LSTM Object Detection Model Does Not Run #6253
Comments
|
I‘ve met the same "squeeze" issue with @wrkgm . I tried to comment the data augmentation options in config: then meet the error: |
@wrkgm I used this code to convert ImageNet VID 2015 to tfrecord, but get a different error:
|
|
One important point, I also faced an error saying: "the function ssd_random_crop requires argument groundtruth_weights" I fixed it by adding the "groundtruth_weights" and putting it equal to "None". Did you face the similar error? I thought that the current error might relate to it. |
|
@ashkanee Good point! I forgot I did face this error as well. I simply removed ssd_random_crop entirely from data augmentation options. Will edit main post to mention this, thanks |
I added the groundtruth_weights for ssd_random_crop and fixed the bug, but got the same error as you. Based on this, I guess that may not be the source of the problem. |
|
@dreamdragon Also, one more observation: 1- If I use the check point, I get the following error:
which seems that relates to GPU issues. 2- If I do not use the check point, I get the similar error as @wrkgm :
Based on the above, it seems your issue relates to the missing check point. Important point: Do you get warning on deprecated functions? I get them. May be the error is caused by deprecated functions in TensorFlow. This is probably worth working on. @wrkgm Can I ask you the following: 1- Can you please check what happens if you add the check point? I use the check point weights here 2- Is it possible for you to explain how you used "tf_sequence_example_decoder_test.py" to generate tfrecord files? Does it give separate training and validation files? Thanks! Edit: update: the error s most probably do not related to GPU Edit: |
|
@wrkgm Do you get the warning:
I guess it may help. Edit: Fixing this still results in the error. |
|
I looked into the tensors in the file seq_dataset_builder.py and noticed that the following tensors are empty:
In addition, I get one of the following errors each time (they appear in random order which seems to be related in the randomness of data augmentation part since they go away if you comment the data augmentation in the config file)
There are commands afterwards as tf.split and tf.squeeze and my understanding is that the errors are caused since empty tensors are being spitted or squeezed. |
|
@ashkanee I just modified the code from that file to generate a tfrecord full of randomly generated numpy arrays. I pointed the train path config at this. Haven't worried about splitting train and test yet, I'm just trying to get the code to run for anything at all. I tried with and without checkpoint and got similar error. It's almost certainly not related to the GPU. I've got a GTX 1070ti. And I get that same warning. I agree it likely has something to do with the input pipeline or preprocessing steps. |
|
While running train.py file from lstm_object_detection, I get the following error-
I figured out that there is something wrong with the config file in the lstm_object_detection. |
|
Replace object_detection.protos.lstm_model with lstm_object_detection.protos.lstm_model in the config. We will fix this issue in the codebase shortly. |
Done. Thanks.
PS- I have commented data augmentation option in the config file because it was giving me groundtruth_error As @ashkanee said, the problem seems to be coming from tensors in the file seq_dataset_builder.py, as the tensors are empty. Any help would be appreciated. |
|
I think I've found a solution. When trying to understand the scripts, I noticed that keys to features were specified in TFSequenceExampleDecoder and they were different from those in DatasetBuilderTest (seq_dataset_builder_test.py). So, I used a script for creating tf records similar to @wrkgm's first version, but replaced |
Did you successfully train the model? |
|
Well, not yet. I've just solved this tensorflow.python.framework.errors_impl.InvalidArgumentError and verified that it started to train (iterations shown in tensorboard) |
|
I do plan to train a model on my dataset - shall inform you here of the results |
On what dataset did you make the tfrecords? |
|
It's a specific dataset I use for my project. I can't tell the details, but in general, it is a set of annotated (boxes + labels) images organised in folders - one folder for one sequence. I just take each sequence, split it into snippets of length 4 (as specified in lstm_ssd_mobilenet_v1_imagenet.config) and convert each snippet into TF SequenceExample. |
Can we use the same tfrecords we used for objectdetection?
|
|
I haven't worked with object detection tfrecords, but I assume they are not SequenceExamples, but just Examples, and they don't have the required feature lists like |
So what do we have to edit in the lstm config file? what do we have to mention in the input path? |
|
I'm not fully sure we can use object detection tfrecords for training lstm object detection. If I'm right the seq_dataset_builder.py script wants SequenceExamples for training. Their length can be configured in lstm config file, but you can't replace them with Examples (and I assume, images in object detection datasets are stored independently as Examples) unless you modify the dataset builder itself. It may happen that I'm wrong, of course, as I don't know the exact object detection tfrecord format :) |
Yeah, I feel i went for wrong approach. |
|
I just have a single train.tfrecord file ( |
Iam trying to use tfrecords made out of oid dataset. |
|
I have used the pets_example.record from object_detection/test_data/ and also getting the same error. @mswarrow, @Aaronreb can you please send/attach your tfrecord file what u r using for training and evaluation of this lstm model (path/to/sequence_example/data). (e.g., it will be great if you can test how to generate tfrecord files for lstm model). I have tried @wrkgm code to build the sequential dataset tfrecords in order to train the model but I am getting the following error, tensorflow.python.framework.errors_impl.InvalidArgumentError: assertion failed: [All sequence lengths must match, but received lengths: 0 All sequence lengths must match, but received lengths: 0 All sequence lengths must match, but received lengths: 4] It seems like issue regarding the length mismatch. Can anyone please tell me what parameter to modify to resolve this issue? @mswarrow @Aaronreb @ashkanee @dreamdragon @whasyt can u please tell me what to add as fine_tune_checkpoint file. I have tried to add "object_detection/test_ckpt/ssd_inception_v2.pb" Any help will highly be appreciated. |
@KanaSukita |

|
@yuchen2580 |
@KanaSukita Maybe we should train a mobilenet ssd on VID dataset first, then train from that checkpoint as the paper suggests. And use video sequence of 10 for training the network. But I doubt this is the problem too... |
Did you train on the 86GB 2015 VID data?@KanaSukita. Can you share your conversion to tfrecord script? Also, did you have 'image/format' in sequential features or context features? |
Hi @Shruthi-Sampathkumar Not sure if it is right. import os from lxml import etree class_dict = { flags = tf.app.flags SETS = ['train', 'val', 'test'] def sample_frames(xml_files): def gen_shard(examples_list, annotations_dir, out_filename, def dicts_to_tf_example(dicts, root_dir, _set): # Get image pathsdef main(_): if name == 'main': |
Thanks @KanaSukita. I modified my script according to your's. My training is up and running now. |
Hi @Shruthi-Sampathkumar , did you successfully train the model? |
I was able to start the training, but the loss is stuck at 0.2955 @KanaSukita. I am not able to figure out the issue here. Maybe it is due to the num_classes. I have two non-background object classes. Should I include labels as 0 and 1 or 1 and 2 ? |
|
Do you sharing your config parameters such as shuffle_buffer_size, queue_capacity, prefetch_size, min_after_dequeue along with unroll length and video length? I think I would need to modify those. My network is not learning. @KanaSukita @yuchen2580 |
My config didn't get my network learning either. |
Should we convert labels to one hot encoding before converting to tfrecords? @KanaSukita @yuchen2580. |
|
My num_classes in config is 2 (I have two non-background classes). My input tfrecrd contains class indices : 0(for background), 1 and 2. I have enabled add_background_class. I am getting shape mismatch error between logits and labels : logits are (10,324,3) and labels are (10,324,2). May I know where I am going wrong? I am not able to understand why my target tensor is getting fed into the network as 2D. Thanks in advance for the help. |
It sounds like your model is assuming that there is a background class, but your labelmap does not. Are you configuring your labels such that it assumes that there is a background class (i.e. class index 0)? |
|
@KanaSukita @yuchen2580 thank you for providing the information |
|
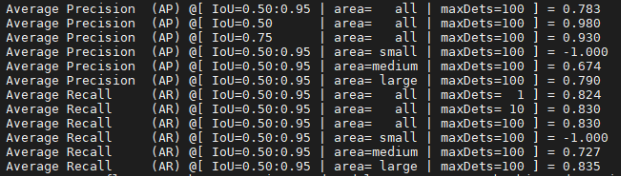
@KanaSukita @yuchen2580 I also trained the model on VID 2015 as well. The result is similar to yours. |
|
@poltavski @gtfaiwxm @Shruthi-Sampathkumar @KanaSukita FYI, if you are not using it for research, you can use another video detector to boost the speed as well as maintaining accuracy. |
|
@yuchen2580 Hello, I want to ask when can you complete the code check? |
@yuchen2580, @gtfaiwxm, @KanaSukita, Can you please share your conversion script for Imagenet-VID? |
@yuchen2580 |
|
@Enlistedman Hi, I meet the same problem, with the loss not converge. Have you figured out the problem? Any help would be appreciated. |
Sorry for the late reply. I did not solve this problem.Do you have any progress? |
Not yet |
|
@yuchen2580 @KanaSukita Did you successfully train the model? Any help would be appreciated. |
|
|
|
can you @gtfaiwxm or anyone that managed to train the model share the your labelMap for imagenetVID, I have issues when evaluationg because of the format. Thanks |
|
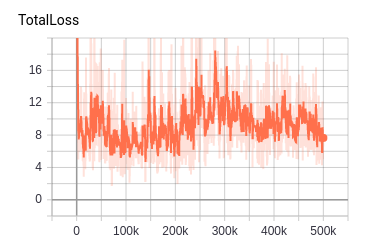
hi the network overfit on this small dataset that shows there is not problem in tfrecords... |

|
@amirzzzz Hi, could you pls share code you use for creating tfrecord from VID 2015, and your label_map? Thank you in advance |
|
can you tell me how to train lstm object detection code?I have no clue how to train it |
System information
Describe the problem
Training the LSTM object detection model does not work. After making a tfrecord, modifying the config as necessary, creating a training dir, and running the command, I get this error:
More documentation, including a simple example file of how to make a tfrecord and train, would be very helpful. I have tried two ways to create a tfrecord, both of which are shown below. I thought maybe the record structure is wrong, but if I put a typo in the record keys, I get a different error complaining about that, so perhaps I structured the records correctly. I tried looking at the model in tensorboard and modifying the training code in slim/learning.py to fetch values from individual nodes near Squeeze_1. I print the node, the output, and the shape of the output. Here are results from these attempts:
It seems that split_1 and ParseSingleSequenceExample are not actually receiving any data, and thus cause this squeeze error since there is nothing to squeeze. But resize image still gets data.
Additionally, if I ONLY fetch ResizeImage/resize_images/ResizeBilinear:0, I can fetch it a couple of times (repeatedly fetching in a loop), and then it fails. Perhaps the model fails after one batch?
I'm not sure if this counts a duplicate, but here are some related threads:
#6027
#5869
https://stackoverflow.com/questions/54093931/lstm-object-detection-tensorflow
I've also emailed the authors and heard nothing back.
EDIT:
I should mention, I removed ssd_random_crop from data augmentation options in the config because it was giving me an error "the function ssd_random_crop requires argument groundtruth_weights"
Not sure if this would matter at all
Source code / logs
I tried two ways of creating tfrecords. The first was taken from tf_sequence_example_decoder_test.py, in this repo. The only change was swapping to sequences of length 4 to match the config file.
I also tried adapting a method I found here: https://github.com/wakanda-ai/tf-detectors
For this I used a couple sample xml files in PASCAL VOC format from a training set I have for one of the normal object_detection models.
Tfrecords created with both of these approaches yielded identical errors.
The text was updated successfully, but these errors were encountered: