| layout | category | tags | title | |||
|---|---|---|---|---|---|---|
post |
database |
|
PostgreSQL&Greenplum Index Note |
PostgreSQL 目前支持8种索引接口,包括B-Tree, hash, gin, gist, sp-gist, brin, rum, bloom。
Greenplum 目前支持B-Tree, GiST, bitmap三种索引接口。 用户可以根据不同的数据类型,不同的请求类型,使用不同的索引接口建立相应的索引。例如对于数组,全文检索类型,可以使用GIN索引,对于地理位置数据,范围数据类型,图像特征值数据,几何类数据等,可以选择GiST索引。
PG的八种索引的介绍,可以参考bruce写的index internal、源码以及如下文档
一开始,让我们回顾一下在关系型数据库中什么是表.
关系型数据库中的数据表是多行(row)数组.与此同时每一行都多个单元(cells).在行中的单元数量和单元类型与Schema中的字段列信息一致.行数组有连续数字的RowId序列号.因此我们可以把表理解为(RowId, row)键值对的数组。
索引有着类似(row,RowId)键值对的反转关系.在索引行中必须包含至少一个单元(cell).很明显地,如果某行不唯一(两个完全一样的行).它们的关系看上去就像成套的RowId数组
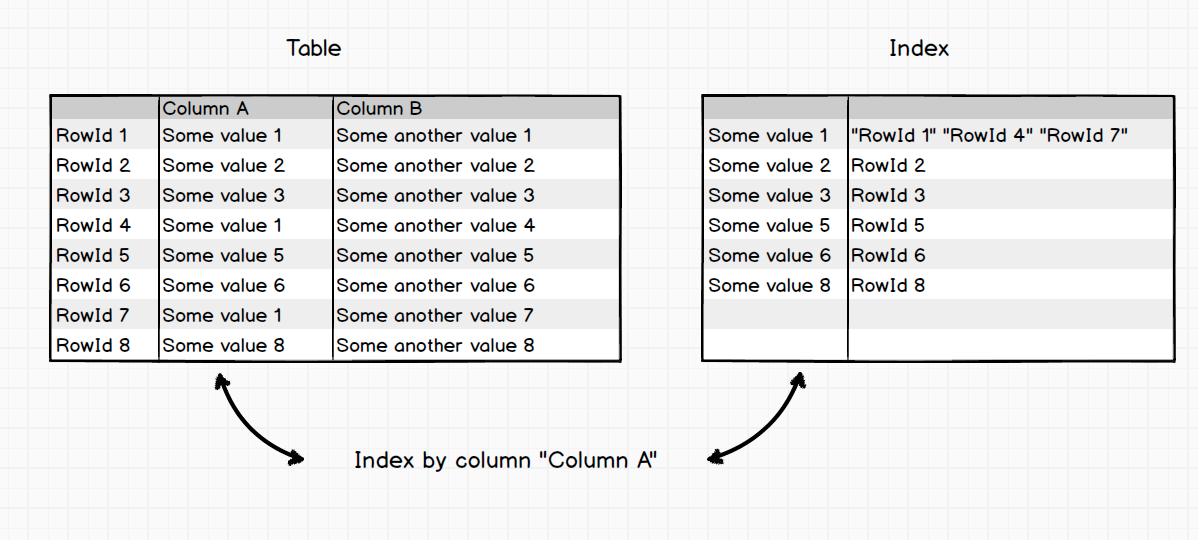
索引作为一个附加的数据结构,以下可以帮助我们理解:
- 数据检索 - 所有索引支持查询等于运算.部分索引还支持前缀搜索,及范围搜索
- 优化器 - B-Tree和R-Tree索引代表一种柱状图般的任意精确匹配
- Join - 索引器能被用于Meger,索引算法
- 关系 - 索引能用于排除/交叉计算
- 聚合 - 索引能有效地计算部分聚合函数(count, min, max等)
- 分组 - 索引能有效计算任意分组与聚合函数(分组排序算法)
PostgreSQL中有很多类型的索引器,用于不同的场景.让我们介绍一下所有这些索引器
B-Tree是当你执行CREATE INDEX时默认创建的索引.实际上几乎所有数据库都有对应的B-Tree索引.其中B代表平衡的(Boeing/Bayer/Balanced/Broad/Bushy-Tree),其含义是在二叉树的两边数据的数量大体上是相等的.因此叶子节点遍历寻找行的数量总是近似相等的.B-Tree索引在等于查询和范围查询中效率较高.它可以对所有数据类型操作,也能支持获取NULL值.B-Tree被设计工作在缓存,甚至仅仅是部分缓存
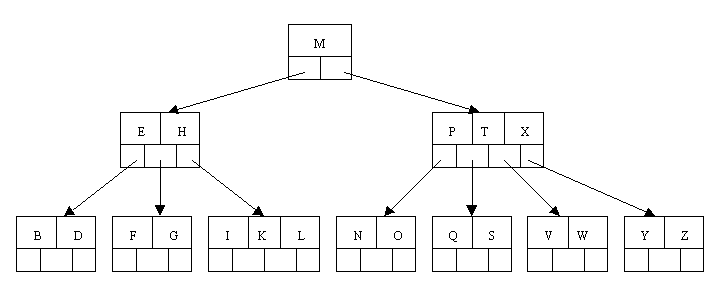
Advantages:
- 保持有序的数据
- 支持针对一元和二元运算的查询
- 允许全部序列的数据对整个索引,包括范围的估算基数和无需全表扫描的任意精确匹配
Disadvantages:
- 要求对所有数据创建全部的键值对(row, RowId)排序,比较费时
- 占用磁盘空间较大.索引对唯一的整型值字段计算两次,相比列字段,附加的RowId也需要存储
- 随着时间的推移,访问时间的增加源于磁盘信息的不断增加,从开始存储数据比较稀疏,到不停地更新不平衡的树信息,磁盘信息不断增加. 这也就是为什么B-Tree索引需要定期的重建.
R-Tree(矩形树)索引存储类似坐标的数值型键值对(X,Y).R-Tree非常类似于B-Tree.唯一的不同在于信息写在树的中间页里.相比第i个B-Tree节点,我们写的大多数都在第i个子树之外.在R-Tree中这是最小单位的矩形,包含所有子个矩形.细节可以查看:
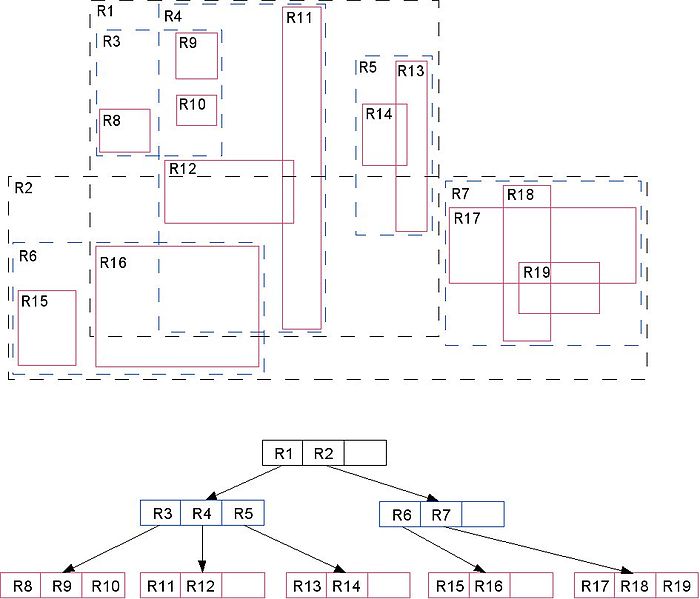
Advantages:
- 查询任意区域,及坐标点的数据
- 允许在没有全表扫描的情况下估算一定区域内的坐标点的数量
Disadvantages:
- 明显的数据冗余存储
- 更新数据比较缓慢
哈希索引使用哈希值来代替数值的存储.在这种情况下,使用哈希索引查询并不是比较对应字段的值,而是在哈希表中比较哈希值.
因为哈希函数是非线性的,该类索引是不能排序的.这导致其无法用于比较大小和判断"IS NULL"值.另外,既然哈希是非唯一的,其匹配的哈希值可能存在冲突.
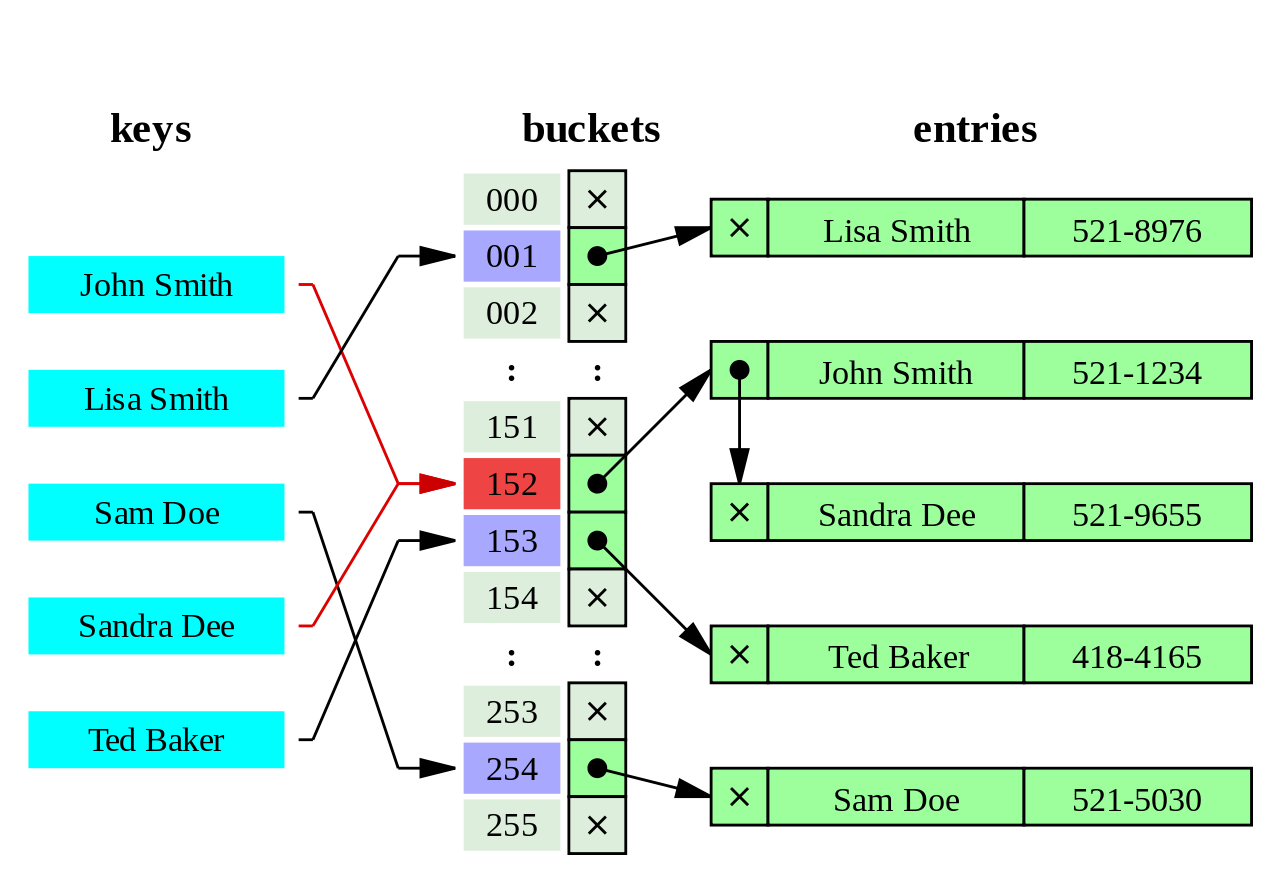
Advantages:
- 查询非常迅速,时间复杂度O(1)
- 稳定 - 该索引不需要重建
Disadvantages:
- 哈希对冲突是非常敏感的.在不良的数据分布情况下,大多数的数据输入都集中在部分集合中,事实上这种查询是通过冲突解决方式来完成
正如你所见,哈希索引仅对等于比较查询有效,但你决不想用它,因为它不是事务安全的,在哈希碰撞后需要手工重建
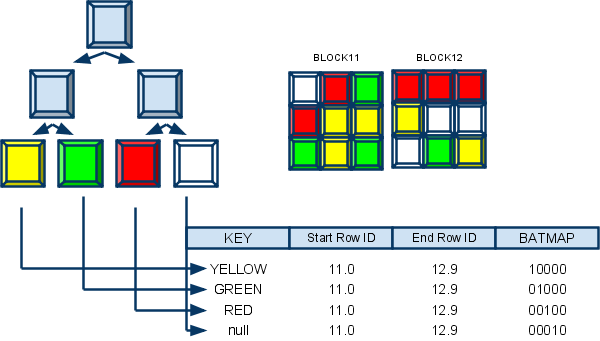
Bitmap索引创建一个对列中每个可能的值的独立的bit映射(0和1的序列),每个bit对应一个被索引的值.Bitmap索引最好用于针对可以转化为bit唯一值的查询(例如,性别,城市等).不同的值的数量建议从1-100之间较合适
Advantages:
- 压缩存储表示(较小磁盘空间)
- 迅速读取与查询'is'断言
- 对packing masks的有效算法
Disadvantages:
- 在更新数据过程中用户不能改变编码值的方法.因此如果分布的数据值改变,该索引需要被完全重建.
PostgreSQL不提供固定的bitmap索引.但该索引能用在多个索引结合的情况.PostgreSQL扫描每个需要的索引并在内存中准备一个bitmap,提供在表行中满足索引条件的数据位置.这bit映射的交并关系可一起被查询.
泛化检索树(GiST树)索引允许用户创建通用平衡二叉树结构,能被用于超出等于和范围比较的计算操作. 这树结构是固定不变的,对于每个节点对所存储的值(页面值)和每个节点的子节点数量.
其核心差异依赖于对key的组织.B-Tree树针对查询范围的锐化,并保存最大化的子树.R-Tree是用于描述一个坐标平面内某个区域.GiST提供包含必要信息的非叶子节点的数值,这将判断用户是否能获取所需要满足条件的值.这特定信息存储方式依赖于用户需要的查询方式.参数化的R-Tree和B-Tree树专攻task index(例如:PostGiST, pg_trgm, hstore, ltree).它被用于索引几何数据类型,如同全文检索
Advantages:
- 高效查询的效果
- 空间索引
Disadvantages:
- 大量的数据冗余
- 需要对每个查询组进行特定的实现
其余的正反面(pros-cons)类似于B-Tree和R-Tree.
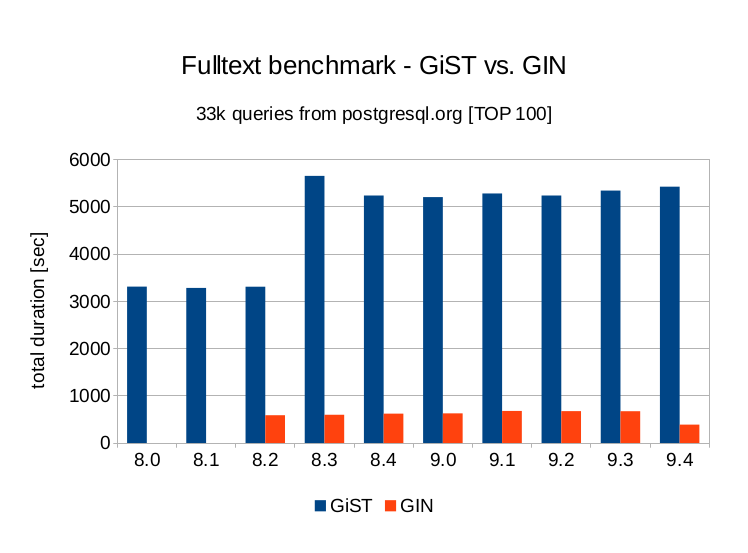
泛化反转索引(GIN)是非常有用的,用于一个索引必须映射很多值到一列里,相比B-Tree索引是针对单个key-value值的优化.GINs是很擅长索引数组值,类似于实现全文检索.PostgreSQL 数组支持GIN索引,可以实现快速的检索。
Key features:
- 非常适合于全文检索
- 寻找完全匹配,而非模糊匹配
- 非常适合于半结构化数据检索
- 允许用户执行多个不同的检索在一个语句中
- 应用范围相比GiST更大,支持大数据量
- 对频繁反复出现的元素的处理非常好
- 使用GIN索引时,使用BITMAP scan方式
PostgreSQL还支持全文检索类型,你可以存储为tsvector,使用tsquery进行查询
postgres=# create table gin_test(c1 tsvector);
CREATE TABLE
postgres=# create index idx_gin_test on gin_test using gin (c1) ;
CREATE INDEX
- trgm插件
GIN Index+Bitmap Index Scan
create index idx_tbl_1 on tbl using gin(info gin_trgm_ops);RUM索引接口:对全文检索的支持更加强大,不需要SORT,直接走INDEX SCAN的接口.
postgres=# create table rum_test(c1 tsvector);
CREATE TABLE
postgres=# CREATE INDEX rumidx ON rum_test USING rum (c1 rum_tsvector_ops);
CREATE INDEX
- 实现了<=>即文本相似度的属性检索
- rum检索支持近似度排行
- 支持非BITMAP scan方式,直接走INDEX SCAN
BRIN索引代表块区域索引,存储metadata在一定范围的页面中.这意味着每个数据块的最小值与最大值.
这结果表明BRIN不是很昂贵的索引,占用很小的空间,并对非常巨大的表的查询加速.允许该索引可判断哪些块需要被检索,其他的可被跳过,避免全表扫描. BRIN索引依然比普通的BTree索引慢在同一列情况下,但其优点在于占用更小的空间且更少的维护.
更多关于BRIN索引信息,请查看以下文章: BRIN article.
部分索引指仅覆盖一个表数据的子集.该索引与WHERE共同使用.这个方法是用来增加在减少空间的情况下提高查询效率.
例如:
CREATE INDEX access_log_client_ip_ix ON access_log (client_ip)
WHERE (client_ip > inet '192.168.100.0' AND
client_ip < inet '192.168.100.255');
SELECT * FROM access_log WHERE client_ip = '192.168.100.45';
该索引能保存相对小,也能用于更加复杂的查询中.
Expression indexes are useful for queries that match on some function or modification of your data. Postgres allows you to index the result of that function so that searches become as efficient as searching by raw data values.
表达式索引非常有用,当需要查询部分函数或转换时.PostgreSQL允许用户索引函数的结果,因此其查询效率与直接查询原数据一样高效.
例如:
CREATE INDEX users_name_first_idx ON foo ((lower(substr(name, 1, 1))));
SELECT * FROM users WHERE lower(substr(name, 1, 1)) = 'a';唯一键索引保证表不可出现超过一个完全一样的行.其有两个好处:数据一致性和查询性能.基于唯一键索引的查询通常是非常快的.
唯一键索引和唯一键约束的区别不大.唯一键约束不能用于表达式索引或部分索引(partial indexes),相比在表达式中使用部分唯一键索引是可能的.
Postgres有能力创建多列索引,这是非常重要的.Postgres的查询计划能够结合并使用多个单列索引在一个多列查询中,通过bitmap索引扫描方式.通常来说,用户能在每一列上创建索引,在大多数情况下Postgres能应用索引,但必须确保其效果在创建之前.索引总是有成本的,多列索引只能在索引顺序相同的情况下优化查询
有部分情况下使用多列索引是明显有意义的. 例如索引应用在列(a,b)的查询,包含WHERE a = x AND b = y,或 WHERE a = x,但不包含WHERE b = y.这种情况下,多列索引是值得被考虑的.
PostgreSQL优化器计算并行度及如何决定使用并行
1、确定整个系统能开多少worker进程(max_worker_processes)
2、计算并行计算的成本,优化器根据CBO原则选择是否开启并行(parallel_setup_cost、parallel_tuple_cost)。
3、强制开启并行(force_parallel_mode)。
4、根据表级parallel_workers参数决定每个查询的并行度取最小值(parallel_workers, max_parallel_workers_per_gather)
5、当表没有设置parallel_workers参数,并且表的大小大于min_parallel_relation_size时,由算法决定每个查询的并行度。
Greenplum 目前支持B-Tree, GiST, Bitmap三种索引接口。
GP主要做快速有序地扫描(基于分区) 如果建立全局索引,数据分布机制和分区机制,会完全打乱索引。
如之前PostgreSQL Bitmap图所示,bitmap索引将每个被索引的VALUE作为KEY,使用每个BIT表示一行,当这行中包含这个VALUE时,设置为1,否则设置为0。
如何从bitmap 索引检索数据,并查找到对应HEAP表的记录呢?
必须要有一个mapping转换功能(函数),才能将BIT位翻译为行号。例如第一个BIT代表第一行,。。。以此类推。(当然了,mapping函数没有这么简单,还有很多优化技巧)
bitmap的优化技术举例,比如:
-
- 压缩 例如连续的0或1可以被压缩,具体可以参考WIKI里面关于BITMAP的压缩算法,算法也是比较多的。
-
- 分段或分段压缩 例如,每个数据块作为一个分段,每个分段内,记录这个数据块中的VALU对应的BIT信息。
-
- 排序 排序是为了更好的进行压缩,例如堆表按被索引的列进行排序后,每个VALUE对应的行号就都是连续的了,压缩比很高。
另外用户也可以参考一下roaring bitmap这个位图库,应用非常广泛,效果也很不错。
roaring bitmap-1 roaring bitmap-2
从bitmap index的结构我们了解到,被索引的列上面,每一个value都分别对应一个BIT串,BIT串的长度是记录数,每个BIT代表一行,1表示该行存在这个值,0表示该行不存在这个值。 因此bitmap index索引的列,不能有太多的VALUE,最好是100到10万个VALUE,也就是说,这样的表的BITMAP索引有100到10万条BIT串。 当我们对这个表的这个字段进行类似这样的查询时,效率就非常高。
select * from table where col = a and col = b and col2=xxx;
-- a,b的bit串进行BITAND的操作,然后再和col2=xxx的BIT进行BITAND操作,返回BIT位为1的,使用bitmap function返回行号,取记录。
select count(*) from table where col = a and col = b and col2=xxx;
-- a,b的bit串进行BITAND的操作,然后再和col2=xxx的BIT进行BITAND操作,返回BIT位为1的,使用bitmap function返回行号,取记录,算count(*)。- 1.适合有少量不重复值的列
- 2.适合多个条件的查询,条件越多,bit and,or 的操作过滤掉的数据就越多,返回结果集越少。
由于每个VALUE都要记录每行的BIT位,所以如果有1亿条记录,那么每个VALUE的BIT串长度就是1亿。如果有100万个不同的VALUE,那么BITMAP INDEX就有100万个长度为1亿的bit串。
- 1.不适合有太多不重复值的表字段。
- 2.同样,也不适合有太少不重复值的列,例如男女。这样的列,除非可以和其他列组合赛选出很少量的结果集,否则返回的结果集是非常庞大的,也是不适合的。
- 3.不适合频繁的更新,因为更新可能带来行迁移,以及VALUE的变化。如果是行迁移,需要更新整个bitmap串。如果是VALUE变化,则需要修改整个与变化相关的VALUE的BIT串。
- gptext.search()
- GPText2.3.1