Manager repair gets many errors of: Sending repair_flush_hints_batchlog to node failed: std::runtime_error (timedout) #10004
Comments
|
@asias I am unsure what this message is |
|
The verb is about flush hints for repair based tombstone gc. We need to skip such flush if the feature is not enabled at all. |
…epair The flush of hints and batchlog are needed only for the table with tombstone_gc_mode set to repair mode. We should skip the flush if the tombstone_gc_mode is not repair mode. Fixes scylladb#10004
|
PR is sent: #10124 |
|
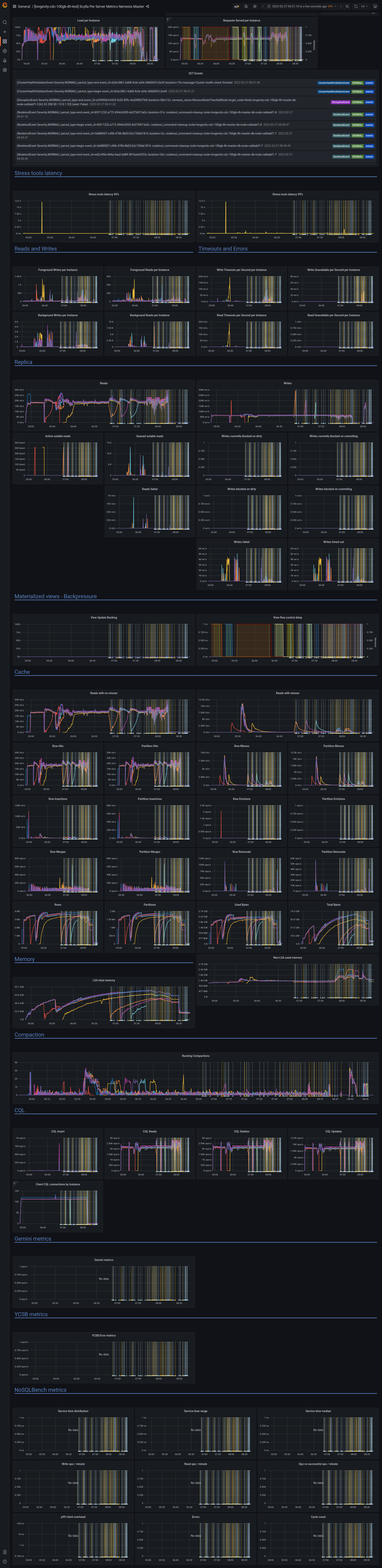
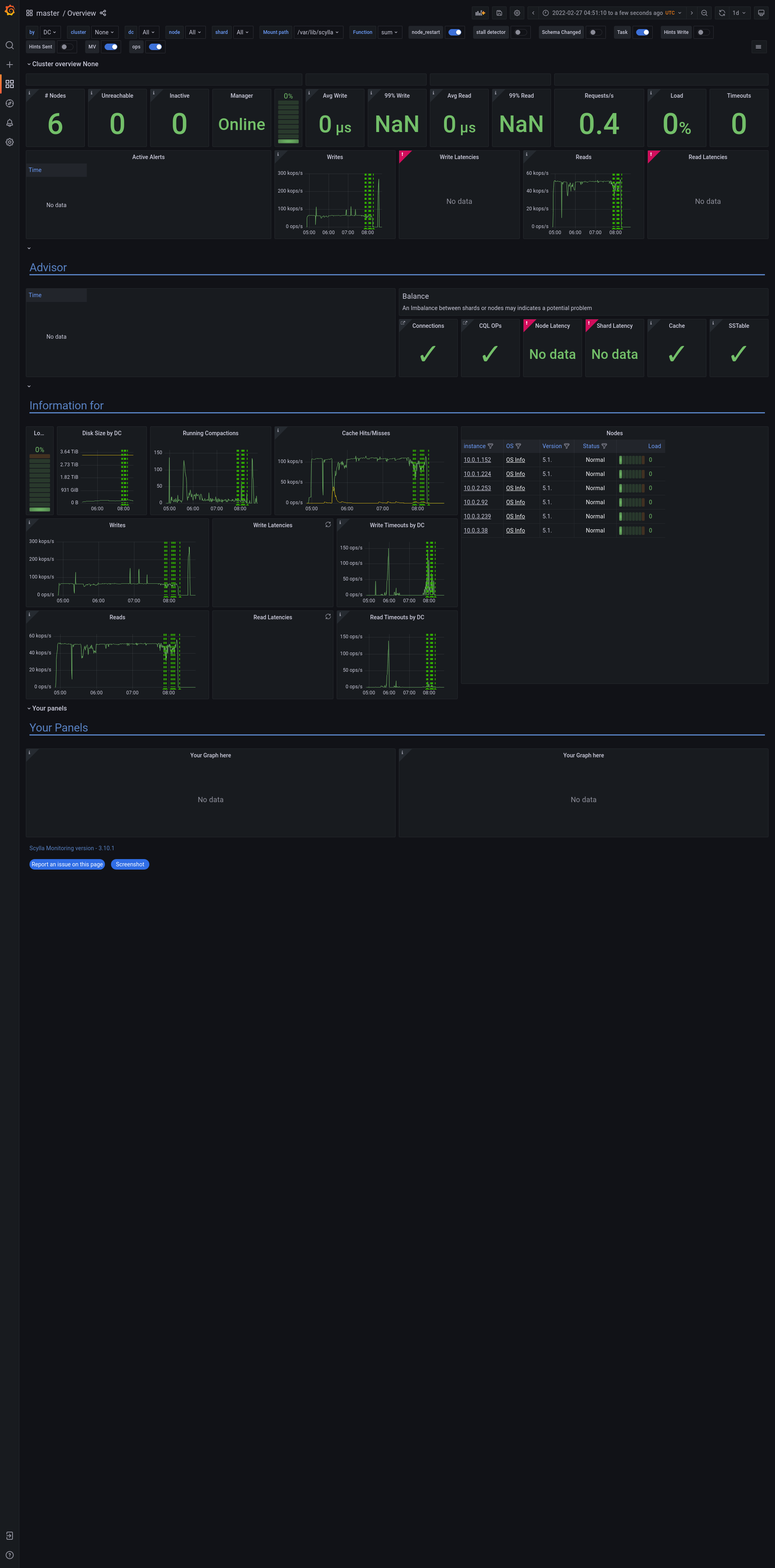
Issue reproduced during job: Test:
Issue description ==================================== ==================================== Restore Monitor Stack command: Test id: Logs: Jenkins job URL |
{kind=link}
&source=gmail-html&ust=1646123803071000&usg=AOvVaw3HqVicXLEcyfLjkgT_3ma2){kind=link}
{kind=link}
&source=gmail-html&ust=1646123803071000&usg=AOvVaw1Fgaqok4ax1gzFVbH7eK-1){kind=link}
|
Backported to 5.0. Earlier branches did not have the bug. |
Installation details
Kernel version:
5.11.0-1027-awsScylla version (or git commit hash):
5.0.dev-0.20220127.ba6c02b38 with build-id b93317e46cc252428454f96e8716b0948f28304cCluster size: 6 nodes (i3.4xlarge)
Scylla running with shards number (live nodes):
longevity-tls-50gb-3d-master-db-node-1bdb69d6-1 (54.75.41.17 | 10.0.2.245): 14 shards
longevity-tls-50gb-3d-master-db-node-1bdb69d6-4 (18.202.236.152 | 10.0.2.126): 14 shards
longevity-tls-50gb-3d-master-db-node-1bdb69d6-7 (34.255.208.176 | 10.0.2.16): 14 shards
longevity-tls-50gb-3d-master-db-node-1bdb69d6-16 (18.203.139.69 | 10.0.2.86): 14 shards
longevity-tls-50gb-3d-master-db-node-1bdb69d6-17 (54.75.56.198 | 10.0.2.236): 14 shards
longevity-tls-50gb-3d-master-db-node-1bdb69d6-18 (54.171.134.46 | 10.0.0.209): 14 shards
Scylla running with shards number (terminated nodes):
longevity-tls-50gb-3d-master-db-node-1bdb69d6-2 (34.252.164.228 | 10.0.0.69): 14 shards
OS (RHEL/CentOS/Ubuntu/AWS AMI):
ami-098e8a18da4ea000f(aws: eu-west-1)Test:
longevity-50gb-3daysTest name:
longevity_test.LongevityTest.test_custom_timeTest config file(s):
Issue description
====================================
====================================
Restore Monitor Stack command:
$ hydra investigate show-monitor 1bdb69d6-92e7-44f0-bfe2-715494307241Restore monitor on AWS instance using Jenkins job
Show all stored logs command:
$ hydra investigate show-logs 1bdb69d6-92e7-44f0-bfe2-715494307241Test id:
1bdb69d6-92e7-44f0-bfe2-715494307241Logs:
grafana - https://cloudius-jenkins-test.s3.amazonaws.com/1bdb69d6-92e7-44f0-bfe2-715494307241/20220130_154319/grafana-screenshot-overview-20220130_154322-longevity-tls-50gb-3d-master-monitor-node-1bdb69d6-1.png
db-cluster - https://cloudius-jenkins-test.s3.amazonaws.com/1bdb69d6-92e7-44f0-bfe2-715494307241/20220130_161519/db-cluster-1bdb69d6.tar.gz
monitor-set - https://cloudius-jenkins-test.s3.amazonaws.com/1bdb69d6-92e7-44f0-bfe2-715494307241/20220130_161519/monitor-set-1bdb69d6.tar.gz
Jenkins job URL
The text was updated successfully, but these errors were encountered: