Enhance classify.py script to build predictive models for classifying measurements #227
Comments
|
Dorado data from the stoqs_september2013 campaign have chlorophyll/backscatter data that are easily labeled as shown in this figure:
For more background read Using STOQS (The spatial temporal oceanographic query system) to manage, visualize, and understand AUV, glider, and mooring data, especially section V, which is excerpted here: V. UNDERSTANDING DATA |
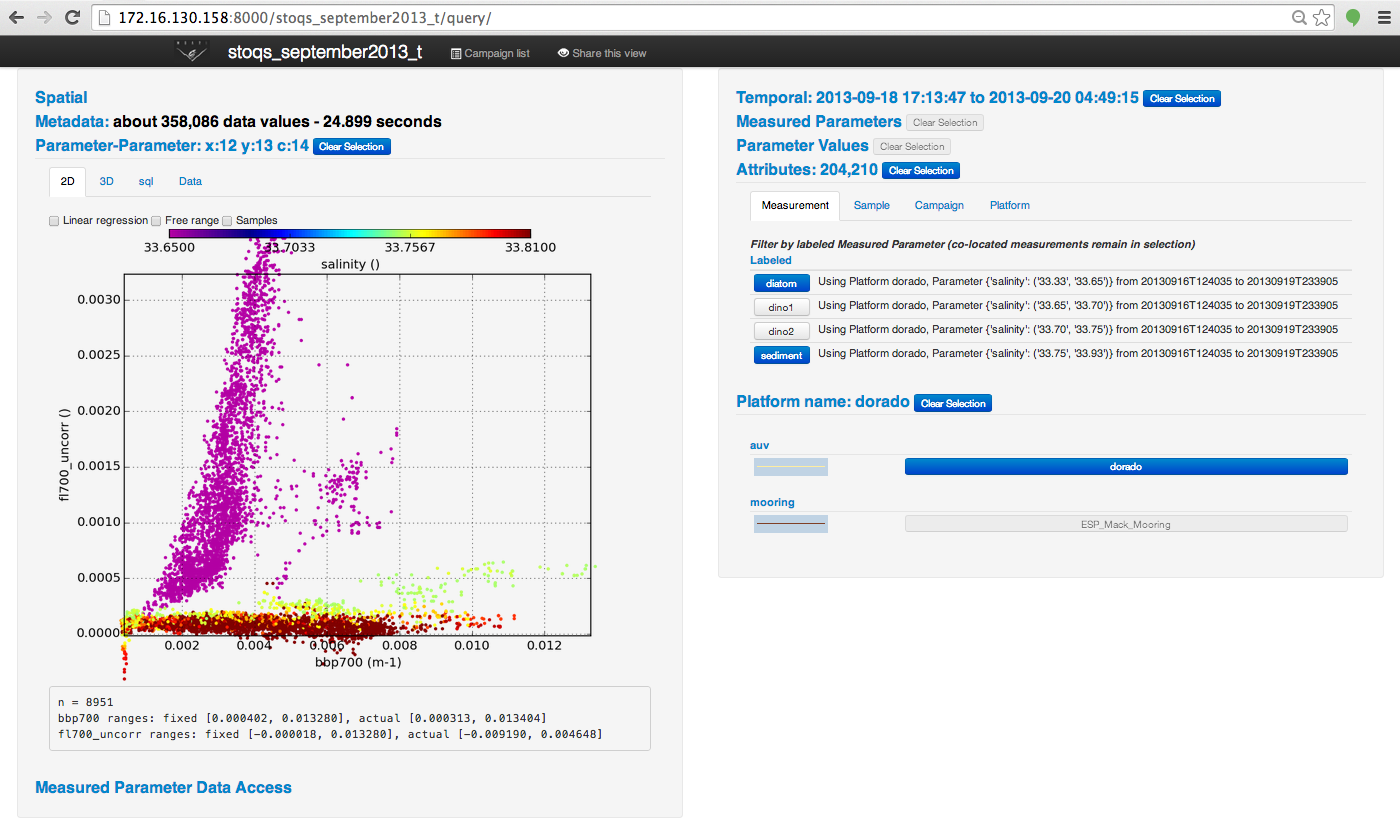
|
Here is another resource to explore for performing classification in Python. With this you can actually execute the cells on the web without configuring your own STOQS development environment. You will need a Kaggle account, but that is easy to set up. |
|
Once a model is developed and cross-validated form the Dorado data shown above it can be applied to other chlorophyll/backscatter data from the other vehicles that surveyed Monterey Bay during this same campaign. Here is an animated GIF of those data: With these data classified we can then construct a picture of the spatial and temporal distribution of various kinds of plankton. |
{kind=link}
|
Welcome @devonrusconi and @vitoupen to the STOQS project! Here is another resource for learning about classification using scikit-learn: |
|
Comparing classifiers plot added to Jupyter Notebook at https://github.com/MBARIMike/stoqs/blob/capstone2016/stoqs/contrib/notebooks/classify_data.ipynb |
|
The Capstone 2016 contribution PR is a step toward the implementation of a general purpose predictive classification capability. This issue will remain open awaiting contributions toward this goal. |
|
For background on using measurement data as proxies for identifying plankton please see this paper: https://www.sciencedirect.com/science/article/pii/S0079661118300478?via%3Dihub |
This issue is a follow-on to Issue #49 and gets to the heart of performing Machine Learning on data stored in STOQS. There are comments in the createClassifier() method of https://github.com/stoqs/stoqs/blob/master/stoqs/contrib/analysis/classify.py that give pointers on what work needs to be done. Watch the video at https://www.youtube.com/watch?v=4ONBVNm3isI to learn the techniques that can be followed for creating classifiers and doing cross validation.
The key contribution of this issue is to implement general purpose predictive classification capability for any measurements in STOQS. The classify.py script provides a starting place for the implementation and Jupyter Notebooks should be used to demonstrate its use.
The text was updated successfully, but these errors were encountered: