the target withtarget = np.log1p(df['SalePrice'])I could confirmthat
dfandtargethad the right indeces in the right order before I used the function. After the function was done X_trainand y_train had changed indeces. So there seems to be a memory related problen, since the first usage worked just fine but all tries which are done after that produce the wrong result. Clearing all output and using a reset in Jupyter notebook solves the issue for one try again.
Expected Results
Of course I would expect the right indeces.
Actual Results
This is the actual result from X_train - if you compare it the picture below you can see that the first samples of the table have been altered but the last ones remain intact.
Versions
The text was updated successfully, but these errors were encountered: