{kind=link}
This is the official PyTorch implementation of our work: "Pixel-by-Pixel Cross-Domain Alignment for Few-Shot Semantic Segmentation" accepted at WACV 2022.
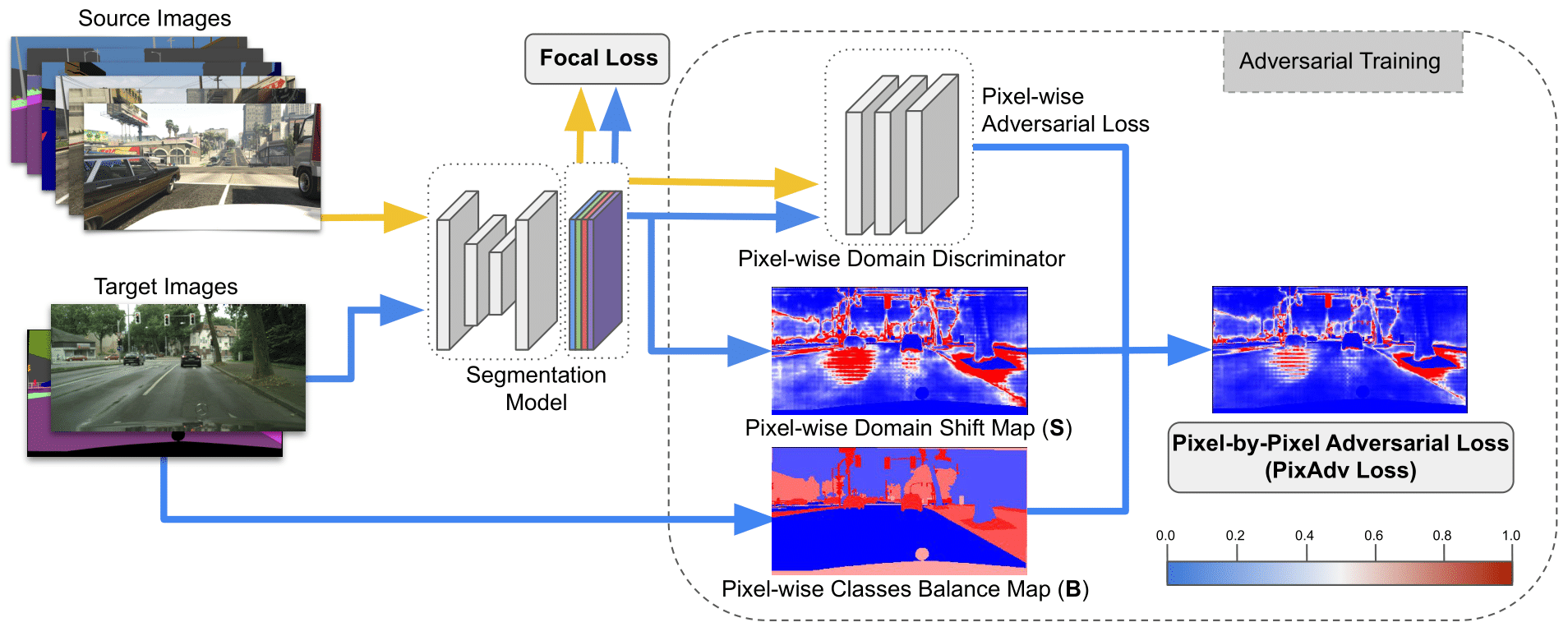
In this paper we consider the task of semantic segmentation in autonomous driving applications. Specifically, we consider the cross-domain few-shot setting where training can use only few real-world annotated images and many annotated synthetic images. In this context, aligning the domains is made more challenging by the pixel-wise class imbalance that is intrinsic in the segmentation and that leads to ignoring the underrepresented classes and overfitting the well represented ones. We address this problem with a novel framework called Pixel-By-Pixel Cross-Domain Alignment (PixDA).
[Paper] [Supplementary] [ArXiV]
To facilitate your work in installing all dependencies, we provide you the requirement (requirements.txt) file. This repository uses the following libraries:
- Python (3.7.10)
- Cuda (11.3)
- Pytorch (1.8.1)
- Torchvision (0.9.1)
- TensorboardX (2.2)
- Numpy (1.19.2)
- Scipy (1.6.2)
- Matplotlib (3.4.1)
- Pillow (8.2)
- ImageIO (2.9)
- Tqdm (4.60)
In this project we use three datasets, GTA5, SYNTHIA and Cityscapes. Download it from their official websites:
The most important file is run.py, that is in charge to start the training or test procedure. To run it, simpy use the following command:
python run.py --source_dataset <source_dataset> --source_dataroot <source_data_folder> --target_dataset <target_dataset> --target_dataroot <target_data_folder> --name <exp_name> --gpu_ids 0,1 --is_train --num_shots <1/2/3/4/5>
Leaving all the default parameters in the config.py file, you can replicate the experiments of the paper. Pretrained backbone and source only models for GTA5 and SYNTHIA can be found here (just unzip and copy the "pretrained_models" folder inside the models folder of the repository: link.
Train 1/2/3/4/5-shot for GTA to Cityscapes experiments:
python run.py --source_dataset gta5 --source_dataroot <source_data_folder> --target_dataset cityscapes --target_dataroot <target_data_folder> --name <exp_name> --gpu_ids 0,1 --is_train --num_shots <1/2/3/4/5>
Train 1/2/3/4/5-shot for SYNTHIA to Cityscapes experiments:
python run.py --source_dataset synthia --source_dataroot <source_data_folder> --target_dataset cityscapes --target_dataroot <target_data_folder> --name <exp_name> --gpu_ids 0,1 --is_train --num_shots <1/2/3/4/5>
Testing:
python run.py --source_dataset gta5 --source_dataroot <source_data_folder> --target_dataset cityscapes --target_dataroot <target_data_folder> --name <exp_name> --gpu_ids 0,1 --num_shots <1/2/3/4/5> --which_iter <model_iter_number_to_resume>
If you use this repository, please consider to cite us:
@InProceedings{Tavera_2022_WACV,
author = {Tavera, Antonio and Cermelli, Fabio and Masone, Carlo and Caputo, Barbara},
title = {Pixel-by-Pixel Cross-Domain Alignment for Few-Shot Semantic Segmentation},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2022},
pages = {1626-1635}}