内存管理是C++最令人切齿痛恨的问题,也是C++最有争议的问题,C++高手从中获得了更好的性能,更大的自由,C++菜鸟的收获则是一遍一遍的检查代码和对C++的痛恨,但内存管理在C++中无处不在,内存泄漏几乎在每个C++程序中都会发生。
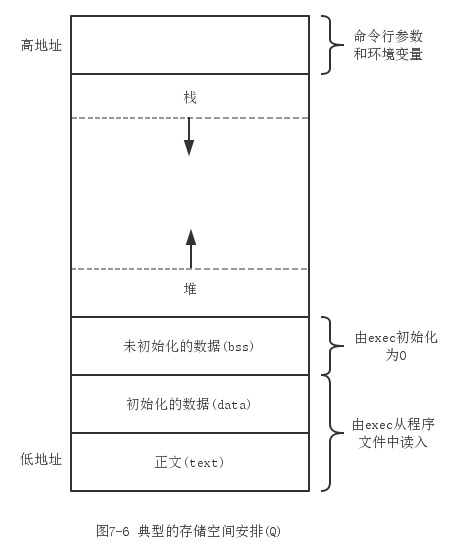
在C/C++中,进程地址空间分成5个区:
- 正文(text)段:正文段是用来存放可执行文件的操作指令,也就是说是它是可执行程序在内存中的镜像。代码段需要防止在运行时被非法修改,所以只准许读取操作,而不允许写入口处(修改)操作——它是不可写的。
DATA段(数据段):初始化数据段包含程序中明确地赋初值的变量,例如初始化后的全局变量和静态局部变量。BSS段(未初始化数据段):BSS段包含了程序中未初始化的全局变量,程序开始执行前,内核将此段中的数据初始化为0或者空指针。- 堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
- 栈:栈是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的后进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
下图显示了这些段的一种典型安排方式:
看下面例子:
void f() {
int* p=new int[5];
}
在栈内存中存放了一个指向一块堆内存的指针p。程序首先确定在堆中分配内存的大小,然后调用operator new分配内存,然后返回这块内存的首地址,放入栈中指针 p。
有时候需要一次为很多对象分配/释放内存,为此 C++ 提供了 new/delete 操作符。为了让 new 分配一个对象数组,需要在类型名后跟一对方括号,在其中指明要分配的对象的数目。
int *pia = new int[10];
typedef int arrT[10]; // arrT 表示 10 个int的数组类型
int *p = new arrT; // 分配一个 10 个 int 的数组,p指向第一个int。编译器执行时和第一句完全一样
虽然通常称new T[] 分配的内存为动态数组,但当我们用new分配一个数组时,并未得到一个数组类型的对象,而是得到一个相应元素类型的指针。由于分配的内存并不是一个数组类型,因此不能对动态数组调用 begin 或 end,也不能用范围 for 语句来处理动态数组中的元素,sizeof 的结果也和真正的数组类型的对象不同。
默认情况下,new 分配的对象,不管是单个分配的还是数组中的,都是默认初始化的。不过也可以对数组中的元素进行值初始化,方法是在大小之后跟一对空括号。
int *pia = new int[10];
int *pia2 = new int[10](0);
使用new操作符来分配对象内存时会经历三个步骤:
- 调用operator new 函数(对于数组是operator new[])分配一块足够大的,原始的,未命名的内存空间以便存储特定类型的对象。
- 编译器运行相应的构造函数以构造对象,并为其传入初值。
- 对象构造完成后,返回一个指向该对象的指针。
当我们使用一条 delete 表达式删除一个动态分配的对象时:
delete sp; // 销毁 *sp, 然后释放 sp 指向的内存空间
delete [] arr; // 销毁数组中的元素,然后释放对应的内存空间
实际上执行了两步操作:
- 对 sp 所指的对象或者 arr 所指的数组中的元素执行对应的析构函数。
- 编译器调用标准库operator delete(或operator delete[])函数释放内存空间。
数组中的元素按逆序销毁,即最后一个元素首先被销毁,然后是倒数第二个,依次类推。当释放一个指向数组的指针时,空方括号对是必需的:它指示编译器此指针指向一个对象数组的第一个元素。如果在 delete 一个指向数组的指针时忽略了方括号,或者在 delete 一个指向单一对象的指针时使用了方括号,其行为是未定义的。
[内存管理错误代码]
[delete 内存泄漏]
void *malloc(long NumBytes) 分配 NumBytes 个字节,并返回了指向这块内存的首指针。如果分配失败,则返回一个空指针(NULL)。分配失败的原因有多种,比如说空间不足就是一种。malloc() 是从堆里面分配空间,也就是说函数返回的指针是指向堆里面的一块内存。操作系统中有一个记录空闲内存地址的链表。当操作系统收到程序的申请时,就会遍历该链表,然后就寻找第一个空间大于所申请空间的堆结点,然后就将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
malloc()分配的存储空间比所要求的要稍大一些,额外的空间用来记录管理信息——分配块的长度,分配块是否已经可用(free 掉)。用结构体来记录管理信息,如下:
struct mem_control_block {
int is_available; //该块是否可用;
int size; //该块可用空间的大小
};
void free(void *FirstByte) 将之前用malloc分配的空间还给程序或者是操作系统,也就是释放了这块内存,让它重新得到自由。free()释放的是指针指向的内存!指针并没有被释放,指针仍然指向原来的存储空间。指针是一个变量,只有程序结束时才被销毁。释放了内存空间后,原来指向这块空间的指针还是存在!只不过现在指针指向的内容是未定义的,因此,释放内存后最好把指针指向NULL,防止后面不小心又解引用该指针了。
free()函数非常简单,只有一个参数,只要把指向申请空间的指针传递给free()即可。这是因为 free 是根据结构体 mem_control_block 的信息来释放malloc()申请的空间。
void free(void *ptr)
{
struct mem_control_block *free;
free = ptr - sizeof(struct mem_control_block);
free->is_available = 1;
return;
}
malloc 的一个具体使用例子在 gist 上。
- new/delete是C++操作符,malloc/free是C/C++函数。
- 使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算,而malloc则需要显式地指出所需内存的大小。
- new/delete会调用对象的构造函数/析构函数以完成对象的构造/析构,而malloc只负责分配空间。
- new 操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void * ,需要通过强制类型转换将 void* 指针转换成我们需要的类型。
- 效率上:malloc的效率高一点,因为只分配了空间。
- operator new /operator delete 可以被重载,而 malloc/free 并不允许重载。
常见内存错误以及解决办法:
- 内存分配未成功,却使用了它。(在使用内存之前检查指针是否为NULL。如果指针p是函数的参数,那么在函数的入口处用
assert(p!=NULL)进行检查。如果是用malloc或new来申请内存,应该用if(p==NULL)或if(p!=NULL)进行防错处理。) - 内存分配虽然成功,但是尚未初始化就引用它。(无论用何种方式创建数组,都应该初始化)
- 内存分配成功并且已经初始化,但操作越过了内存的边界。例如在使用数组时经常发生下标“多1”或者“少1”的操作。特别是在for循环语句中,循环次数很容易搞错,导致数组操作越界。
- 忘记了释放内存,造成内存泄露。动态内存的申请与释放必须配对,程序中malloc与free的使用次数一定要相同,否则肯定有错误(new/delete)。
- 释放了内存却继续使用它。
缓冲区是一块可读写的连续的计算机内存区域,高级语言定义的变量、数组、结构体等在运行时可以说都是保存在缓冲区内的。除了代码段和受操作系统保护的数据区域,其他的内存区域都可以作为缓冲区,因此缓冲区溢出的位置可能在.Data 和 .BSS段,也可能在堆、栈段。
- .Data段和.BSS段存储了用户程序的全局变量,静态变量等;
- 栈空间存储了用户程序的
函数栈帧(包括参数、局部数据等),用来实现函数调用机制。 - 堆空间存储了程序运行时动态申请的内存数据等。
在C/C++语言中,通常使用字符数组和malloc/new内存分配函数来分配缓冲区。使用这些缓冲区时,理想的情况是程序检查数据长度,不允许输入超过缓冲区长度的字符。但是绝大多数程序并不会保证数据长度总是与所分配的缓冲区空间相匹配,这就会导致缓冲区溢出问题。
栈的主要功能是实现函数的调用,在介绍栈溢出原理之前,需要弄清函数调用时栈空间发生了怎样的变化。每次函数调用时,系统会把函数的返回地址(函数调用指令后紧跟指令的地址),一些关键的寄存器值保存在栈内,函数的实际参数和局部变量(包括数据、结构体、对象等)也会保存在栈内。这些数据统称为函数调用的栈帧,而且每次函数调用都会有个独立的栈帧,这也为递归函数的实现提供了可能。
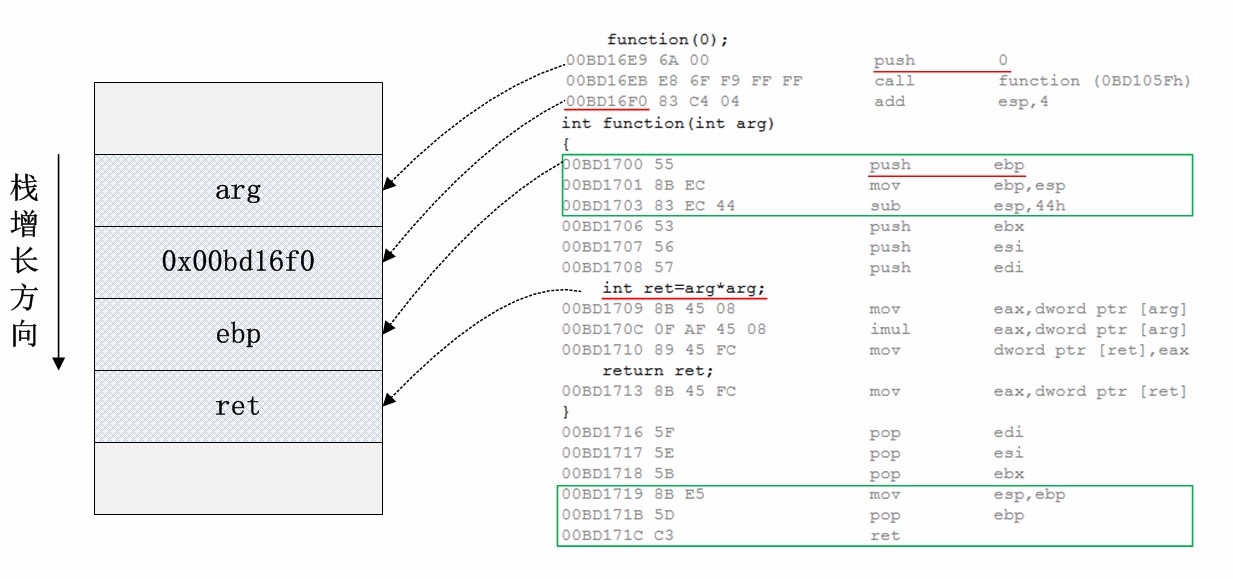
如图所示,定义了一个简单的函数function,它接受一个整形参数,做一次乘法操作并返回。当调用function(0)时,arg参数记录了值0入栈,并将call function指令下一条指令的地址0x00bd16f0保存到栈内,然后跳转到function函数内部执行。每个函数定义都会有函数头和函数尾代码,如图绿框表示。因为函数内需要用ebp寄存器保存函数栈帧基址,因此先保存ebp原来的值到栈内,然后将栈指针esp内容保存到ebp。函数返回前需要做相反的操作——将esp指针恢复,并弹出ebp。
之所以会有缓冲区溢出的可能,主要是因为栈空间内保存了函数的返回地址。该地址保存了函数调用结束后后续执行的指令的位置,对于计算机安全来说,该信息是很敏感的。如果有人恶意修改了这个返回地址,并使该返回地址指向了一个新的代码位置,程序便能从其它位置继续执行。也就是说攻击者可以利用缓冲区溢出来窜改进程运行时栈,从而改变程序正常流向,轻则导致程序崩溃,重则系统特权被窃取。
从根本上讲,在程序将数据读入或复制到缓冲区中的任何时候,它需要在复制之前检查是否有足够的空间。遗憾的是,C 和 C++ 附带的大量危险函数(或普遍使用的库)无法做到这点。程序对这些函数的任何使用都是一个警告信号,因为除非慎重地使用它们,否则它们就会成为程序缺陷。
比如在使用不安全的strcpy库函数时,系统会盲目地将data的全部数据拷贝到buffer指向的内存区域。buffer的长度是有限的,一旦data的数据长度超过BUF_LEN,便会产生缓冲区溢出。如下图所示:
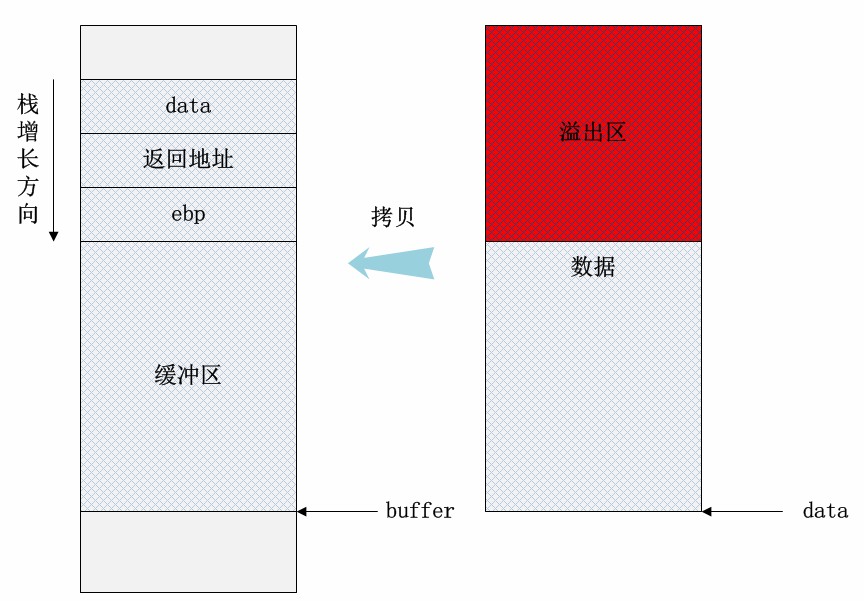
由于栈是低地址方向增长的,因此局部数组buffer的指针在缓冲区的下方。当把data的数据拷贝到buffer内时,超过缓冲区区域的高地址部分数据会“淹没”原本的其他栈帧数据,根据淹没数据的内容不同,可能会有产生以下情况:
- 淹没了其他的局部变量。如果被淹没的局部变量是条件变量,那么可能会改变函数原本的执行流程。这种方式可以用于破解简单的软件验证。
- 淹没了ebp的值。修改了函数执行结束后要恢复的栈指针,将会导致栈帧失去平衡。
- 淹没了返回地址。这是栈溢出原理的核心所在,通过淹没的方式修改函数的返回地址,使程序代码执行“意外”的流程!
