d4rlpy MDPDataset #135
Comments
|
@cclvr Thanks for the issue. This is because MDPDatataset expects rewards |
|
Without this change, the algorithm performance will be significantly worse. |
Thanks a lot for your reply~ |
|
Thanks for the proposal! Actually, I'm working on an academic paper of this library and preparing v1.0.0 release. Once those things are done, I'll look for a way to add more OPE methods. BTW, I'm always happy for the contributions from users 😄 |
|
Hi, I thought the data collecting process of D4RL is the same with the commonly used method in online training, i.e., the transition is <s_t, a_t, r_t, s_t+1>. I thought the r_t indicates the reward at s_t after executing action a_t, while the reward is obtained at t+1. See code https://github.com/rail-berkeley/d4rl/blob/master/scripts/generation/mujoco/collect_data.py. I'm not sure if I understand this code correctly. I'm aprreciated if you could check D4RL codes again and discuss with me further |
|
In d3rlpy, that reward is considered to be got at t+1. This function tells the implementation difference. d3rlpy/d3rlpy/online/iterators.py Line 471 in 747b174 I believe I'm following Sutton book's notation. |
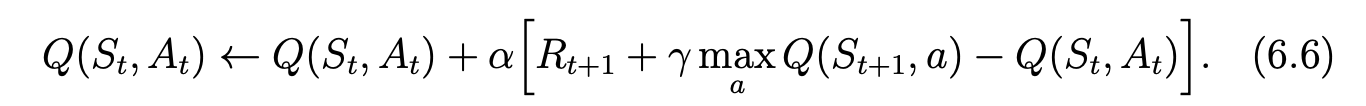
|
Picture from Sutton's book. |

|
Yes, but, it's at t+1. Anyway, don't worry, the implementation is correct. |
|
Hi @takuseno , through your discussion, I guess that d4rl collects data with the form (s,a,R(s,a)). Currently I' m reproducing bestDICE algorithm under d3rlpy framework, and collect data as d4rl does, i.e. (s,a,R(s,a)), and then use get_d4rl() to go on, but bestDICE does not work. Then I try to collect data as (s,a,R(s',a')), and amazingly, bestDICE works.!!!! This phenomena confuse me a lot, since if my implementation was right, then it means d4rl's was wrong, and vice versa. Do you have any idea about this? BTW, you referred to that 'algorithm performance will be significantly worse', can your point out which algorithms on which environments? Thanks a lot for your patient reply~ |
|
@cclvr Did you use https://d3rlpy.readthedocs.io/en/v0.91/references/dataset.html |
|
Regarding the performance, for example, |
|
Hi @takuseno Thanks for your replay, I maintain the same dataset form as d4rl and try transition.next _reward instead of transition.reward, then it works. It's my fault not to understand transition class correctly. Thanks again~ |
|
@cclvr Sounds good! To be honest, I'm considering changing the current dataset scheme to match D4RL because many people ask about this difference. Anyway, thanks for the issue! Please reopen this if you have a discussion about this issue. |
Hi @takuseno, firstly thanks a lot for such a high quality repo for offline RL.
I have a question about the method get_d4rl(), why the rewards are all moved by one step?
while cursor < dataset_size:
# collect data for step=t
observation = dataset["observations"][cursor]
action = dataset["actions"][cursor]
if episode_step == 0:
reward = 0.0
else:
reward = dataset["rewards"][cursor - 1]
Long for your feedback.
The text was updated successfully, but these errors were encountered: