Architecture
PhxSQL is a high-availability and strong-consistency MySQL cluster. PhxSQL is distinguished for its unique support of linearizable consistency, high availability, both of which are as strong as that of Zookeeper, and serializable isolation level of transaction.
PhxSQL consists of a master node and some slave nodes. With a quorum of nodes working, PhxSQL can provide an uninterrupted service.
PhxSQL is built on Percona 5.6, a branch of MySQL, therefore PhxSQL provides almost complete compliance with MySQL. MySQL can be easily replaced by PhxSQL without any change of client codes.
We use MySQL and Percona interchangeably for they are similar.
Most of MySQL cluster solutions risk data loss and therefore data inconsistency for loss-less replication between a master and slaves. Following are two typical cases:
- The binlog which is being replicated to the slaves before the master crashes, is called pending binlog. The status of the pending binlog is uncertain in a semi-sync system, and there is not a safe way to query the status of the pending binlog. When the master performs crash recovery, it don't known how to process the pending binlog. For example, if the pending binlog hadn't been replicated to any slaves, and a new master had been elected during the old master crashes, the old master should discard the pending binlog. And the situation could be reversed, the old master should commit the binlog.
- When the old master finish the crash recovery, MySQL client could continue to read from the old master, and receive the not up-to-date data.
There are some bug reports on these problems:
- semi-sync: incorrect crash recovery handling
- Enhanced semisync replication
- Phantom-read problem in semi-sync loss-less replication
We have published some articles about the defect of mysql replication (written in Chinese)
PhxSQL aims to solve this defect of MySQL replication and presents a MySQL cluster guaranteeing consistency and availability as strong as that of Zookeeper.
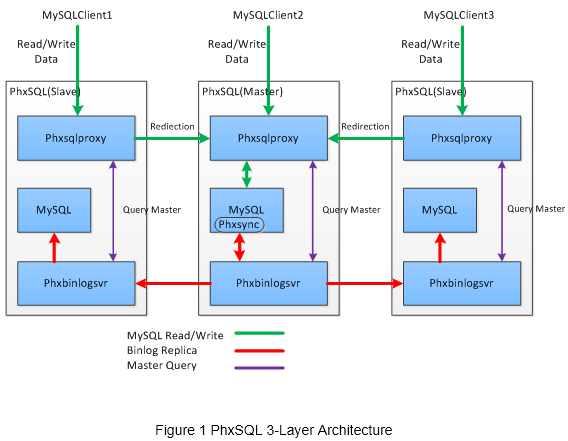
A PhxSQL node is composed of two modules(phxbinlogsvr, phxsqlproxy) and one MySQL plugin(phxsync_master), as figure 1 illustrated.
- phxbinlogsvr is responsible for MySQL binlog replication, MySQL health monitoring, and master election
- phxsqlproxy is responsible for forwarding requests to MySQL master
- phxsync_master plugin in MySQL master is responsible for intercepting and forwarding binlog to phxbinlogsvr
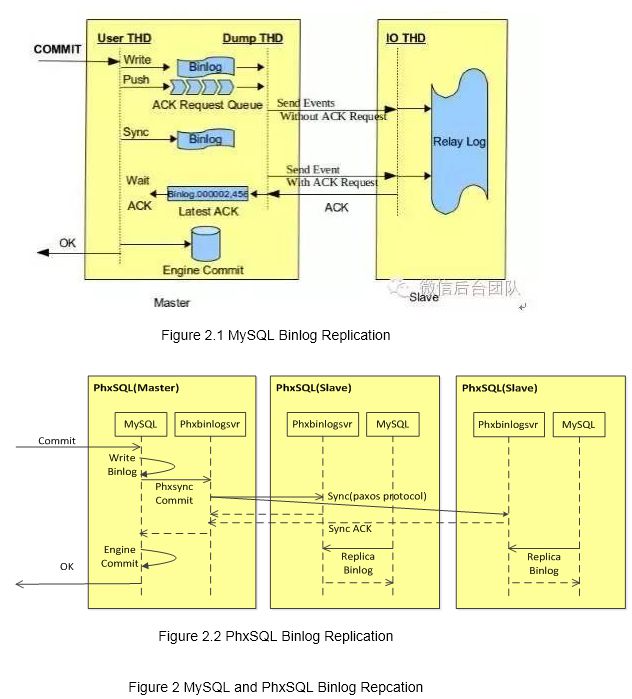
In PhxSQL, MySQL slaves will not pull binlog from MySQL master directly any more. The phxsync_master plugin intercepts and forwards binlog to a local phxbinlogsvr, the phxbinlogsvr sends it to phxbinlogsvrs on other PhxSQL nodes via Paxos, and MySQL slaves pull binlog from local phxbinlogsvrs.
HINT: PhxSQL team developed a in-house production-level Paxos library called PhxPaxos, which can be found on https://github.com/tencent-wechat/phxpaxos.
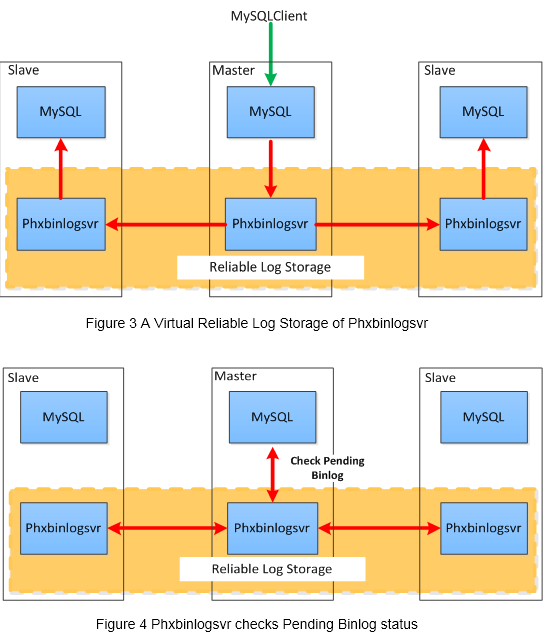
The cluster which is composed of multiple phxbinlogsvr can be regarded as a reliable log storage because it use Paxos protocol to replicate binlog among the multipile phxbinlogsvr. PhxSQL uses a reliable log storage to save MySQL's binlog, and the binlog will be global consistency. Every pending binlog can be queried from phxbinlogsvr to make sure whether it has been saved or not.
The process of the master and slave:
- Master: When the MySQL master performs crash recovery, the pending binlog is queried from phxbinlogsvr to decide whether to discard (truncate the binlog file) or to commit (apply to innodb). Like figure 4 shows.
- Slave: The binlog which slaves have received is accepted by Paxos protocol, it is global consistency. All slaves have same binlog, there are not pending binlog on slaves.
The pending binlog problem can been solved by the reliable log storage which is composed of multiple phxbinlogsvr.
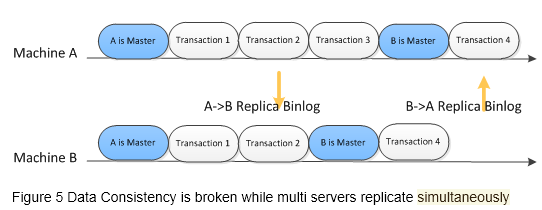
As a normal MySQL failover architecture:
- Host A crashes before the transaction 3 had been replicated to Host B
- Host B had been elected as a new master
- Host A was recovery
- The transaction 4 had been executed on Host B, and had been replicated to Host A
- The transaction 3 is missing
This defect dues to the incompleteness of the failover operations. Even by adding an extra service like ZooKeeper, it still doesn't work. It is not an atomic operation between master query and the operations which depends on the query results.
For example, Host A execute the following two operations:
- Host A got the master lock
- Execute a transaction and replicate binlog to slave
The Host A had been hung up for a long time before step 2, and during these time the Host B got the master lock, the problem is still existing.
This problem can been solved by using the Paxos for both binlog replication and master election. With Paxos, there is a total ordering for the binlog event and the master election event. For a complete discussion of this problem is very complex, we do not make more discussion in this article.
PhxSQL uses Paxos for both binlog replication and master election. The phxbinlogsvr as the agent of PhxSQL node will initiate master election, renew or check master lease periodically, check the progress of the binlog had been applied and switch MySQL's role as need.
Here are the principle of the PhxSQL master:
- All PhxSQL node are slave as the begining
- Phxbinlogsvr initiates a master election by using PhxPaxos library if the master lease is expired
- The master phxbinlogsvr renews lease periodically by using PhxPaxos library
- There is one master at the most or none
- Any binlog which is sent from expired master will be rejected
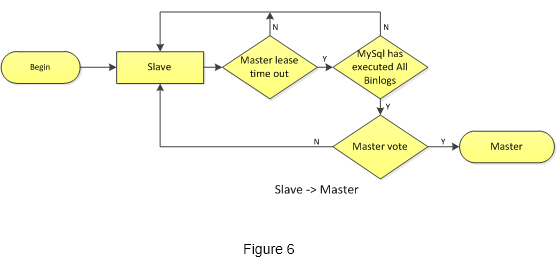
PhxSQL has a well-designed master switching process to guarantee data consistency during the master failover period. The details of the master switching process:
- Phxbinlogsvr on slave nodes check master lease periodically. Once master lease is expired, goto step 2;
- Phxbinlogsvrs goto step3 if the lastest binlog has been applied to local MySQL, else goto step1;
- Phxbinlogsvrs initiate a master election. One of the phxbinlogsvrs will been elected as master, and the new master will switch the local MySQL as master role (switch the "read-only" variable to "off"). The new master phxbinlogsvr gotos step4, other phxbinlogsvrs goto step1
- The master phxbinlogsvr keeps a master lease, and renews lease periodically;
- The old master gets the definitely status of the pending binlog from the phxbinlogsvr when it performs crash recovery, so it can decide to discard or to commit the pending binlog. If the new master has been elected, phxbinlogsvr will switch the local MySQL as slave role (switch the "read-only" variable to "on"), and configure the local MySQL to receive binlog from the local phxbinlogsvr.
PhxSQL solves the server side problem of failover by using phxbinlogsvr, because it can get the definitely status of the pending binlog from phxbinlogsvr and is switched role automatically by phxbinlogsvr. But there are still some problems at the client side:
- MySQL clients still send write requests to the expired master, and will been rejected by MySQL
- MySQL clients still send read requests to the expired master, and will read the not up-to-date data
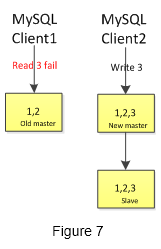
These two problems can not be avoid because MySQL clients are not able to gain the updated information about the master. A proxy has been added to address these problems in PhxSQL, that is called phxsqlproxy.
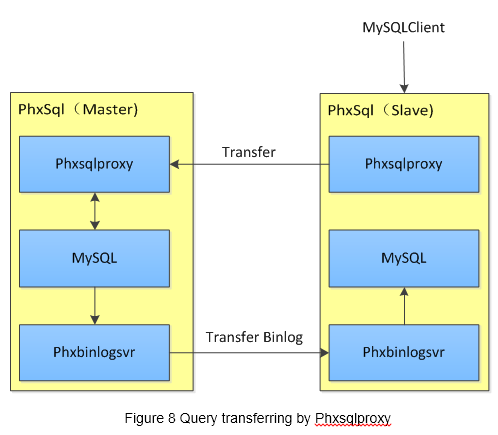
As figure 8 shows, any query to a slave Node will be transfered to the current Master Node by the phxsqlproxy. Consequently Phxsqlproxy ensure that the clients can be always executed queries on the current Master Node since there aren't more than 1 Master globally.
We used sysbench as a test tool to compare a performance difference between PhxSQL and MySQL semi-sync. Following is the result:
- Read: PhxSQL is slightly lower than MySQL semi-sync since there phxsqlproxy spends some CPU.
- Write: PhxSQL is better (15%~) than MySQL semi-sync since the implementing is more effectively.
| Read | Write | |||
|---|---|---|---|---|
| Client Threads | QPS | Avg Response Time | QPS | Avg Response Time |
| 200 | Decrease ~3% | Increase ~2% | Increase ~25% | Decrease ~20% |
| 500 | Decrease ~13% | Increase ~10% | Increase ~16% | Decrease ~10% |
-
Host Information
- CPU : Intel(R) Xeon(R) CPU E5-2420 0 @ 1.90GHz * 24
- Memory : 32G
- Disk : SSD Raid10
- Ping
- Master -> Slave : 3 ~ 4ms
- Client -> Master : 4ms
-
Tools And Arguments
- sysbench
- --oltp-tables-count=10
- --oltp-table-size=1000000
- --num-threads=500
- --max-requests=100000
- --report-interval=1
- --max-time=200
-
Test Content
- Apply different test sets between PhxSQL and MySQL semi-sync with different client threads.
- insert.lua (100% write queries)
- select.lua (0% write queries)
- OLTP.lua (20% write queris)
- Apply different test sets between PhxSQL and MySQL semi-sync with different client threads.
-
Result
Client Threads:200
| Test Clusters | Test Sets | |||||
|---|---|---|---|---|---|---|
| insert.lua | select.lua | OLTP.lua | ||||
| QPS | Response Time | QPS | Response Time | QPS | Response Time | |
| PhxSQL | 5076 | 39.34/56.93 | 46334 | 4.21/5.12 | 25657 | 140.16/186.39 |
| MySQL semi-sync | 4055 | 49.27/66.64 | 47528 | 4.10/5.00 | 20391 | 176.39/226.76 |
Client Threads:500
| Test Clusters | Test Sets | |||||
|---|---|---|---|---|---|---|
| insert.lua | select.lua | OLTP.lua | ||||
| QPS | Response Time | QPS | Response Time | QPS | Response Time | |
| PhxSQL | 8260 | 60.41/83.14 | 105928 | 4.58/5.81 | 46543 | 192.93/242.85 |
| MySQL semi-sync | 7072 | 70.60/91.72 | 121535 | 4.17/5.08 | 33229 | 270.38/345.84 |
| ** NOTE:The 2 values of Costs represent average costs and 95% percentile costs. The unit is MS.** |
PhxSQL has been solved the defects about MySQL replication and Master switching so that data remains consistent while master failover. Plus PhxSQL has a better writing performance than MySQL semi-sync replication although the reading queries perform slightly lower.