Table of Contents
-
https://github.com/amirgholami/ai_and_memory_wall (article)We report the number of paramters, feature size, as well as the total FLOPs for inference/training for SOTA models in CV, Speech Learning, and NLP.
-
https://blog.eleuther.ai/transformer-math/
- This is optimal in one very specific sense: in a resource regime where using 1,000 GPUs for 1 hour and 1 GPU for 1,000 hours cost you the same amount, if your goal is to maximize performance while minimizing the cost in GPU-hours to train a model you should use the above equation.
- We do not recommend training a LLM for less than 200B tokens. Although this is “chinchilla optimal” for many models, the resulting models are typically quite poor. For almost all applications, we recommend determining what inference cost is acceptable for your usecase and training the largest model you can to stay under that inference cost for as many tokens as you can.
-
you can run GLM-130B on a local machine https://twitter.com/alexjc/status/1617152800571416577?s=20
-
chinchilla 67b outperforms GPT3 175b - better data and longer training
-
LLAMA training costs - LLAMA 65B spend 1m GPU hours same as OPT/BLOOM 175B https://simonwillison.net/2023/Mar/17/beat-chatgpt-in-a-browser/
-
instructgpt 1.3b outperforms GPT3 175b - with same performance
-
2020 https://huggingface.co/calculator/ How Big Should My Language Model Be? ## There is an optimal time to stop training (and it's earlier than you think)
-
https://arxiv.org/pdf/2112.00861.pdf Throughout this paper we will be studying a consistent set of decoder-only Transformer language models with parameter counts ranging from about 10M to 52B in increments of 4x, and with a fixed context window of 8192 tokens and a 2 16 token vocabulary. For language model pre-training, these models are trained for 400B tokens on a distribution consisting mostly of filtered Common Crawl data [Fou] and internet books, along with a number of smaller distributions [GBB+20], including about 10% python code data. We fix the aspect ratio of our models so that the activation dimension dmodel = 128nlayer,
-
Data - the 175B parameters model on 300B tokens (60% 2016 - 2019 C4 + 22% WebText2 + 16% Books + 3% Wikipedia). Where: - https://lifearchitect.ai/chinchilla/ extremely good explanation
https://twitter.com/srush_nlp/status/1633509903611437058?s=46&t=90xQ8sGy63D2OtiaoGJuww xkcd style tbale with orders if magnitude as opposed to Kaplan scaling laws (1.7x tokens, instead of 20x tokens)
- the most pessimistic estimate of how much like the most capable organization could get is the 500 billion tokens. A more optimistic estimate is like 10 trillion tokens is how many tokens the most capable organization could get, like mostly English tokens. https://theinsideview.ai/ethan#limits-of-scaling-data
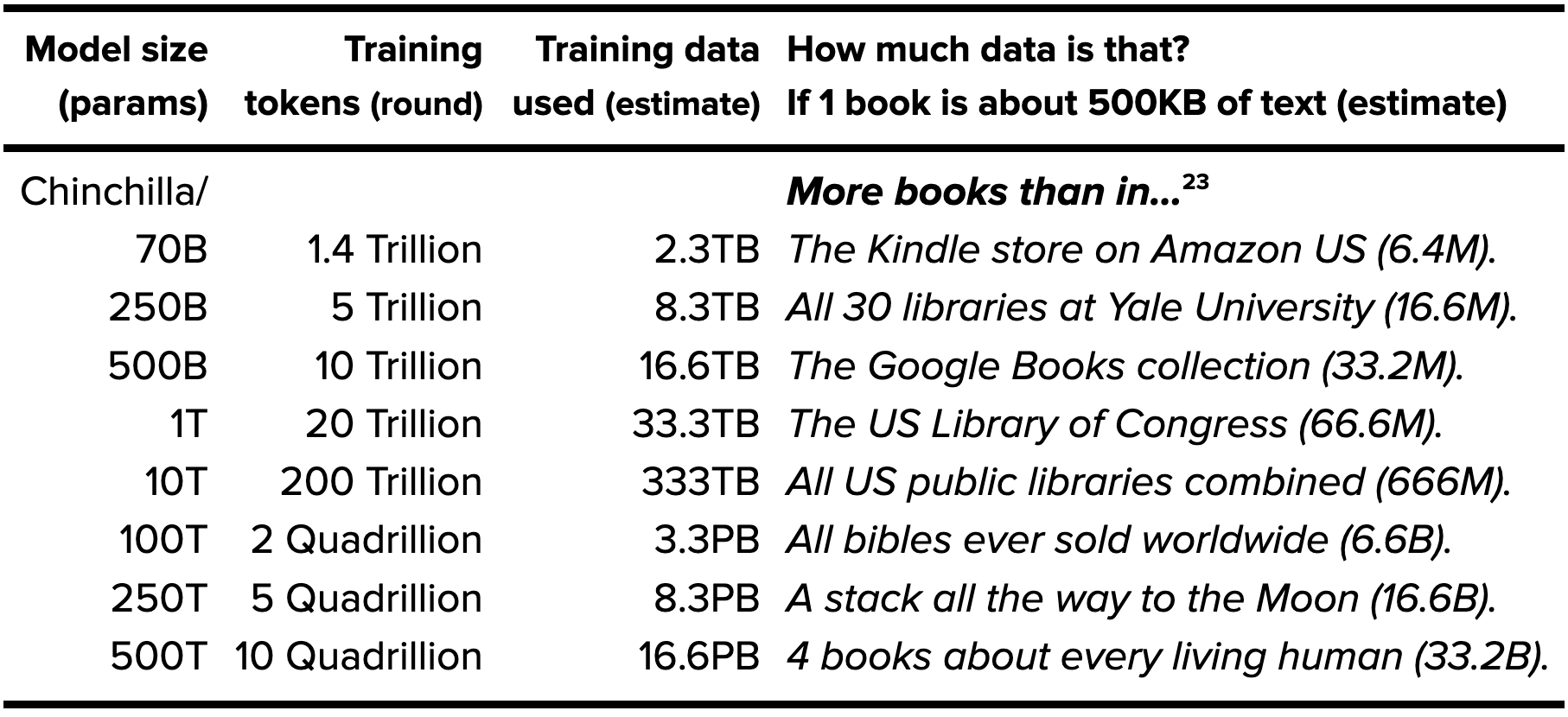
- https://x.com/mark_cummins/status/1788949893903511705?s=46&t=90xQ8sGy63D2OtiaoGJuww
- Llama 3 was trained on 15 trillion tokens (11T words). That’s large - approximately 100,000x what a human requires for language learning
- https://twitter.com/BlancheMinerva/status/1644175139028840454?s=20
- In 2010 Google Books reported 129,864,880 books. According to UNESCO, there are several million books published in the US alone each year.
- There are over 2,000 characters per page of text, which means that if the average book has 100 pages the total set of books in 2010 is about 100x the size of the Pile and that number grows by about one Pile per year.
- Over 100 million court cases are filed in the US each year. Even if the average court case had one page this would be on the scale of the Pile. https://iaals.du.edu/sites/default/files/documents/publications/judge_faq.pdf
- Estimates for the number of academic papers published are around 50 million, or 30 Piles if we assume an average length of 10 pages (which I think is a substantial underestimate):
- So books + academic papers + US court cases from the past 10 years is approximately 150x the size of the Pile, or enough to train a chinchilla optimal 22.5T parameter model.
- https://www.semianalysis.com/p/the-ai-brick-wall-a-practical-limit
-
Notes on frontier model training from Yafah Edelman
- Cost Breakdown of ML Training
- Why ML GPUs Cost So Much
- Contra FLOPs
- ML Parallelism
- We (Probably) Won’t Run Out of Data
- AI Energy Use and Heat Signatures
-
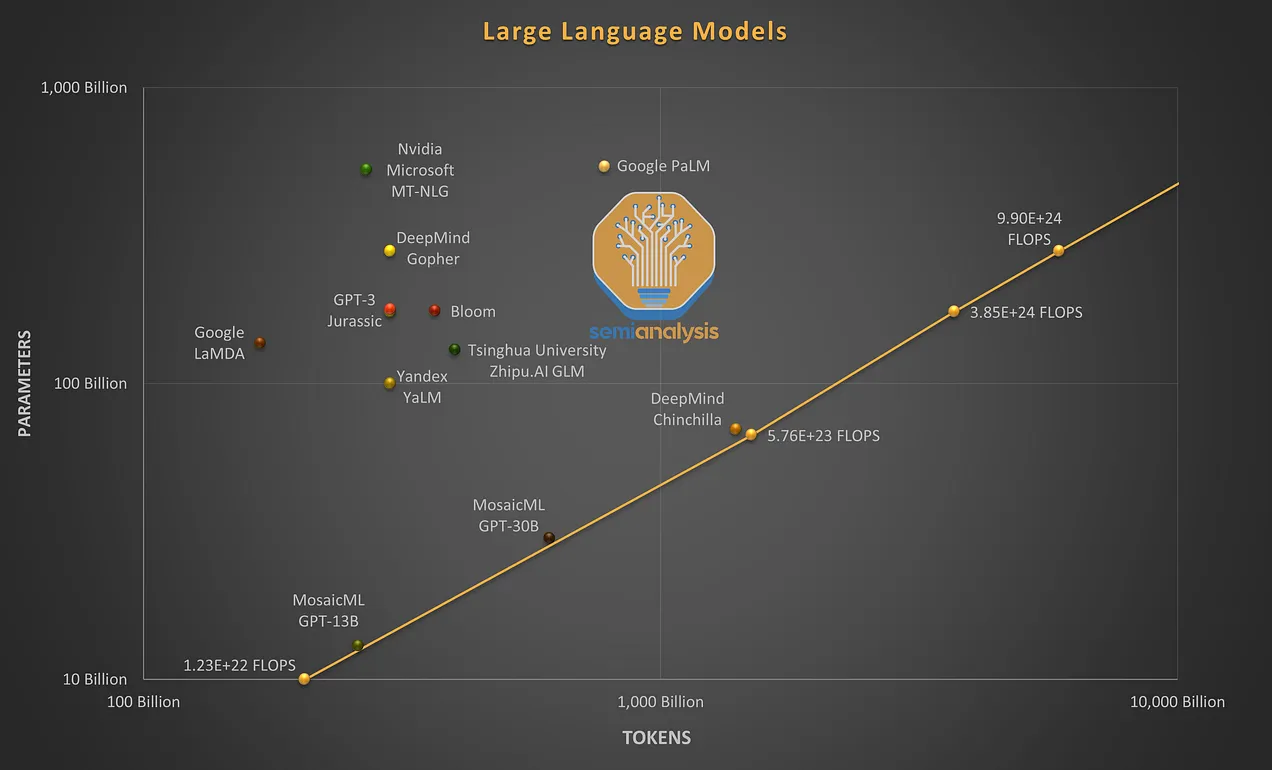
https://www.lesswrong.com/posts/RihYwmskuJT9Rkbjq/the-longest-training-run

-
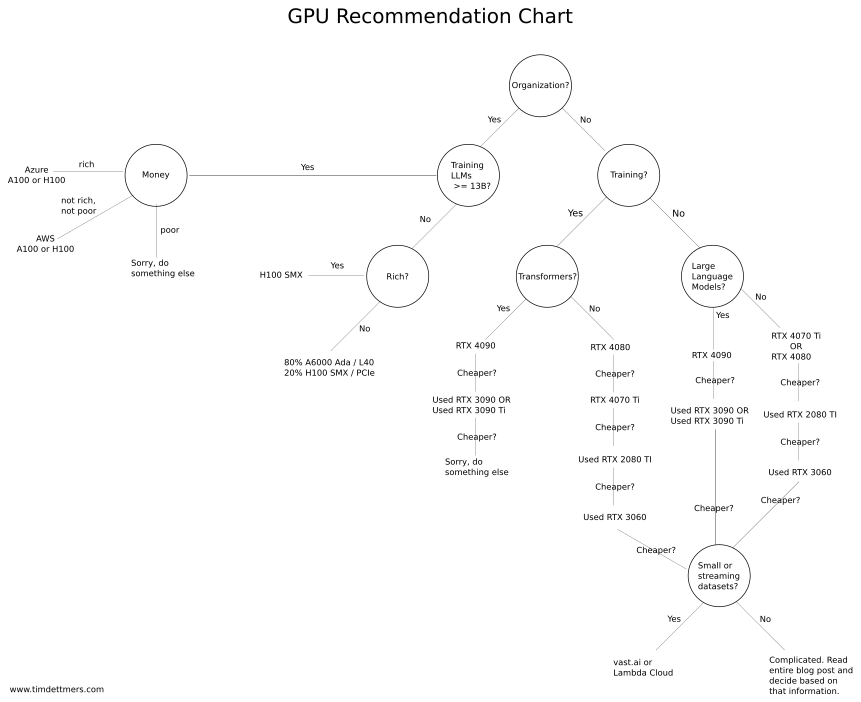
guide to GPUs https://timdettmers.com/2018/12/16/deep-learning-hardware-guide/
-
dan jeffries ai infra landscape https://ai-infrastructure.org/why-we-started-the-aiia-and-what-it-means-for-the-rapid-evolution-of-the-canonical-stack-of-machine-learning/
-
bananadev cold boot problem https://twitter.com/erikdunteman/status/1584992679330426880?s=20&t=eUFvLqU_v10NTu65H8QMbg
-
replicate.com
-
cerebrium.ai
-
banana.dev
-
huggingface.co
-
lambdalabs.com
-
Paperspace/Tensordock/Runpod?
-
astriaAI
-
oblivus GPU cloud https://oblivus.com/cloud/
-
specific list of gpu costs https://fullstackdeeplearning.com/cloud-gpus/
-
H100 gpu discussions https://gpus.llm-utils.org/nvidia-h100-gpus-supply-and-demand/#how-much-do-these-gpus-cost
- h100 is 11x more powerful than a100, h200 will be 18x more powerful https://www.nvidia.com/en-gb/data-center/h200/
-
cost of chatgpt - https://twitter.com/tomgoldsteincs/status/1600196981955100694
- A 3-billion parameter model can generate a token in about 6ms on an A100 GPU
- a 175b param it should take 350ms secs for an A100 GPU to print out a single word
- You would need 5 80Gb A100 GPUs just to load the model and text. ChatGPT cranks out about 15-20 words per second. If it uses A100s, that could be done on an 8-GPU server (a likely choice on Azure cloud)
- On Azure cloud, each A100 card costs about $3 an hour. That's $0.0003 per word generated.
- The model usually responds to my queries with ~30 words, which adds up to about 1 cent per query.
- If an average user has made 10 queries per day, I think it’s reasonable to estimate that ChatGPT serves ~10M queries per day.
- I estimate the cost of running ChatGPT is $100K per day, or $3M per month.
-
the top-performing GPT-175B model has 175 billion parameters, which total at least 320GB (counting multiples of 1024) of storage in half-precision (FP16) format, leading it to require at least five A100 GPUs with 80GB of memory each for inference. https://arxiv.org/pdf/2301.00774.pdf
-
And training itself isn’t cheap. PaLM is 540 billion parameters in size, “parameters” referring to the parts of the language model learned from the training data. A 2020 study pegged the expenses for developing a text-generating model with only 1.5 billion parameters at as much as $1.6 million. And to train the open source model Bloom, which has 176 billion parameters, it took three months using 384 Nvidia A100 GPUs; a single A100 costs thousands of dollars. https://techcrunch.com/2022/12/30/theres-now-an-open-source-alternative-to-chatgpt-but-good-luck-running-it/
- PaLM estimated to cost between 9-23M https://blog.heim.xyz/palm-training-cost/
- The final training run of PaLM required 2.56×10²⁴ (2.56e24) FLOPs.
- We trained PaLM-540B on 6144 TPU v4 chips for 1200 hours and 3072 TPU v4 chips for 336 hours including some downtime and repeated steps.
- VERY VERY GOOD POST FOR DOING MATH
- PaLM estimated to cost between 9-23M https://blog.heim.xyz/palm-training-cost/
-
Doing a back-of-the-envelope calculation, a 7B Llama 2 model costs about $760,000 to pretrain! https://twitter.com/rasbt/status/1747282042457374902
- The total number of GPU hours needed is 184,320 hours.
- The cost of running one A100 instance per hour is approximately $33.
- Each instance has 8 A100 GPUs.
- That's 184320 / 8 * 33 = $760,000
-
Bloom requires a dedicated PC with around eight A100 GPUs. Cloud alternatives are pricey, with back-of-the-envelope math finding the cost of running OpenAI’s text-generating GPT-3 — which has around 175 billion parameters — on a single Amazon Web Services instance to be around $87,000 per year.
- https://bdtechtalks.com/2020/09/21/gpt-3-economy-business-model/
- Lambda Labs calculated the computing power required to train GPT-3 based on projections from GPT-2. According to the estimate, training the 175-billion-parameter neural network requires 3.114E23 FLOPS (floating-point operation), which would theoretically take 355 years on a V100 GPU server with 28 TFLOPS capacity and would cost $4.6 million at $1.5 per hour.
- We can’t know the exact cost of the research without more information from OpenAI, but one expert estimated it to be somewhere between 1.5 and five times the cost of training the final model. This would put the cost of research and development between $11.5 million and $27.6 million, plus the overhead of parallel GPUs.
- According to the OpenAI’s whitepaper, GPT-3 uses half-precision floating-point variables at 16 bits per parameter. This means the model would require at least 350 GB of VRAM just to load the model and run inference at a decent speed. This is the equivalent of at least 11 Tesla V100 GPUs with 32 GB of memory each. At approximately $9,000 a piece, this would raise the costs of the GPU cluster to at least $99,000 plus several thousand dollars more for RAM, CPU, SSD drives, and power supply. A good baseline would be Nvidia’s DGX-1 server, which is specialized for deep learning training and inference. At around $130,000, DGX-1 is short on VRAM (8×16 GB), but has all the other components for a solid performance on GPT-3.
- “We don’t have the numbers for GPT-3, but can use GPT-2 as a reference. A 345M-parameter GPT-2 model only needs around 1.38 GB to store its weights in FP32. But running inference with it in TensorFlow requires 4.5GB VRAM. Similarly, A 774M GPT-2 model only needs 3.09 GB to store weights, but 8.5 GB VRAM to run inference,” he said. This would possibly put GPT-3’s VRAM requirements north of 400 GB.
- https://twitter.com/marksaroufim/status/1701998409924915340
- Gave a talk on why Llama 13B won't fit on my 4090 - it's an overview of all the main sources of memory overhead and how to reduce each of them Simple for those at the frontier but will help the newbs among us back of the envelope VRAM requirements fast
- https://huggingface.co/spaces/hf-accelerate/model-memory-usage
Based on what we know, it would be safe to say the hardware costs of running GPT-3 would be between $100,000 and $150,000 without factoring in other costs (electricity, cooling, backup, etc.).
Alternatively, if run in the cloud, GPT-3 would require something like Amazon’s p3dn.24xlarge instance, which comes packed with 8xTesla V100 (32 GB), 768 GB RAM, and 96 CPU cores, and costs $10-30/hour depending on your plan. That would put the yearly cost of running the model at a minimum of $87,000.
training is syncrhonous (centralized) and is just a matter of exaflops https://twitter.com/AliYeysides/status/1605258835974823954?s=20 nuclear fusion accelerates exaflops
floating-point operations/second per $ doubles every ~2.5 years. https://epochai.org/blog/trends-in-gpu-price-performance For top GPUs at any point in time, we find a slower rate of improvement (FLOP/s per $ doubles every 2.95 years), while for models of GPU typically used in ML research, we find a faster rate of improvement (FLOP/s per $ doubles every 2.07 years).
computer requirements to train gpt4 https://twitter.com/matthewjbar/status/1605328925789278209?s=46&t=fAgqJB7GXbFmnqQPe7ss6w
human brain math https://twitter.com/txhf/status/1613239816770191361?s=20
- Let's say the brain is in the zettaFLOP/s range. That's 10^21 FLOP/s. Training GPT-3 took 10^23 FLOPS total over 34 days. 34 days has 2937600 seconds. 10^23/10^7 is about 10^16 FLOP/s. So by this back of the envelope computation the brain has about 4 orders of magnitude more capacity, or 1000x. This makes a lot of sense, they're using a pettaFLOP/s supercomputer basically which we already knew. We'll have zettaFLOP/s supercomputers soon, yottaFLOP/s, people are worried we're going to hit some fundamental physical limits before we get there. https://news.ycombinator.com/item?id=36414780
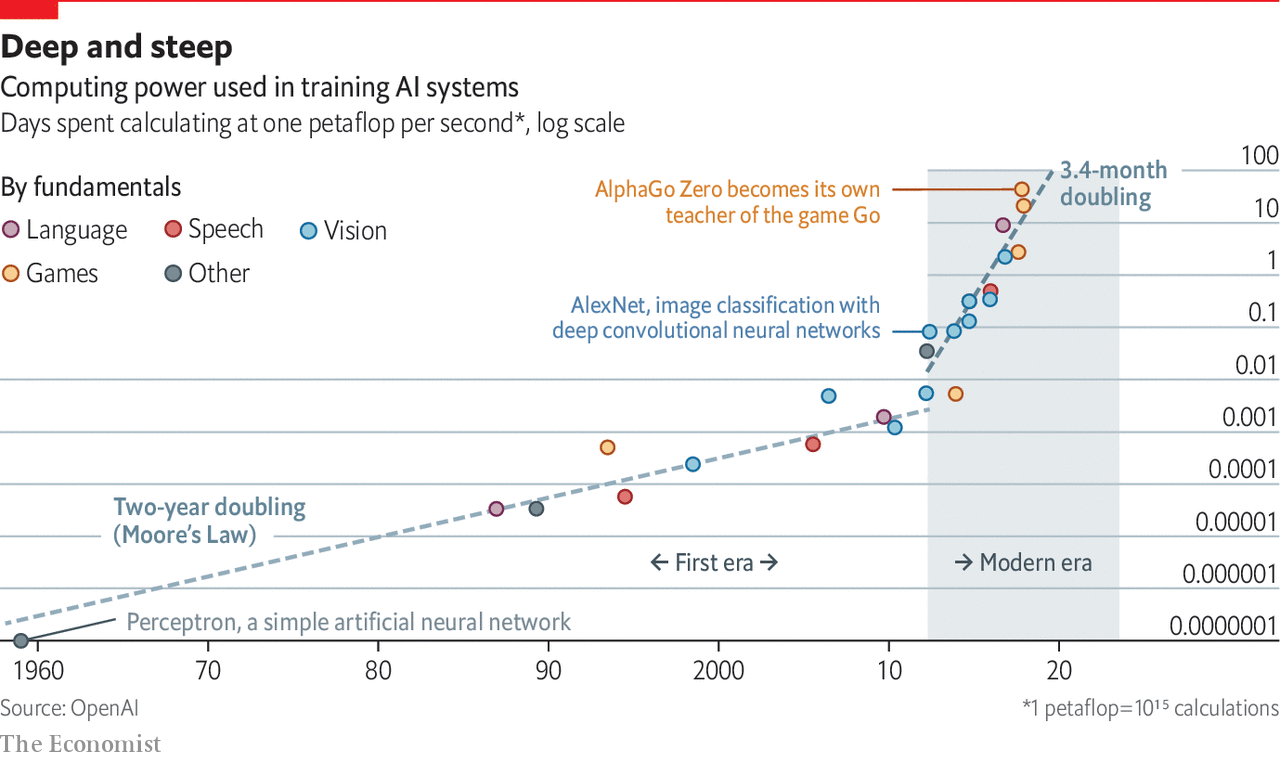
2018 - "ai and compute" report
https://www.lesswrong.com/posts/KrJfoZzpSDpnrv9va/draft-report-on-ai-timelines ajeya cotra https://www.alignmentforum.org/posts/AfH2oPHCApdKicM4m/two-year-update-on-my-personal-ai-timelines - reaction https://astralcodexten.substack.com/p/biological-anchors-a-trick-that-might - human brain 10^13 - 10^17 FLOP/S. Why? Partly because this was the number given by most experts. But also, there are about 10^15 synapses in the brain, each one spikes about once per second, and a synaptic spike probably does about one FLOP of computation. - Cars don’t move by contracting their leg muscles and planes don’t fly by flapping their wings like birds. Telescopes do form images the same way as the lenses in our eyes, but differ by so many orders of magnitude in every important way that they defy comparison. Why should AI be different? You have to use some specific algorithm when you’re creating AI; why should we expect it to be anywhere near the same efficiency as the ones Nature uses in our brains? - Good news! There’s a supercomputer in Japan that can do 10^17 FLOP/S! - reaction https://www.lesswrong.com/posts/ax695frGJEzGxFBK4/biology-inspired-agi-timelines-the-trick-that-never-works#__2020__ - summary https://www.lesswrong.com/posts/KrJfoZzpSDpnrv9va/draft-report-on-ai-timelines?commentId=7d4q79ntst6ryaxWD - human brain is doing the equivalent of 1e13 - 1e16 FLOP per second, with a median of 1e15 FLOP per second, and a long tail to the right. This results in a median of 1e16 FLOP per second for the inference-time compute of a transformative model.
- https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit
- In the case of the Lifetime Anchor hypothesis, I took the anchor distribution to be the number of total FLOP that a human brain performs in its first 1 billion seconds (i.e. up to age ~32); my median estimate is (1e15 FLOP/s) * (1e9 seconds) = 1e24 FLOP
- In the case of the Evolution Anchor hypothesis, I estimated the anchor distribution to be ~1e41 FLOP, by assuming about 1 billion years of evolution from the earliest neurons and multiplying by the average population size and average brain FLOP/s of our evolutionary ancestors
- assumed 2020 SOTA for cost was 1e17 FLOP/ $
- https://www.alignmentforum.org/posts/AfH2oPHCApdKicM4m/two-year-update-on-my-personal-ai-timelines#Making_a_one_time_upward_adjustment_for__2020_FLOP**\_**
-
- I was using the V100 as my reference machine; this was in fact the most advanced publicly available chip on the market as of 2020, but it was released in 2018 and on its way out, so it was better as an estimate for 2018 or 2019 compute than 2020 compute. The more advanced A100 was 2-3x more powerful per dollar and released in late 2020 almost immediately after my report was published.
- I was using the rental price of a V100 (~$1/hour), but big companies get better deals on compute than that, by about another 2-3x.
- I was assuming ~⅓ utilization of FLOP/s, which was in line with what people were achieving then, but utilization seems to have improved, maybe to ~50% or so.
cost
- nvidia - jensen huang - 1m times more powerful AI models in 10 years
- https://www.economist.com/technology-quarterly/2020/06/11/the-cost-of-training-machines-is-becoming-a-problem
- But people have been pouring more and more money into AI lately:
[

Source here. This is about compute rather than cost, but most of the increase seen here has been companies willing to pay for more compute over time, rather than algorithmic or hardware progress.
- https://twitter.com/AndyChenML/status/1611529311390949376
- “The supercomputer developed for OpenAI is a single system with more than 285,000 CPU cores, 10,000 GPUs and 400 gigabits per second of network connectivity for each GPU server.” training the original GPT3
- To put this in context some of the new clusters coming are over 10x more powerful, even more so when you consider scaling. Our original supercomputer from AWS last year is > 2x more poweful https://twitter.com/EMostaque/status/1612660862627762179?s=20
- @foldingathomeexceeded 2.4 exaFLOPS (faster than the top 500 supercomputers combined)!
- https://openai.com/blog/scaling-kubernetes-to-7500-nodes/
- aman sanger thread on understanding openai dedicated instances
https://twitter.com/pommedeterre33/status/1614927584030081025?s=46&t=HS-dlJsERZX6hEyAlfF5sw
- Petals "Swarm" network - https://github.com/bigscience-workshop/petals Run 100B+ language models at home, BitTorrent-style. Fine-tuning and inference up to 10x faster than offloading
- https://github.com/hpcaitech/ColossalAI Colossal-AI provides a collection of parallel components for you. We aim to support you to write your distributed deep learning models just like how you write your model on your laptop. We provide user-friendly tools to kickstart distributed training and inference in a few lines.
- Ray LLM usage https://news.ycombinator.com/item?id=34758168
- Alpa does training and serving with 175B parameter models https://github.com/alpa-projects/alpa
- GPT-J https://github.com/kingoflolz/mesh-transformer-jax
- Another HN thread on training LLMs with Ray (on TPUs in this case) https://news.ycombinator.com/item?id=27731168
- OpenAI fireside chat on the evolution of their infrastructure and usage of Ray for training https://www.youtube.com/watch?v=CqiL5QQnN64
- Cohere on their architecture for training LLMs https://www.youtube.com/watch?v=For8yLkZP5w&t=3s
- And we can make Ray more efficient by optimizing GPU hardware utilization https://centml.ai/
- DeepSpeed became popular soon after this post was originally published and is natively supported by many PyTorch training frameworks. https://www.deepspeed.ai
- 30b params can beat GPT175B - 5x cheaper to hose, 2x cheaper to train https://twitter.com/calumbirdo/status/1615440420648935445
- https://howmanyparams.com/
- Scaling Laws for Generative Mixed-Modal Language Models - Aghajanyan et. al
- @BigscienceW's first model (T0pp) is out! Highlights: 1/16th the size of GPT-3 but outperforms GPT-3 when prompted correctly
- sparseGPT https://arxiv.org/abs/2301.00774 When executing SparseGPT on the largest available open-source models, OPT-175B and BLOOM-176B, we can reach 60% sparsity with negligible increase in perplexity: remarkably, more than 100 billion weights from these models can be ignored at inference time.
- For single-GPU performance, there are 3 main areas your model might be bottlenecked by. Those are: 1. Compute, 2. Memory-Bandwidth, and 3. Overhead. Correspondingly, the optimizations that matter also depend on which regime you're in. https://horace.io/brrr_intro.html (tweet)
- RELATED hardware influencing pytorch design - compute-bound https://twitter.com/cHHillee/status/1601371638913638402?s=20
- bootstrapping data
- "Data engine" - use GPT3 to generate 82k samples for instruction tuning - generates its own set of new tasks, outperforms original GPT3 https://twitter.com/mathemagic1an/status/1607384423942742019
- "LLMs are Reasoning Teachers"
- https://twitter.com/itsnamgyu/status/1605516353439354880?s=20
- We propose Fine-tune-CoT: fine-tune a student model with teacher-generated CoT reasoning, inspired by Zero-shot CoT
- All of our experiments use public APIs from OpenAI on a moderate budget of just $50-200 per task. The code is already on GitHub
- mlperf optimization and mosaicml composer https://twitter.com/davisblalock/status/1542276800218247168?s=46&t=_aRhLI2212sARkuArtTutQ
- Google deep learning tuning playbook https://github.com/google-research/tuning_playbook vs eleuther https://github.com/eleutherAI/cookbook#the-cookbook

{kind=link}
{kind=link}
{kind=link}
https://www.artfintel.com/p/transformer-inference-tricks
- KV Cache
- Speculative decoding
- Effective sparsity
- Quantization https://www.artfintel.com/p/efficient-llm-inference on quantization
https://lmsys.org/blog/2023-11-21-lookahead-decoding/ lookahead decoding
https://lilianweng.github.io/posts/2023-01-10-inference-optimization/ scaling up inference
https://textsynth.com/ Fabrice Bellard's project provides access to large language or text-to-image models such as GPT-J, GPT-Neo, M2M100, CodeGen, Stable Diffusion thru a REST API and a playground. They can be used for example for text completion, question answering, classification, chat, translation, image generation, ... TextSynth employs custom inference code to get faster inference (hence lower costs) on standard GPUs and CPUs.
How well batching works is highly dependent on the request stream. But we can get an upper bound on its performance by benchmarking static batching with uniform requests.
batch sizes
| Hardware | 1 | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|---|
| 1x A10 | 0.4 (1x) | 1.4 (3.5x) | 2.3 (6x) | 3.5 (9x) | OOM (Out of Memory) error | ||
| 2x A10 | 0.8 | 2.5 | 4.0 | 7.0 | 8.0 | ||
| 1x A100 | 0.9 (1x) | 3.2 (3.5x) | 5.3 (6x) | 8.0 (9x) | 10.5 (12x) | 12.5 (14x) | |
| 2x A100 | 1.3 | 3.0 | 5.5 | 9.5 | 14.5 | 17.0 | 22.0 |
| 4x A100 | 1.7 | 6.2 | 11.5 | 18.0 | 25.0 | 33.0 | 36.5 |
Table 2: Peak MPT-7B throughput (req/sec) with static batching and a FasterTransformers-based backend. Requests: 512 input and 64 output tokens. For larger inputs, the OOM boundary will be at smaller batch sizes.
- https://www.anyscale.com/blog/continuous-batching-llm-inference
- Because LLMs iteratively generate their output, and because LLM inference is often memory and not compute bound, there are surprising system-level batching optimizations that make 10x or more differences in real-world workloads.
- One recent such proposed optimization is continuous batching, also known as dynamic batching, or batching with iteration-level scheduling. We wanted to see how this optimization performs. We will get into details below, including how we simulate a production workload, but to summarize our findings:
- Up to 23x throughput improvement using continuous batching and continuous batching-specific memory optimizations (using vLLM).
- 8x throughput over naive batching by using continuous batching (both on Ray Serve and Hugging Face’s text-generation-inference).
- 4x throughput over naive batching by using an optimized model implementation (NVIDIA’s FasterTransformer).
- https://hardwarelottery.github.io ML will run into an asymptote because matrix multiplication and full forward/backprop passes are ridiculously expensive. What hardware improvements do we need to enable new architectures?
- "bitter lessons" - http://incompleteideas.net/IncIdeas/BitterLesson.html https://twitter.com/drjwrae/status/1601044625447301120?s=20
- related: https://www.wired.com/2017/04/building-ai-chip-saved-google-building-dozen-new-data-centers/
- transformers won because they were more scalable https://arxiv.org/pdf/2010.11929.pdf
- Apple Neural Engine Transformers https://github.com/apple/ml-ane-transformers
see also asionometry youtube video
https://www.semianalysis.com/p/the-ai-brick-wall-a-practical-limit
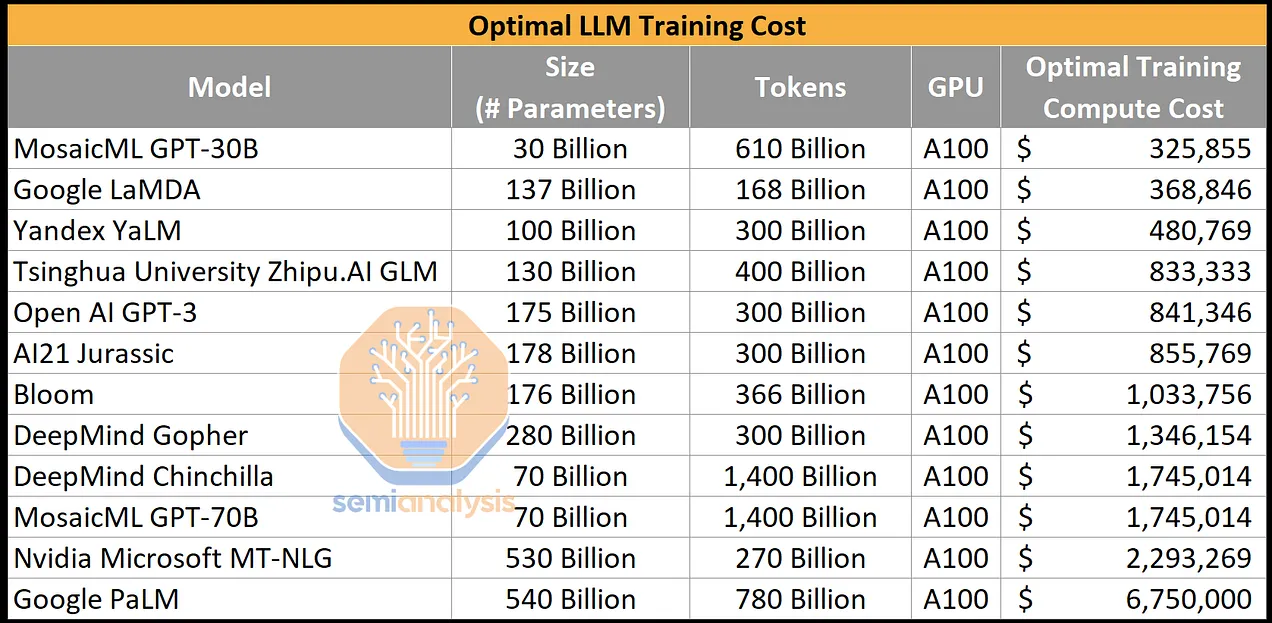
- We believe the cost to train a neural net will fall 2.5x per year through 2030. AND we expect budgets to continue to balloon, doubling annually at least through 2025. Combine the two: Neural net capability should increase by ~5,000x by 2025
- https://twitter.com/wintonARK/status/1557768036169314304?s=20
- https://ark-invest.com/wrights-law
- Moore’s Law – named after Gordon Moore for his work in 1965 – focuses on cost as a function of time. Specifically, it states that the number of transistors on a chip would double every two years. Wright’s Law on the other hand forecasts cost as a function of units produced.
- OpenAI scaling on compute https://openai.com/blog/ai-and-compute/
- Before 2012: It was uncommon to use GPUs for ML, making any of the results in the graph difficult to achieve.
- 2012 to 2014: Infrastructure to train on many GPUs was uncommon, so most results used 1-8 GPUs rated at 1-2 TFLOPS for a total of 0.001-0.1 pfs-days.
- 2014 to 2016: Large-scale results used 10-100 GPUs rated at 5-10 TFLOPS, resulting in 0.1-10 pfs-days. Diminishing returns on data parallelism meant that larger training runs had limited value.
- 2016 to 2017: Approaches that allow greater algorithmic parallelism such as huge batch sizes, architecture search, and expert iteration, along with specialized hardware such as TPU’s and faster interconnects, have greatly increased these limits, at least for some applications.
nvidia - jensen huang - 1m times more powerful AI models in 10 years
- https://www.pcgamer.com/nvidia-predicts-ai-models-one-million-times-more-powerful-than-chatgpt-within-10-years/?fbclid=IwAR0yGM7oTzG9IZcjcTbBaABWzVFh9_uflY7kTXRGj-0uaw4ll8oeCvsx7gw
- "Moore's Law, in its best days, would have delivered 100x in a decade," Huang explained. "By coming up with new processors, new systems, new interconnects, new frameworks and algorithms and working with data scientists, AI researchers on new models, across that entire span, we've made large language model processing a million times faster."
example
- https://twitter.com/ramsri_goutham/status/1604763395798204416?s=20
- Here is how we bootstrapped 3 AI startups with positive unit economics -
- Development - Google Colab
- Inference - serverless GPU providers (Tiyaro .ai, modal .com and nlpcloud)
- AI Backend logic - AWS Lambdas
- Semantic Search - Free to start vector DBs (eg: pinecone .io)
- Deployment - Vercel + Supabase
2009: Google ‘The unreasonable effectiveness of data. 2017: Deep learning scaling is predictable, empirically Hestness et al., arXiv, Dec.2017
We have three main lines of attack:
- We can search for improved model architectures.
- We can scale computation.
- We can create larger training data sets.
https://arxiv.org/abs/2001.08361 # Scaling Laws for Neural Language Models
- altho 2022 paper Predictability and Surprise in Large Generative Models has a nicer chart on compute, data, model size scaling
Predictability and Surprise in Large Generative Models
- DISTINGUISHING FEATURES OF LARGE GENERATIVE MODELS
- Smooth, general capability scaling
- Abrupt, specific capability scaling
- For arithmetic, GPT-3 displays a sharp capability transition somewhere between 6B parameters and 175B parameters, depending on the operation and the number of digits
- three digit addition is performed accurately less than 1% of the time on any model with less than 6B parameters, but this jumps to 8% accuracy on a 13B parameter model and 80% accuracy on a 175B parameter model
- Open-ended inputs and domains
- Open-ended outputs