- 淹没参数变量。修改函数的参数变量也可能改变当前函数的执行结果和流程。
- 淹没上级函数的栈帧,情况与上述4点类似,只不过影响的是上级函数的执行。当然这里的前提是保证函数能正常返回,即函数地址不能被随意修改。
如果在data本身的数据内就保存了一系列的指令的二进制代码,一旦栈溢出修改了函数的返回地址,并将该地址指向这段二进制代码的真实位置,那么就完成了基本的溢出攻击行为。
内存泄漏指由于疏忽或错误造成程序未能释放已经不再使用的内存的情况。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
内存泄漏是最难发现的常见错误之一,因为除非用完内存或调用malloc失败,否则都不会导致任何问题。实际上,使用C/C++这类没有垃圾回收机制的语言时,很多时间都花在处理如何正确释放内存上。如果程序运行时间足够长,如后台进程运行在服务器上,只要服务器不宕机就一直运行,一个小小的失误也会对程序造成重大的影响,如造成某些关键服务失败。
C++中的内存泄露一般指堆中的内存泄露。堆内存是我们手动malloc/realloc/new申请的,程序不会自动回收,需要调用free或delete手动释放,否则就会造成内存泄露。内存泄露常见的原因大概有以下几种:
- “无主”内存:申请内存后,指针指向内存的起始地址,若丢失或修改这个指针,那么申请的内存将丢失且没法释放。
- 异常分支导致资源未释放:程序正常执行没有问题,但是如果遇到异常,正常执行的顺序或分支会被打断,得不到执行。所以在异常处理的代码中,要确保系统资源的释放。
- 类的析构函数为非虚函数:析构函数为虚函数,利用多态来调用指针指向对象的析构函数,而不是基类的析构函数。
下面来看一个简单的内存泄漏示例代码:
void f(void) {
int *x = (int *)malloc(5 * sizeof(int));
int *y = new int[5];
// free(x);
// delete []y;
// x = NULL;
// y = NULL;
} // problem here: memory leak -- x, y not freed
int main(void) {
f();
return 0;
}内存泄露检测的关键在于记录分配内存和释放内存的操作,看看能不能匹配。跟踪每一块内存的声明周期,例如:每当申请一块内存后,把指向它的指针加入到List中,当释放时,再把对应的指针从List中删除,到程序最后检查List就可以知道有没有内存泄露了。
在一般的linux发行版中,有一个自带的工具可以很方便的替你完成这些事,这个工具就是mtrace。mtrace为内存分配、释放函数(malloc, realloc, memalign, free)安装hook函数,这些hook函数记录内存申请和释放的trace信息。
不过还有一款强大的检测工具 Valgrind,它是运行在Linux上一套基于仿真技术的程序调试和分析工具,包含一个内核——一个软件合成的CPU,和一系列的小工具,每个工具都可以完成一项任务──调试,分析,或测试等,其中Memcheck 工具可以用来方便的检测内存泄漏。
可以用下面命令检测程序是否发生内存泄漏:
$ valgrind --leak-check=yes ./demo.o对于下面的程序来说
#include <iostream>
using namespace std;
struct Node {
int val;
Node *next;
};
Node* still_reachable;
Node* possible_lost;
void show(){
Node *tmp = new Node; // definitely_lost
tmp->next = new Node; // indirectly_lost
}
int main()
{
show();
still_reachable = new Node;
possible_lost = new Node[2] + 1;
}一共有四种类型的内存泄漏(关于这四种泄漏类型的详细内容,参考 Memory leak detection):
==45310== LEAK SUMMARY:
==45310== definitely lost: 16 bytes in 1 blocks
==45310== indirectly lost: 16 bytes in 1 blocks
==45310== possibly lost: 2,096 bytes in 2 blocks
==45310== still reachable: 16 bytes in 1 blocks
==45310== suppressed: 20,125 bytes in 189 blocks
==45310== Reachable blocks (those to which a pointer was found) are not shown.细说new与malloc的10点区别
Where are static variables stored (in C/C++)?
Memory management in C: The heap and the stack
缓冲区溢出详解
缓冲区溢出攻击
C/C++内存泄漏及检测
Doc: Valgrind:Memory leak detection
用valgrind检查C++程序的内存泄漏
C Function Call Conventions and the Stack