F1 and F1-PA #34
Comments
|
Another paper that might be relevant is from Wu and Keogh that discusses the problems of current time series benchmarks, but also touches on problems of the evaluation. There are also range-based metrics, that view both the anomalies and predictions as ranges. I agree that PA should not be used because of its apparent flaws. The community should go back to report the unadjusted scores + a new range-based metric (e.g., eTaPR). I also did a comparison with other SOTA unsupervised approaches for SMD.
However, looking at the anomaly scores DIF doesn't look like the best method. The following image shows the anomaly scores for host 2-5 of SMD. Some anomaly scores are scaled for illustration purposes.
|
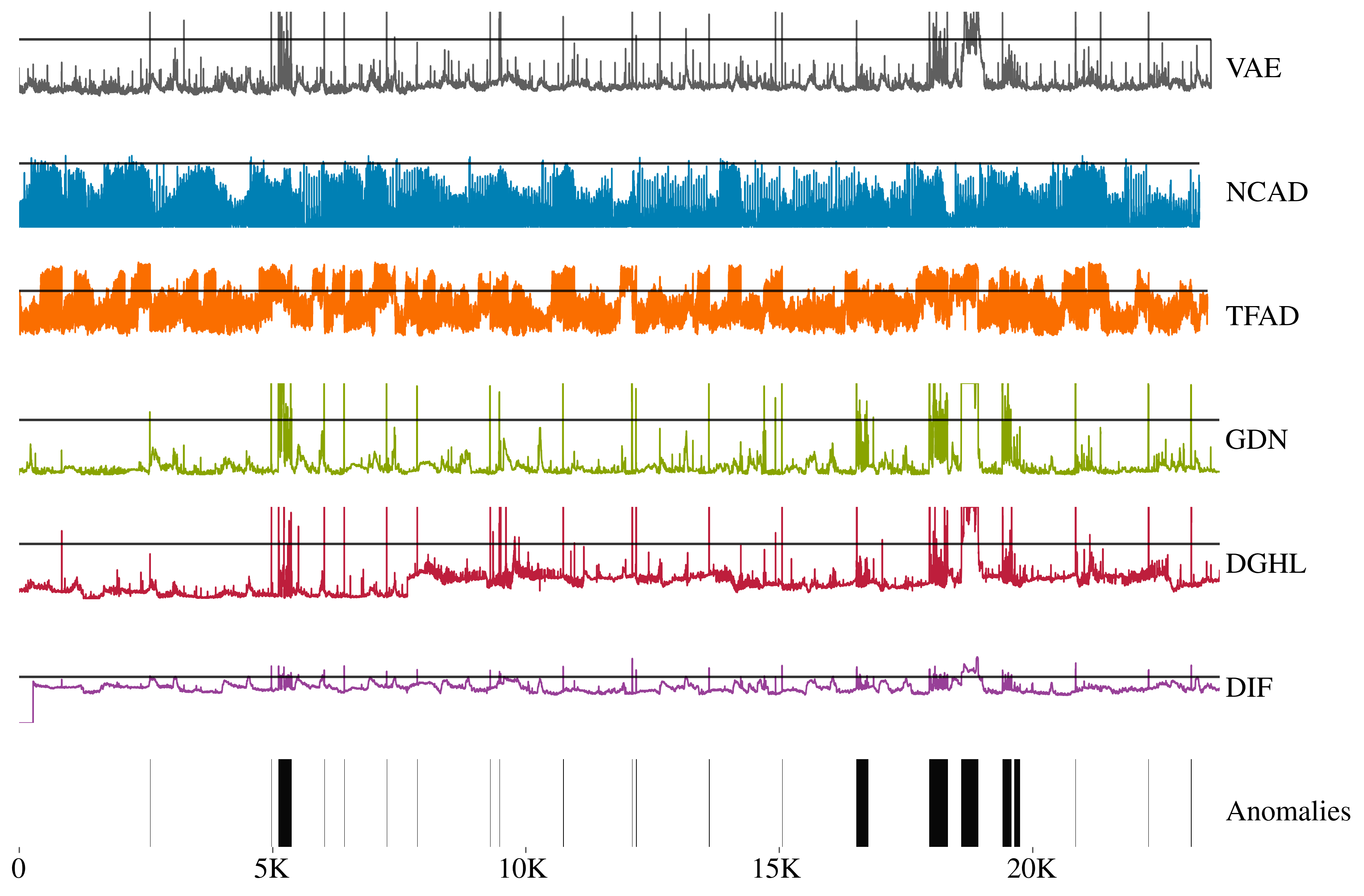
Hello,
I've encountered the exactly same issue as previous issue, and want to ask your opinion.
To provide more,
Along with the code without point adjustment (commenting out the PA part as in previous issue), I personally got the following result:
Although I agree that the F1-PA algorithm has practical justification (abnormal time point will cause an alert and
further make the whole segment noticed in real-world applications.), (1) F1 seems to aggravate too much, and (2) AAAI paper raises concern about F1-PA metrics: even random guessing can achieive high F1-PA depending on data distribution.
I want to ask your opinion on these results.
Thanks in advance.
The text was updated successfully, but these errors were encountered: