{kind=link}
Original PyTorch implementation for 'Syntactically Guided Generative Embeddings For Zero Shot Skeleton Action Recognition' , accepted at 'IEEE International Conference on Image Processing (ICIP) 2021'
TL;DR version of the work: HERE

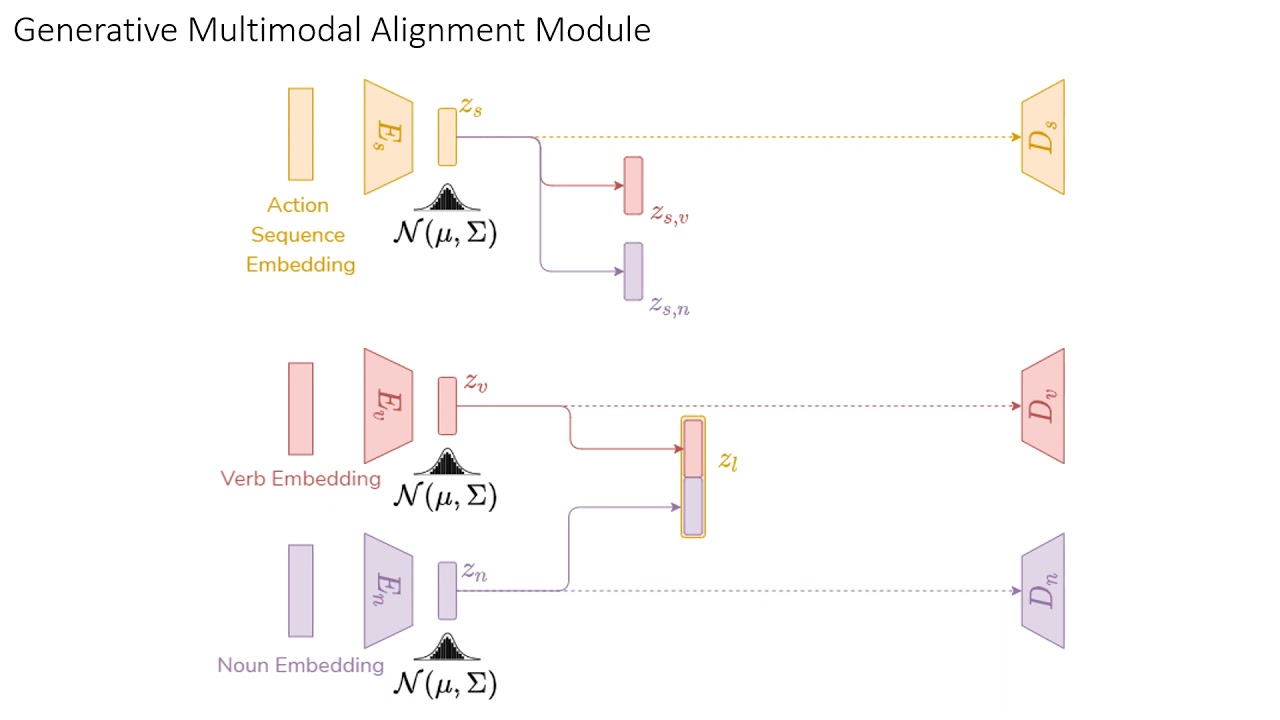
|
| Video Overview(Click on Image above) |
|---|
- Python >= 3.5
- Torch == 1.2.0
- Scikit-Learn
The unseen classes of the various splits are listed below. These splits are also provided under the synse_resources/resources/label_splits, which can be downloaded from here. Place the resources folder in the root synse-zsl directory. Random unseen 5 classes can be found in the ru5.npy file. This naming scheme is used for all splits. R-random, S-seen, U-unseen, V-validation split.
| A11 reading | A12 writing | A20 put on a hat/cap | A27 jump up | A57 touch pocket |
| A4 brush hair | A6 pick up | A10 clapping | A13 tear up paper | A16 put on shoe |
| A41 sneeze or cough | A43 falling down | A48 nausea or vomiting | A52 pushing | A57 touch pocket |
| A59 walking towards | A60 walking apart |
| A5 drop | A14 put on jacket | A38 salute | A44 headache | A50 punch or slap |
| A66 juggle table tennis table | A89 put object into bag | A96 cross arms | A100 butt kicks | A107 wield knife |
| A6 pick up | A10 clapping | A12 writing | A17 take off shoe | A19 take off glasses |
| A21 take off hat or cap | A23 hand waving | A30 type on keyboard | A36 shake head | A40 cross hands in front |
| A46 back pain | A50 punch or slap | A60 walking apart | A69 thumb up | A71 make ok sign |
| A82 fold paper | A85 apply cream on face | A88 take off bag | A94 throw up cap or hat | A95 capitulate |
| A105 blow nose | A114 carry object | A115 take photo | A120 rock paper scissors |
We provide the visual features generated via SHIFT-GCN for the NTU-120 and NTU-60 dataset for the various splits. They can be found under the synse_resources/ntu_results repository, which is downloadable from here. train.npy contains the visual features of the training data from the seen classes. ztest.npy contains the test data from the unseen classes. gtest.npy contains the test data from all the classes.
If you wish to generate the visual features yourself:
- Download the NTU-60 and NTU-120 datasets by requesting them from here.
- Create the test-train-val splits for the datasets using the split file created in the previous steps.
- Train the visual feature generator. Follow this for training Shift-GCN. For each split a new feature generator has to be trained following the zero shot learning assumption. The trained Shift-GCN weights can be found under the repository.
synse_resources/ntu_results/shift_5_r/weights/ - Save the features for train data, unseen test data(zsl) and the entire test data(gzsl).
We provide the generated language features as well, for the labels in NTU-60, and NTU-120 dataset. They can be found in ./synse_resources/resources/. Place the resources folder in the root synse-zsl directory.
If you wish to generate the language features yourself.
- Word2Vec: Download the Pre-Trained Word2Vec Vectors and extract the contents of the archive. Generate the Word2Vec representations by using the gensim python module as described here
- For Sentence-BERT, we use the sentence-transformers package from here. We use the stsb-bert-large model.
We provide the scripts necessary to obtain the results shown in the paper. They include training and evaluation scripts for ReViSE [1], JPoSE[2], CADA-VAE[3] and our model SynSE.
The scripts for each of the three models are present in their respective folders (jpose, revise, synse).
A README is present in each folder detailing the use of the provided scripts for both training and evaluation.
- Hubert Tsai, Yao-Hung, Liang-Kang Huang, and Ruslan Salakhutdinov. "Learning robust visual-semantic embeddings." In Proceedings of the IEEE International Conference on Computer Vision, pp. 3571-3580. 2017.
- Wray, Michael, Diane Larlus, Gabriela Csurka, and Dima Damen. "Fine-grained action retrieval through multiple parts-of-speech embeddings." In Proceedings of the IEEE International Conference on Computer Vision, pp. 450-459. 2019.
- Schonfeld, Edgar, Sayna Ebrahimi, Samarth Sinha, Trevor Darrell, and Zeynep Akata. "Generalized zero-and few-shot learning via aligned variational autoencoders." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8247-8255. 2019.