项目的目标是从金庸的15本小说中挖掘出一些有用的信息,比如谁是金庸整个江湖的主角,那些人是一个群体,他们之间联系比较紧密。我们的所有输入只有15本金庸小说和一个人名表,为了完成这个任务,我们的处理流程如下:
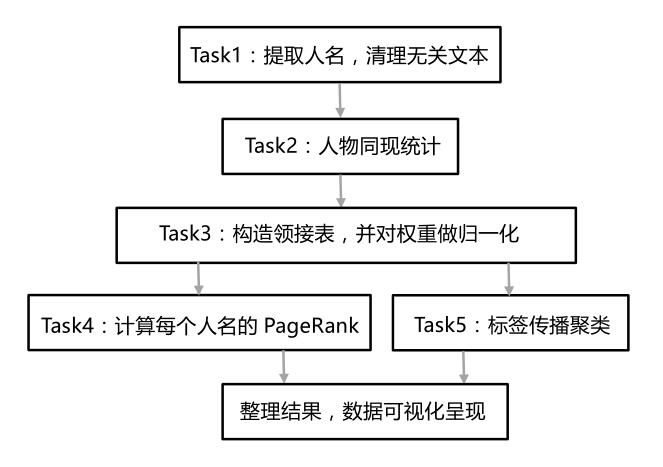
首先对数据做预处理,我们只需要人与人之间的关系,因此其他的文本就没有那么重要了,可以直接删去。然后我们对每一段中的人名做一个同现的统计,有了这样一个同现统计,就可以建立一个邻接表,用于描述金庸小说中这些人物两两之间的关系有多密切,共现次数就是用来描述这个密切程度的参数。接下来为了方便后面的分析工作,我们将这个共现次数做归一化。再就是两个分析,通过PageRank可以找到整个江湖中Rank值较高的一些人,也就是主角;标签传播则可以帮我们给所有的人物归类。最后用Gephi将这些分析结果用直观的方式呈现出来。
-
任务描述: 从原始的金庸小说文本中抽取出人物信息,即将人名无关的信息都删掉,只保留名字。这样做可以大大减少后面步骤的数据处理量。注意到,我们在做人物同现的时候,每一段中如果某个名字多次出现,实际只会统计一次。以及同现必须要至少有两个人存在,因此对某一段人名提取完后发现没有人名或者只有一个人名的情况,也可以过滤掉。

-
实现思路: 在提取人名的时候,我们先将这个人名表读取,存储到一个全局的数组中,检测每一行读入的文本是否含有某个人名。考虑到提取完名字后有很多重复的人名行,我们在Map过程中,将人名行作为key,1作为value,表示这个人名行出现了一次。Reduce过程首先统计对每个key,value的和是多少,然后就直接输出这个value和次的key即可,value为空。
-
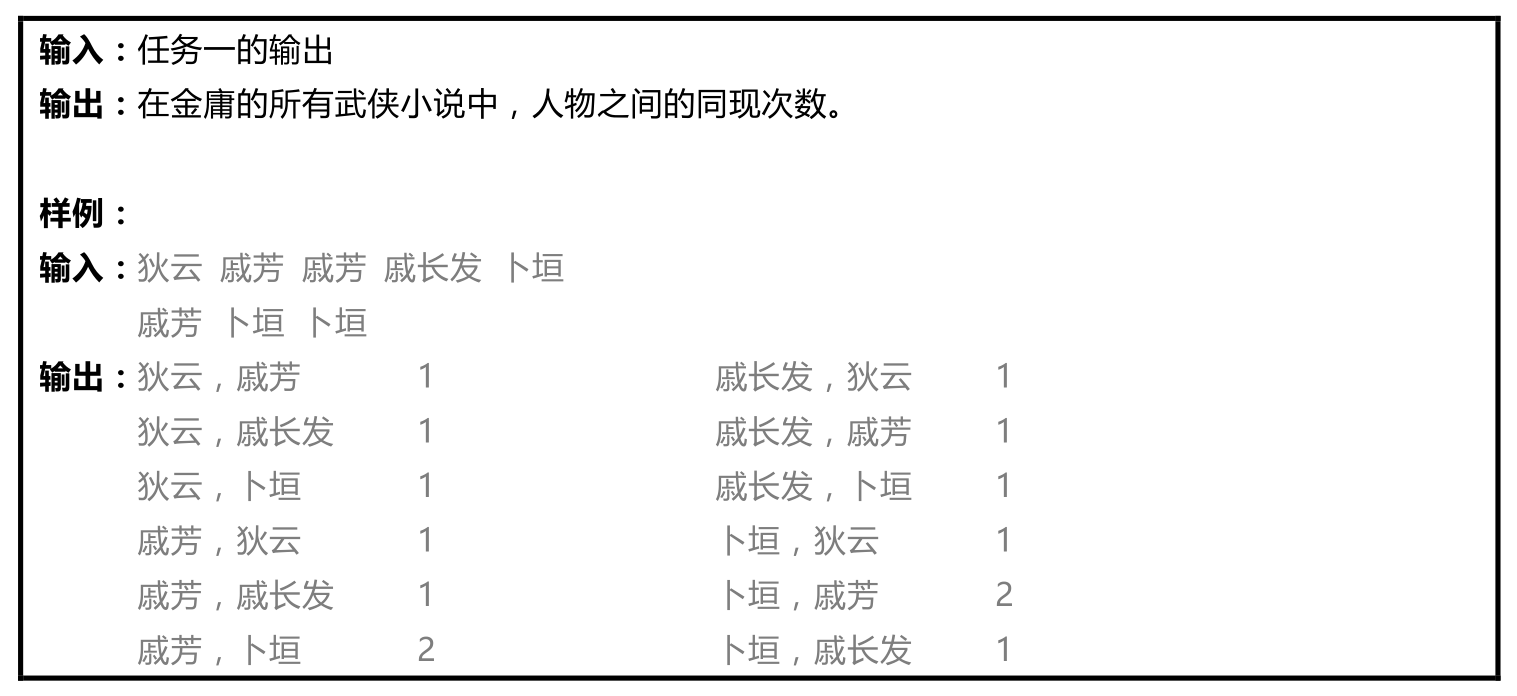
任务描述: 在人物同现分析中,如果两个人在原文的同一段落中出现,则认为两个人发生了一次同现关系。我们需要对人物之间的同现关系次数进行统计,同现关系次数越多,则说明两人的关系越密切。
-
实现思路: 这里的人物同现比常规的情况还要简单一些,因为人物A和人物B是无向的,<A,B>和<B,A>这两种情况都要输出,因此实现的时候只要做二重循环,只要不是同一个人,都输出一个<A,B> 1的键值对给reduce去统计。reduce过程也很简单,只要统计每种不同的<A,B>有多少个就行了。
-
任务描述: 当获取了人物之间的共现关系之后,我们就可以根据共现关系,生成人物之间的关系图了。人物关系图使用邻接表的形式表示,方便后面的PageRank计算。在人物关系图中,人物是顶点,人物之间的互动关系是边。人物之间的互动关系靠人物之间的共现关系确定。如果两个人之间具有共现关系,则两个人之间就具有一条边。两人之间的共现次数体现出两人关系的密切程度,反映到共现关系图上就是边的权重。边的权重越高则体现了两个人的关系越密切。
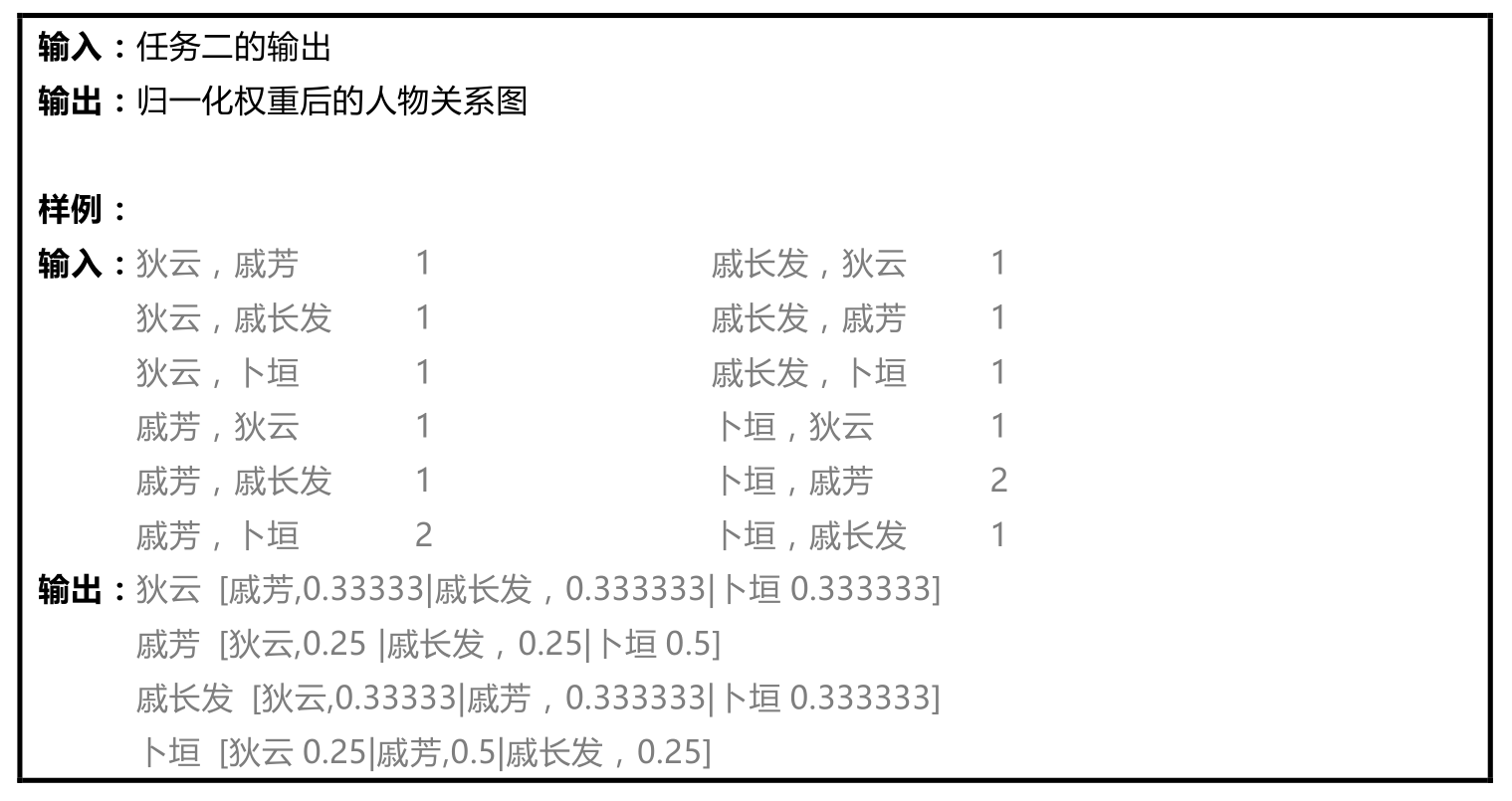 首先是将统计出的人物共现次数结果,转换成邻接表的形式表示:每一行表示一个邻接关系。
“戚芳 [狄云,0.25 |戚长发,0.25|卜垣0.5] ”表示了顶点“戚芳”,有三个邻接点,分别是“狄云”、“戚长发”和“卜垣”,对应三条邻接边,每条邻接边上分别具有不同的权重。这个邻接边的权重是依靠某个人与其他人共现的“概率”得到的,以“戚芳”为例,她分别与三个人(“狄云”共现1次、“戚长发”,共现1次、“卜垣”共现2次)有共现关系,则戚芳与三个人共现的“概率”分别为1/(1+1+2) = 0.25,1/(1+1+2) =0.25, 2/(1+1+2) = 0.5。这三个“概率”值对应与三条边的权重。通过这种归一化,我们确保了某个顶点的出边权重的和为1。
首先是将统计出的人物共现次数结果,转换成邻接表的形式表示:每一行表示一个邻接关系。
“戚芳 [狄云,0.25 |戚长发,0.25|卜垣0.5] ”表示了顶点“戚芳”,有三个邻接点,分别是“狄云”、“戚长发”和“卜垣”,对应三条邻接边,每条邻接边上分别具有不同的权重。这个邻接边的权重是依靠某个人与其他人共现的“概率”得到的,以“戚芳”为例,她分别与三个人(“狄云”共现1次、“戚长发”,共现1次、“卜垣”共现2次)有共现关系,则戚芳与三个人共现的“概率”分别为1/(1+1+2) = 0.25,1/(1+1+2) =0.25, 2/(1+1+2) = 0.5。这三个“概率”值对应与三条边的权重。通过这种归一化,我们确保了某个顶点的出边权重的和为1。 -
实现思路: 对于每一个输入“A,B X”,其中,A,B表示两个名字,X表示这两个名字的同现次数,我们只需要构建一个以A为key,多组B,X构成的value的长字符串。Map过程将输入字符串拆分成key:A value:B X,发射到reduce节点,这样可以保证所有key相同的键值对都发射到同一个reduce节点。对于某个key,reduce收到了一组该key对应的value,每个value的形式是“B X”,对这些X求和得到SUM,然后将X改成概率表示的形式:“B P”,其中P=X/SUM,最后将这些“B P”拼接起来作为value输出。
-
任务描述: 在给出人物关系图之后,我们就可以对人物关系图进行一个数据分析。其中一个典型的分析任务是:PageRank 值计算。通过计算 PageRank,我们就可以定量地金庸武侠江湖中的“主角”们是哪些。
-
实现思路: PageRank需要迭代,显然如果直接把任务3的输出作为我们的输入,似乎迭代的时候会不方便,比如说每个人物的PageRank值应该在首次迭代的时候就初始化好。因此我们修改了一下任务3的程序,单独给PageRank生成一个初始化输入,改动如下:
| 样例格式 | |
|---|---|
| 原有的结果 | 一灯大师 乔寨主,0.0022988506;华筝,0.0022988506;…… |
| 现在的结果 | 一灯大师 1&乔寨主,0.0022988506;华筝,0.0022988506;…… |
- 其中1表示初始的PageRank值,我们给所有人物的初始PageRank值都是1,&符号仅仅为了在解析字符串时做分隔用。这样就确保了PageRank整个迭代周期都保证了统一的文件格式,在Map和reduce过程中就不需要针对第一次输入做额外的检测。 迭代过程中,有两个部分需要考虑,第一:为了保证文件格式的一致性,每个人名后面跟的一个“人名,权值”的长字符串要传给reduce以供写到文件。第二:计算新的PageRank值并更新,在实现的时候只要遍历每个人名后面的长字符串,计算出当前作为key的人名对每个人名PageRank值的贡献,举例:一灯大师 1&乔寨主,0.0022988506;华筝,0.0022988506;…… 首先解析出有很多对“人名,权值”,比如“乔寨主,0.00229…”,那么我们将“乔寨主”作为key,用“一灯大师”的PageRank值乘以这个权值,就得到了“一灯大师”对“乔寨主”的PageRank值的贡献,这个乘积作为value,将这个键值对发射给reduce节点。 Reduce过程接收这些键值对,将同一个人得到的不同贡献相加,就是它的新的RageRank值了,不过要注意的是,这里还应该引入一个阻尼系数,新的PageRank值最后被确定为:
- 一般来讲这个松弛系数取0.85,PRsum就是不同贡献值的和。最后,做一步清理工作,一是只保留人名和PageRank值,二是利用mapreduce自带的排序,将PageRank值作为主键,得到一个从高到低排序的人名表。
-
任务描述: 标签传播(Label Propagation)是一种半监督的图分析算法,他能为图上的顶点打标签,进行图顶点的聚类分析,从而在一张类似社交网络图中完成社区发现(Community Detection)。该任务中,我们用每个聚类的核心人物作为这个类的标签,比如下面输出中,“张无忌”实际上是一个标签名,表示“杨逍”属于张无忌这个类。
-
实现思路: LPA需要迭代,因此我们采用了和PageRank差不多的方式做了初始化,初始化文件的格式如下:
一灯大师 一灯大师&乔寨主,0.0022988506,乔寨主;华筝,0.0022988506,华筝;……
- 这里,“一灯大师”是key,value中,“&”前面的“一灯大师”表示key对应的标签,我们的初始化标签均和自己相同。后面,“乔寨主”是人名,中间数字是它的权重,后一个“乔寨主”是它的标签,在迭代的时候我们会更新这个标签,这里初始化的时候使用的是自己的名字。迭代过程中最关键的是如何选取新的标签,遍历“&”后面的“人名,权值,标签”列表,我们要统计出那个贡献值最高的标签。举例:
一灯大师 一灯大师&乔寨主,0.0022988506,乔寨主;华筝,0.0022988506,华筝;……
- 假设我们现在正在统计的就是这一行数据,在解析“&”后面的字符串时,除了第一次迭代之外,会出现多个人对应同一个标签的情况,因此需要一个数组来存储每个标签在当前字符串中的总权值,如果该标签还没出现,那把该标签新家进去,该标签的权值作为总权值的一个初值。比如说现在的这个数组是空的,我发现“乔寨主”的标签是“乔寨主”,那么这个数组里就应该添加一条记录:“乔寨主”这个标签的当前权值是0.00229…,后面还有“乔寨主”的话,直接用那个权值加上当前的“乔寨主”的总权值即可。我们还需要一个数组记录下这整个字符串中的所有人名,这个后面会用到。现在我们已经有了一组“标签,权重”的记录,因此从中挑选权重最高的作为key的标签就可以了,注意输出到reduce的时候,为了保持迭代时文件格式一致,应当将这个长字符串一起发送给reduce。我们还有一件事要做,告诉所有和当前key相关的其他key,当前key对应的标签变了,所以我们输出遍历之前记录了整个字符串中所有人名的数组,以单个人名为key,将更新过的当前的key和标签作为value也输出到reduce以供reduce更新。Reduce过程做的工作就是更新长字符串中的标签,最后按照统一格式写到文件。最后还有一步清理工作,只保留标签和人名输出一个最终文件即可。
将得到的标签传播,Pagerank结果结合起来,在gephi中导入数据并选择合适的参数,可以得到如下的总体结果:
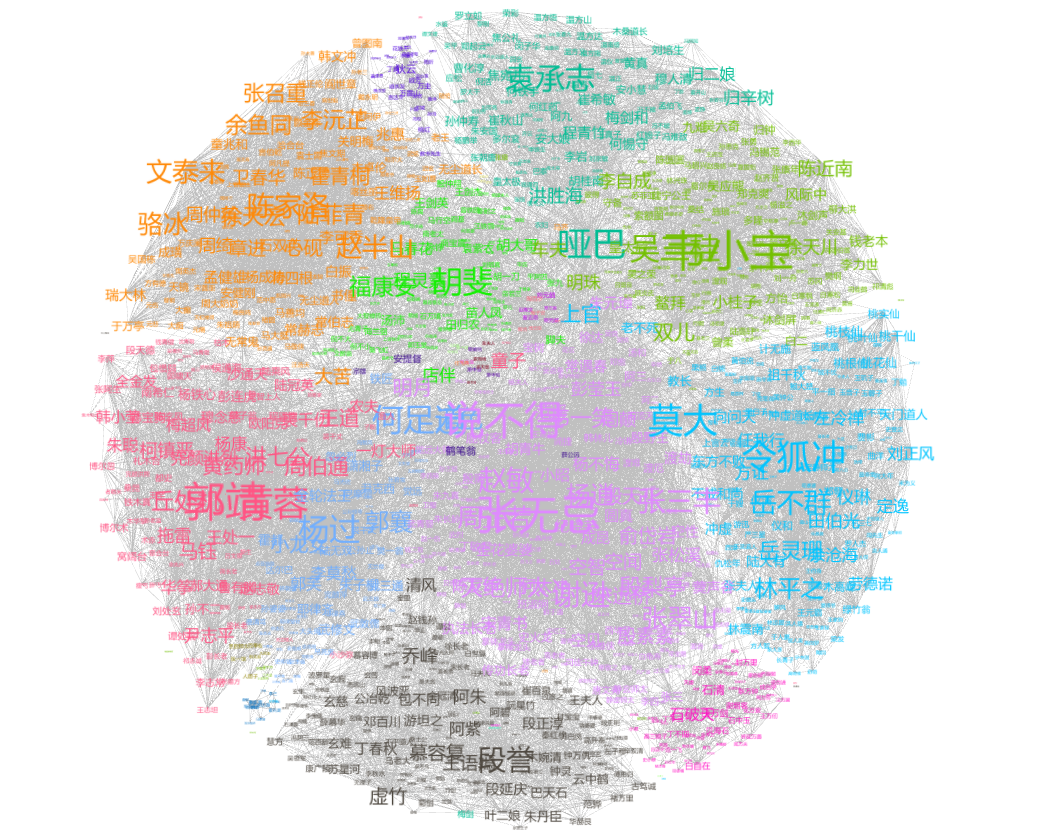
根据这张图我们可以看到整个金庸江湖中的主要角色,基本上每本书中的人物是一类,同一本书内部人物之间关系更加密切,这符合我们的认知。
第二张图是主要角色图,所有的重要角色基本上都围绕在整个图的四周。

下面更换了参数,生成了一张新的聚类图:
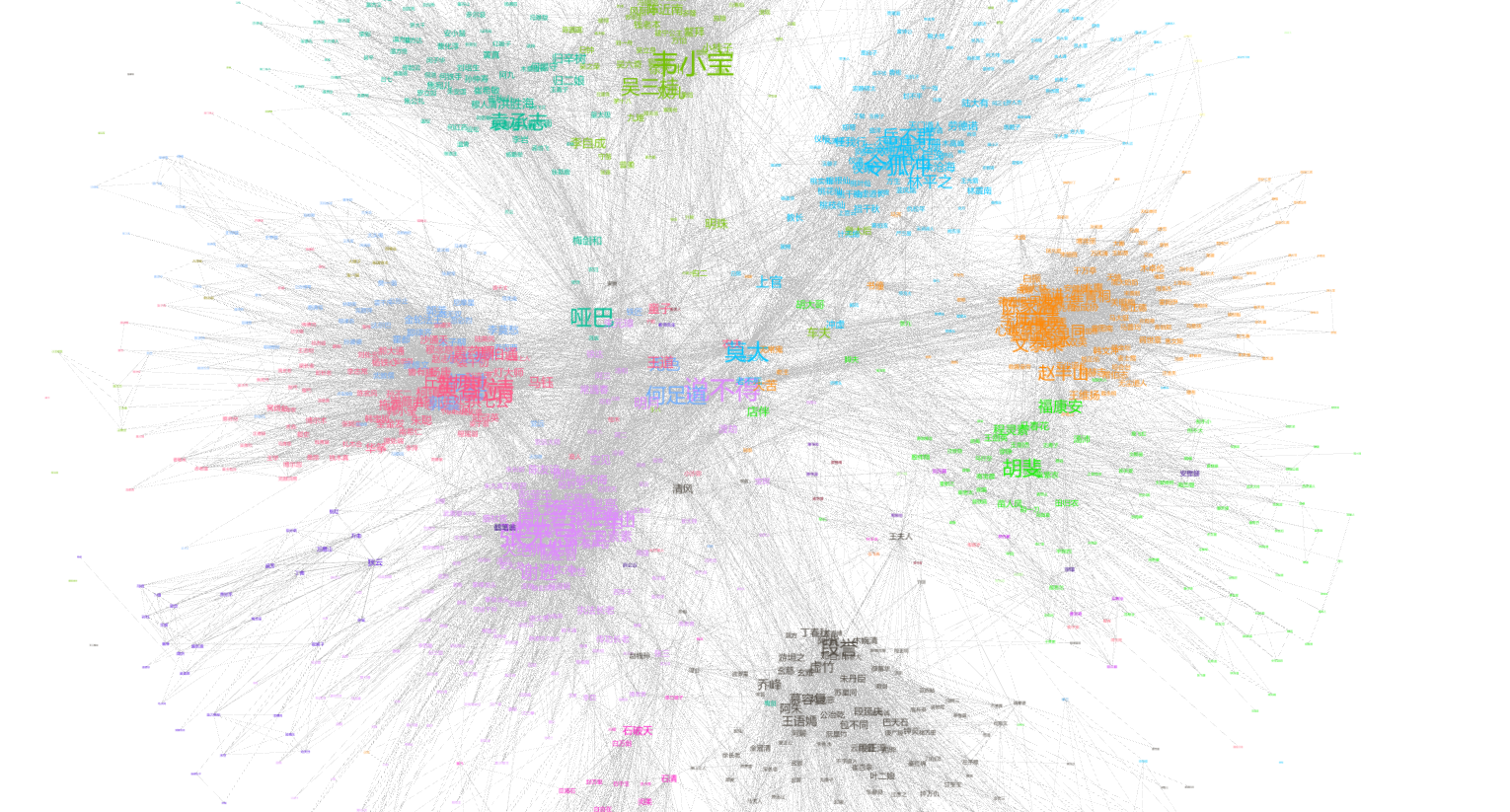
我们可以查看一下这张图的局部:
局部图1:《碧血剑》和《鹿鼎记》,李自成这个在两本书中共有的一个角色和两个集群都有联系。
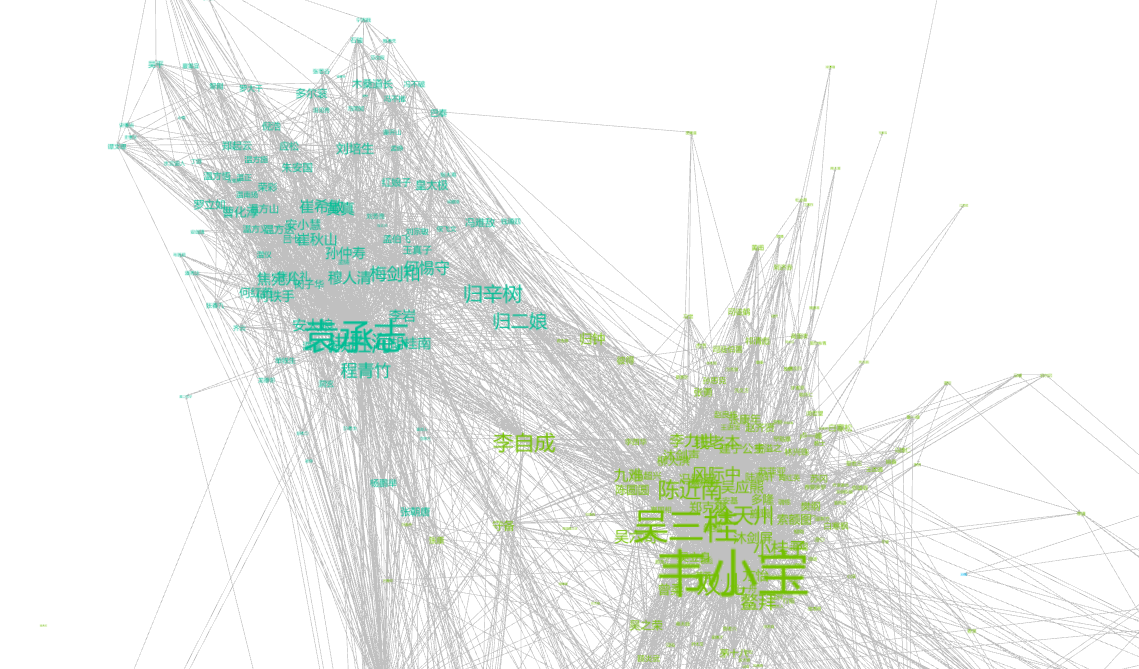
局部图2:《倚天屠龙记》

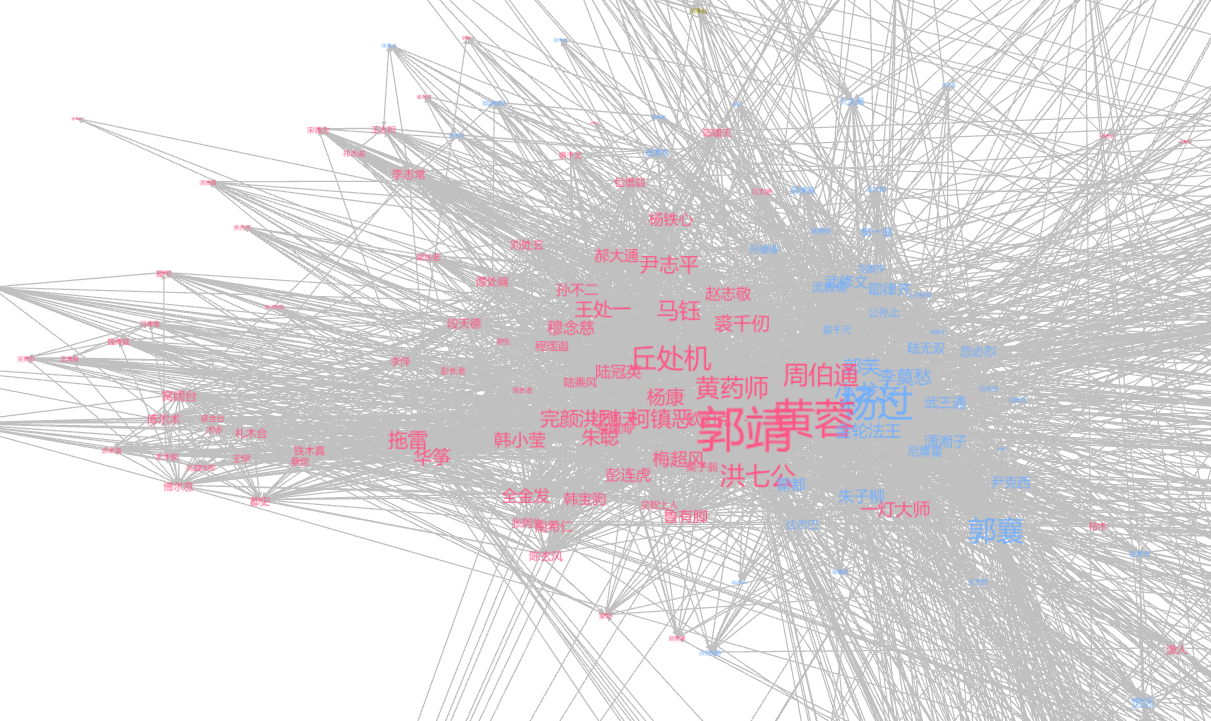
局部图3:《射雕英雄传》和《神雕侠侣》,这两本书中的人物关系密切,比如杨过是杨过是郭靖义弟杨康的儿子,郭襄是郭靖黄蓉的女儿。
局部图4:《侠客行》和《天龙八部》

更多细节可以下载源码中gephidata中的两个数据文件,载入到gephi中查看。
人名提取方式的选择: 我们并没有采用Ansj_seg来做分词,提取人名的方式有两种,一是根据人名表,直接对每一行输入文本做字符串匹配,也就是我们采用的方法。二是对文本做分词,根据词性识别出人名。从效率来讲方法二要比方法一快不少,但实际上当我在检查分词版本的《越女剑》(并未提供人名表)的时候,发现“阿青”这个人物,在分词版本的小说中显示的是“阿 青”(中间有空格),这个时候用“阿青”去匹配文中的词是匹配不到的,也就会导致某本小说中某个重要角色因为匹配问题而完全缺失,这是我们不想看到的。因此我怀疑用词性的方式分词没办法保证100%正确,正如我前面举得“阿 青”的例子。但是这种方法在处理人名特别多的时候,效果应该会比后者要好很多(即使这个时候牺牲一小部分的正确率)后者虽然比较粗暴,但是可以保证100%的正确率。考虑到金庸小说中一共只有1000多个人物,因此用后者并不会有太多的性能劣势。
LPA和PageRank初始化: LPA和PageRank在实现的时候也可以直接用归一化的结果做输入,只不过归一化的结果在第一次迭代中需要加工,也就是说在第一次迭代中我们需要有一个分支去专门处理首次迭代的情况,比如PageRank就需要为每个人名初始化一个PageRank值,从代码的简洁性角度来讲,这并不是一种很好的实现方式。因此我们就在归一化的输出结果中稍微加了一些统一的初始化值,一些标记等等,这样使我们的两个数据分析程序显得相对简洁明白。
标签传播算法的选择: 我们在一开始想采用一个简单版本的标签传播算法,即不考虑权重,每个节点选择自己邻居节点中最频繁出现的标签作为自己的标签,在测试时我们发现这种传播方式的效果不是很好,一方面,当出现多个标签出现次数相同的情况,随机选择产生的震荡问题会比较严重;二,得到的标签不一定是这个集合的主要角色。而加入了权值之后,从一开始高权值的节点就对其他节点有更大的影响力,随着不断迭代,它对其他节点的影响也不断被强化。
[1] 《深入理解大数据》机械工业出版社,黄宜华,苗凯翔
[2] PIG标签传播算法和超级英雄们的社区发现http://www.cnphp6.com/archives/24136