add xgboost to benchmark #2
Comments
|
Yeah, I was planning to look at that via the R package when I get to boosting (in a few days). I'm doing now linear models as a baseline (but naturally poor accuracy). |
|
The accuracy of tree-based vs linear model depends on the type of data you are working on. If it is low dimensional categorical data or continuous case(which seems to be your case), tree-based model always work better, which was the case you are looking at. |
|
Yes, I know, my focus is credit card fraud, therefore the choice of the data/benchmark as described in the README. |
|
Thanks for the explaining this. In xgboost we do tackle categorical data via one-hot encoding. Though a sparse matrix format is supported and optimized for so it could be fast and memory efficient when you use input from a sparse matrix. If you would like to create a libsvm format of the inputs, there is a interesting new feature of external memory computing which could be tried. I am looking forward to see the results |
|
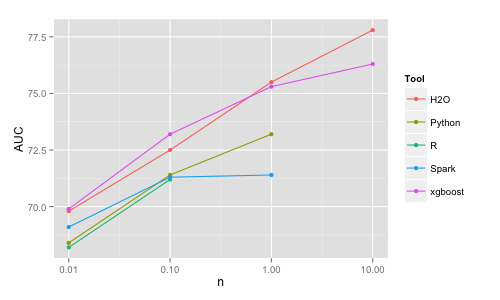
Ran xgboost to build random forests using the code provided by @hetong007. Looks good (see main README), but something weird happens for the largest data size (n=10M) - the trend for Run time and AUC "breaks", see figures main README. |
|
Thanks @szilard , I think I can explain that behavior. This is more about parameter setting issue. The thing is max_depth=20 was actually to complicated for such case. So as dataset grows from 1m to 10m. This actually causes the tool to grow deeper trees with more leaves (which cost more time in terms of one tree per datapoint and introduces overfitting) If you set min_child_weight to 10 in the 10m case. I guess things will become |
|
That sounds like a plausible explanation. However, I re-ran it with For comparison, without |
|
Thanks for running this. The min_child_weight do have an implicit impact on the running time, but seems not as much as I expected. I am less worried about the AUC drop, since it could due to random effect introduced in RF. |
|
Well, I think both run times and AUC matter. However, my main goal in this project is just to see which commonly used /out-of-the-box tools can train complex models (RF, boosting etc) on ~10 million observations, i.e. can finish in decent time (speed), not crash (running out of memory) and provide a reasonable accuracy. For this, for RF, xgboost satisfies all criteria :) Nevertheless, the shape of the trend line for AUC and especially for run time (compared to the trendlines of the other tools) is weird, see: Now, we can just say that's what it is. Or try to find out why, actually your guess sounded perfectly plausible, unfortunately it does not seem to be the case. Also notice the high AUC with H2O (for Anyway, thanks @hetong007 and @tqchen for contributing. If you guys have more ideas for RF happy to include/re-run. And hopefully, I'll get soon to evaluate boosting. |
{kind=link}
{kind=link}
|
I totally agree with you that both runtime and AUC matters. What I really mean is that there could be various reasons on difference in AUC. For example, difference in default parameter setting, variance in RF construction etc :) |
|
Yes. As I said before, this project is not a Kaggle :) I want to primarily see what tools pass a basic sanity check for 10M rows. I did little or no tuning, but in some way it would be interesting to see how the various methods can be tuned. Although I acknowledge this is just a toy dataset, so maybe not worth the effort. |
|
Thanks for the clarification! BTW, do you have any idea if there is any other dataset of such type for benchmarking? For example, a dataset with more columns and rows. One thing I noticed about this dataset is that seems the output was very dependent on one variable(when the features are randomly dropped at rate of 50%, one output tree could be very bad). This might make the result become a singular case where the result simply repeatively cut on a single feature. |
|
I now think the bump in running time was due to cache-line issues. As there are some non-consecutive going on xgboost. Having larger amount of rows could mean less cache hit rate, but the impact should not be large as this has things to do micro level optimization. I have pushed some optimization to do prefetching, which should in general improve the speed of xgboost. Would be great if you want to run another round of test. |
|
Moved this topic into a new issue here #14 |
Just discovered this repo. Since you are comparing gradient boosting algorithms, would be great if you could add https://github.com/dmlc/xgboost to comparison.
It also have a support for random forest.
Thanks
The text was updated successfully, but these errors were encountered: