Number of AvgNumGroundtruthBoxesPerImage is always 100 #7469
Comments
|
i meet same priblem ,do you have solve it? |
|
Hi Zhangqian, |
|
This is due to a parameter in the If you set this from I'm not sure what the purpose of padding this is - there are references to this in the codebase, e.g. here. As it doesn't adversely affect training, I'd leave it on just in case. |
System information
Describe the problem
I am attempting to train the ssd_resnet_50_fpn_coco object detector on a simplified coco dataset, however the same issue persists even if I use the all coco classes. The metrics reported by tensorboard look off:
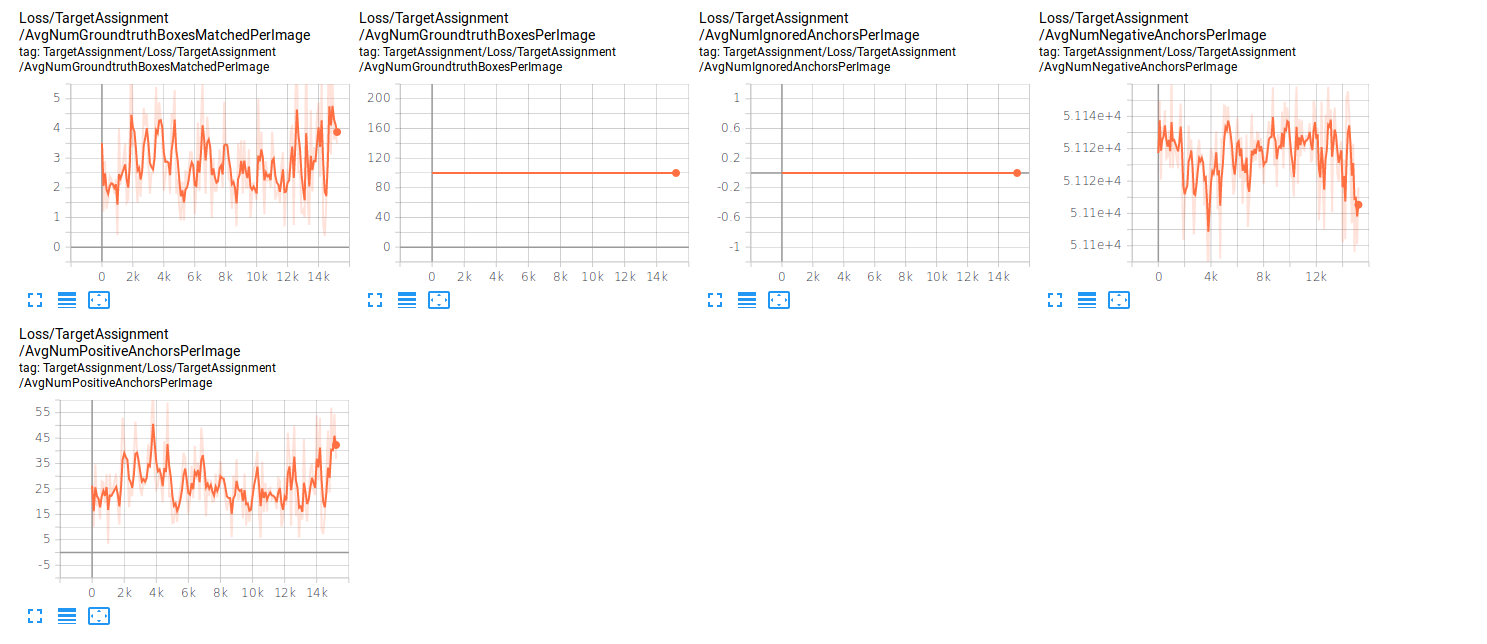
The number of AvgNumGroundtruthBoxesPerImage is always 100, the maximum number of output boxes from the model.
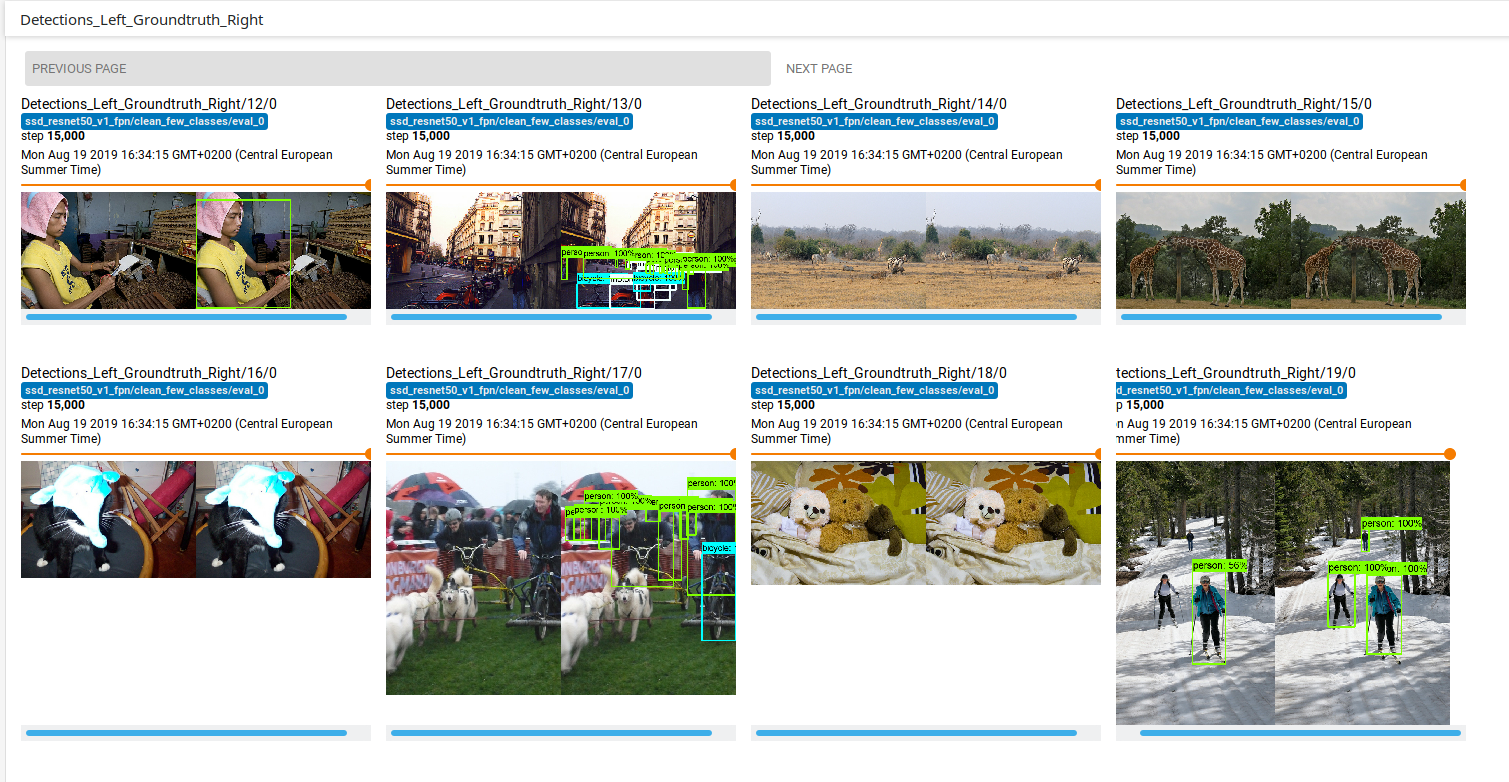
Indeed in the tensorboard display, there are some images with no GT bboxes:
While the loss in general decreases, the performance of the detector is very poor. After 15000 steps with a batchsize of 8:
The text was updated successfully, but these errors were encountered: