Add support for incremental loads to FDW plugins #647
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Add a `cursor_columns` field to the table parameters (used as a list of columns that form an increasing-only replication bookmark). Store the ingestion state in a table inside of the image, similarly to Airbyte.
mildbyte
commented
Mar 10, 2022
splitgraph/hooks/data_source/fdw.py
Outdated
Comment on lines
387
to
428
| with delete_schema_at_end(repository.object_engine, staging_schema): | ||
| repository.object_engine.delete_schema(staging_schema) | ||
| repository.object_engine.create_schema(staging_schema) | ||
| repository.commit_engines() | ||
|
|
||
| self._mount_and_copy( | ||
| staging_schema, | ||
| tables, | ||
| cursor_values=None if not state else state.get("cursor_values"), | ||
| ) | ||
|
|
||
| logging.info("Storing tables as Splitgraph images") | ||
| for table_name in repository.object_engine.get_all_tables(staging_schema): | ||
| logging.info("Storing %s", table_name) | ||
| new_schema = repository.object_engine.get_full_table_schema( | ||
| staging_schema, table_name | ||
| ) | ||
|
|
||
| if base_image: | ||
| try: | ||
| current_schema = base_image.get_table(table_name).table_schema | ||
| if current_schema != new_schema: | ||
| raise AssertionError( | ||
| "Schema for %s changed! Old: %s, new: %s" | ||
| % ( | ||
| table_name, | ||
| current_schema, | ||
| new_schema, | ||
| ) | ||
| ) | ||
| except TableNotFoundError: | ||
| pass | ||
|
|
||
| repository.objects.record_table_as_base( | ||
| repository, | ||
| table_name, | ||
| new_image_hash, | ||
| chunk_size=DEFAULT_CHUNK_SIZE, | ||
| source_schema=staging_schema, | ||
| source_table=table_name, | ||
| table_schema=new_schema, | ||
| ) |
There was a problem hiding this comment.
There's some overlap between this code and the code in https://github.com/splitgraph/splitgraph/blob/master/splitgraph/ingestion/airbyte/data_source.py#L290-L329 but I don't know if there's a nice way to factor it out + when writeable LQ lands, we should be able to simplify this code anyway by writing into the LQ checkout.
gruuya
approved these changes
Mar 10, 2022
splitgraph/hooks/data_source/fdw.py
Outdated
Comment on lines
387
to
428
| with delete_schema_at_end(repository.object_engine, staging_schema): | ||
| repository.object_engine.delete_schema(staging_schema) | ||
| repository.object_engine.create_schema(staging_schema) | ||
| repository.commit_engines() | ||
|
|
||
| self._mount_and_copy( | ||
| staging_schema, | ||
| tables, | ||
| cursor_values=None if not state else state.get("cursor_values"), | ||
| ) | ||
|
|
||
| logging.info("Storing tables as Splitgraph images") | ||
| for table_name in repository.object_engine.get_all_tables(staging_schema): | ||
| logging.info("Storing %s", table_name) | ||
| new_schema = repository.object_engine.get_full_table_schema( | ||
| staging_schema, table_name | ||
| ) | ||
|
|
||
| if base_image: | ||
| try: | ||
| current_schema = base_image.get_table(table_name).table_schema | ||
| if current_schema != new_schema: | ||
| raise AssertionError( | ||
| "Schema for %s changed! Old: %s, new: %s" | ||
| % ( | ||
| table_name, | ||
| current_schema, | ||
| new_schema, | ||
| ) | ||
| ) | ||
| except TableNotFoundError: | ||
| pass | ||
|
|
||
| repository.objects.record_table_as_base( | ||
| repository, | ||
| table_name, | ||
| new_image_hash, | ||
| chunk_size=DEFAULT_CHUNK_SIZE, | ||
| source_schema=staging_schema, | ||
| source_table=table_name, | ||
| table_schema=new_schema, | ||
| ) |
Also handle the case where it's not specified.
It adds this table in cases like a CSV upload, polluting the repository. Instead, when loading the state during a sync, fall back to getting the cursor values by just querying the max fields in the current image if it doesn't exist.
Gelio
reviewed
Mar 11, 2022
| @@ -134,22 +135,42 @@ def copy_table( | |||
| target_schema: str, | |||
| target_table: str, | |||
| with_pk_constraints: bool = True, | |||
| cursor_fields: Optional[Dict[str, str]] = None, | |||
There was a problem hiding this comment.

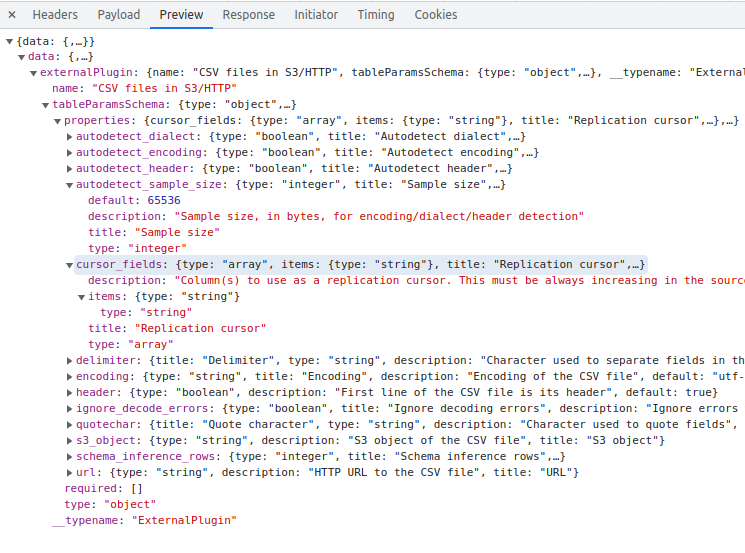
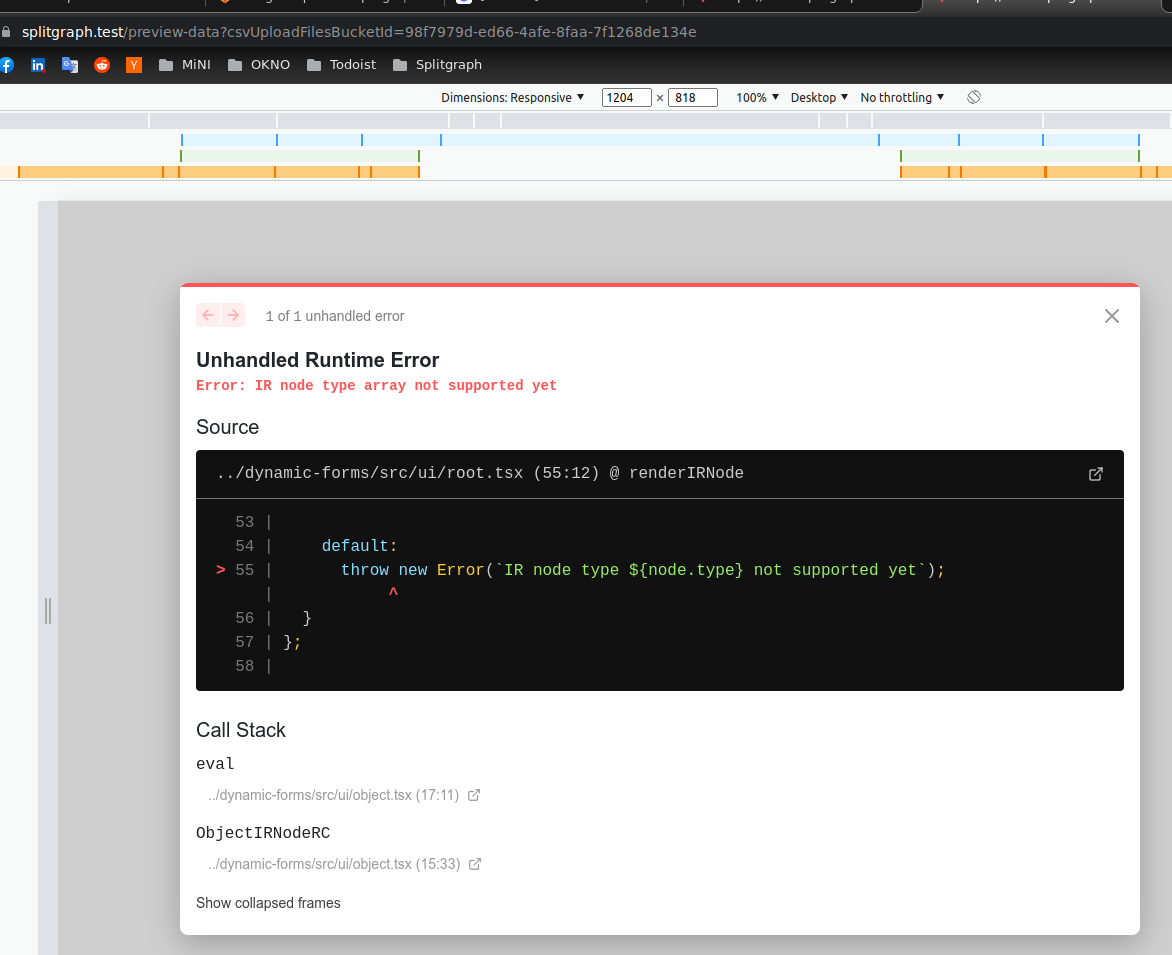
Array fields are not supported by dynamic forms. I suppose I should relax the error message
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Add a
cursor_columnsfield to the table parameters (used as a listof columns that form an increasing-only replication bookmark). Store the
ingestion state in a table inside of the image, similarly to Airbyte.