Google results not working everytime #1596
Comments
|
is there a way to check if they use a new one? can you share the html file? |
|
I had to write the HTML code into a file with python like this: file = open('google.html', 'w')
file.write(resp.text)
file.close()To check if Searx received the new one or the older one. Here is the .zip of the new UI and old UI HTML files. Please disable Javascript on your browser before because Google automatically redirect to a page. |
<div class="ZINbbc xpd O9g5cc uUPGi">
<div>
<div class="jfp3ef">
<a href="/url?q=https://www.eonline.com/&sa=U&ved=...&usg=...">
<div class="BNeawe vvjwJb AP7Wnd"> E! News </div>
<div class="BNeawe UPmit AP7Wnd"> https://www.eonline.com </div>
</a>
</div>
<!-- ... -->
</div>
</div>it seem the content is actually still exist on new google ui, but the class name is obfuscated i will try if it is possible to parse starting from the url |
|
Although I tried to rebuild the docker image from latest master, I can't get any results from Google, it just doesn't work, the blue warning is displayed. Had to turn on alternative engines to get back search results. |
|
My PR isn't merged yet you will need to apply my PR as a patch. |
|
Hmm, okay, I'll give #1597 a try :) |
|
It didn't work for me :( #1597 (review) |
|
@immanuelfodor @rachmadaniHaryono |
|
It seems it was a quick fix for a bigger problem, so yes, but maybe a new issue should be created to handle the scrambled classes. I think we should be able to parse the results based on the html structure and the links, it's not the end of the world, but the |
|
I'm closing this issue, I opened a new one for that specific problem with the new UI: #1609 |
I just experienced a recent bug where Google sometimes is trying to load his new UI even if JavaScript is not activated. This make Searx not finding any results because it can't parse the new UI:

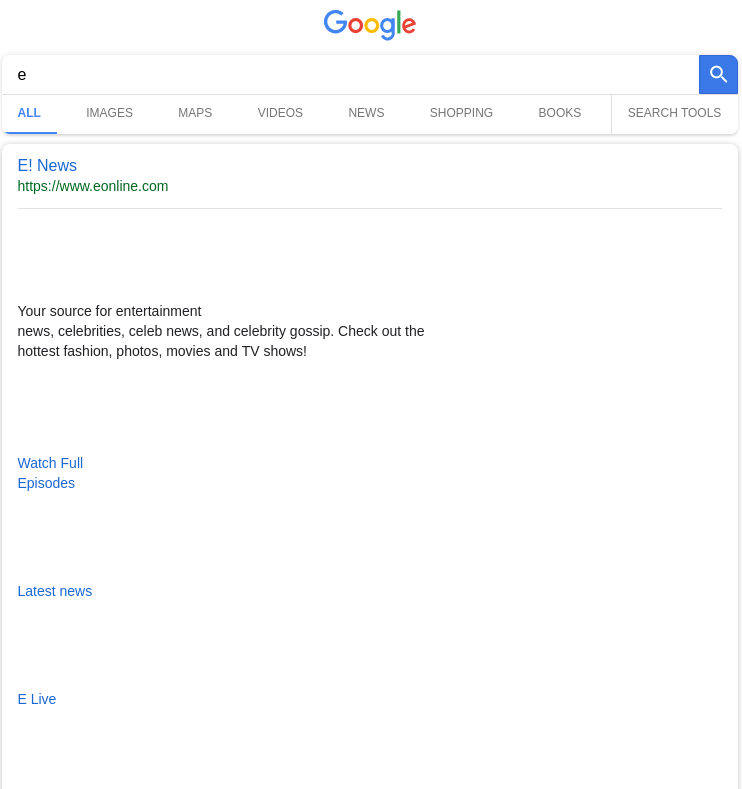

Here is the saved HTML page generated by Google when it tries reply with his new UI:
And the old UI that Searx can parse without any issue:
To resolve this bug I had the idea to force the user agent to Internet Explorer 12 by adding:
I tried that trick and it worked everytime because Google know by default that it can't load his new UI on IE.
The text was updated successfully, but these errors were encountered: