Web Scraping, Web Harvesting, ou Web Data Extraction são nomes dados às tècnicas de raspagem de dados utilizadas para extrair dados de sites. O software de scraping da Web pode acessar a World Wide Web (WWW) diretamente usando o Hypertext Transfer Protocol (HTTP) através de uma linguagem de programação, ou até mesmo através de um navegador da Web.
Embora Web Scraping possa ser feito manualmente por um usuário de software, o termo geralmente se refere a processos automatizados implementados usando um bot ou web crawler. É uma forma de cópia, na qual dados específicos são coletados e copiados da Web, geralmente em um banco de dados ou planilha, para recuperação ou análise posterior.
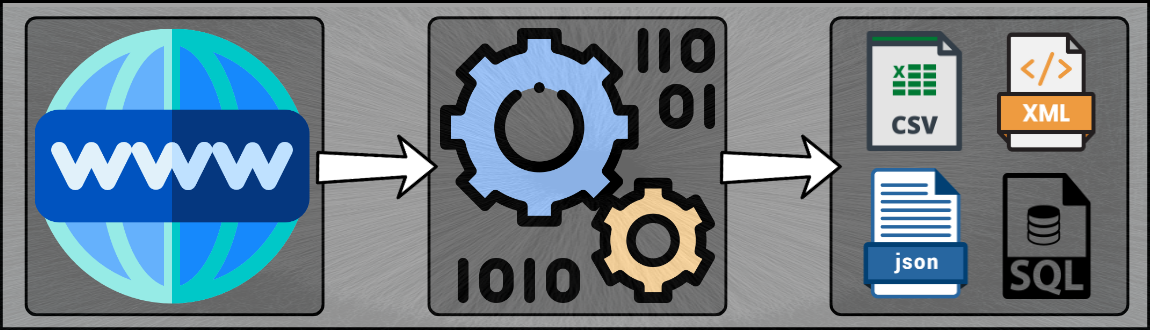
O Web Scraping de uma página web envolve buscá-la e extraí-la. Buscar é a ação de fazer download de uma página (o que um navegador faz quando você visualiza a página). O web crawling é um componente principal dentro do contexto de Web Scraping, para buscar páginas para processamento posterior. Uma vez obtida a página, a extração dos dados pode ocorrer. O conteúdo de uma página pode ser analisado, pesquisado, reformatado, seus dados copiados para uma planilha e assim por diante.

O Web Crawler, também muito conhecido por Spider é uma inteligência artificial que navega na Internet para indexar e pesquisar conteúdo seguindo links e explorando, como uma pessoa com muito tempo em suas mãos.

O Web Scraper é uma ferramenta projetada para extrair com precisão e rapidez os dados de uma página da web. Os Web Scrapers variam muito em design e complexidade, dependendo de cada projeto e sua necessidade.
Web scraping é muito usado para raspagem de contatos e, como componente de aplicativos usados para indexação na Web, mineração na Web e mineração de dados, monitoramento online de alterações de preços e comparação de preços, raspagem de revisão de produtos (para assistir à competição), coleta de anúncios imobiliários, dados de monitoramento climáticos, detecção de alterações no site, pesquisa, rastreamento da presença e reputação online, e integração de dados da web.
As páginas da Web são criadas usando linguagens de marcação baseadas em texto (HTML e XHTML) e frequentemente contêm uma grande quantidade de dados úteis em forma de texto. No entanto, a maioria das páginas da web é projetada para usuários finais humanos e não para facilitar o uso automatizado. Por esse motivo, foram criados kits de ferramentas que raspam o conteúdo da Web. Um Web Scraper é uma API (Application Programming Interface) para extrair dados de um site. Empresas como Amazon AWS e Google fornecem ferramentas, serviços e dados públicos disponíveis, gratuitamente, para os usuários finais.
- Após o nascimento da World Wide Web em 1989, o primeiro robô da Web: World Wide Web Wanderer foi criado em junho de 1993, com o objetivo de medir apenas o tamanho da Web.
- Em dezembro de 1993, o primeiro mecanismo de pesquisa na Web baseado em um Crawler foi chamado de JumpStation. Como não havia muitos sites disponíveis na Web, os mecanismos de pesquisa da época costumavam contar com os administradores humanos de sites para coletar e editar os links em um formato específico. O JumpStation deu um novo salto. É o primeiro mecanismo de pesquisa da WWW que depende de um robô da web.
- No ano 2000 surgiu a primeira Web API e consequentemente o primeiro crawler de API's. API significa Application Programming Interface. É uma interface que facilita muito o desenvolvimento de um programa, fornecendo os blocos de construção. Em 2000, o Salesforce e o eBay lançaram sua própria API, com a qual os programadores foram habilitados a acessar e baixar alguns dos dados disponíveis ao público. Desde então, muitos sites oferecem APIs da web para que as pessoas acessem seus bancos de dados públicos.
- Em 2004, Beautiful Soup foi lançado. É uma biblioteca projetada para Python. Como nem todos os sites oferecem APIs, os programadores ainda estavam trabalhando no desenvolvimento de uma abordagem que pudesse facilitar a raspagem da Web. Com comandos simples, Beautiful Soup pode analisar o conteúdo de dentro do contêiner HTML. É considerada a biblioteca mais sofisticada e avançada para raspagem da Web, e também uma das abordagens mais comuns e populares atualmente.
Web Scraping é o processo de mineração automática de dados ou coleta de informações da World Wide Web. É um campo com desenvolvimentos ativos que compartilham um objetivo comum com a visão semântica da web, uma iniciativa ambiciosa que ainda exige avanços no processamento de texto, entendimento semântico, inteligência artificial e interações homem-computador. As soluções atuais de Web Scraping variam desde o ad-hoc, exigindo esforço humano, a sistemas totalmente automatizados, capazes de converter sites inteiros em informações estruturadas, com limitações.
Copiar e colar humano: Às vezes, mesmo a melhor tecnologia de Web Scraping não pode substituir o exame manual de um ser humano e copiar e colar, e às vezes essa pode ser a única solução viável quando os sites de raspagem estabelecem explicitamente barreiras para impedir a automação da máquina.
Correspondência de padrões de texto: Uma abordagem simples, porém poderosa, para extrair informações de páginas da Web pode ser baseada no comando grep do UNIX ou nos recursos de correspondência de expressões regulares das linguagens de programação (por exemplo: Perl, Python, Go).
Programação HTTP: As páginas da Web estáticas e dinâmicas podem ser recuperadas através de solicitações HTTP no servidor da Web remoto.
Análise de HTML: A análise de HTML é basicamente: capturar o código HTML e extrair informações relevantes, como o título da página, parágrafos da página, títulos da página, links, texto em negrito etc.
Python é uma linguagem muito utilizada para Web Scraping, você pode conferir Web Scraping Python para conhecer a lista de diversas Bibliotecas relacionadas a Web Scraping e processamento de dados em Python.