FastAPIアプリケーションをデプロイする場合、一般的なアプローチはLinuxコンテナ・イメージをビルドすることです。
基本的には Dockerを用いて行われます。生成されたコンテナ・イメージは、いくつかの方法のいずれかでデプロイできます。
Linuxコンテナの使用には、セキュリティ、反復可能性(レプリカビリティ)、シンプリシティなど、いくつかの利点があります。
!!! tip
TODO: なぜか遷移できない
お急ぎで、すでにこれらの情報をご存じですか? 以下のDockerfileの箇所👇へジャンプしてください。
Dockerfile プレビュー 👀
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
COPY ./app /code/app
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80"]
# If running behind a proxy like Nginx or Traefik add --proxy-headers
# CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80", "--proxy-headers"]コンテナ(主にLinuxコンテナ)は、同じシステム内の他のコンテナ(他のアプリケーションやコンポーネント)から隔離された状態を保ちながら、すべての依存関係や必要なファイルを含むアプリケーションをパッケージ化する非常に軽量な方法です。
Linuxコンテナは、ホスト(マシン、仮想マシン、クラウドサーバーなど)の同じLinuxカーネルを使用して実行されます。これは、(OS全体をエミュレートする完全な仮想マシンと比べて)非常に軽量であることを意味します。
このように、コンテナはリソースをほとんど消費しませんが、プロセスを直接実行するのに匹敵する量です(仮想マシンはもっと消費します)。
コンテナはまた、独自の分離された実行プロセス(通常は1つのプロセスのみ)や、ファイルシステム、ネットワークを持ちます。 このことはデプロイ、セキュリティ、開発などを簡素化させます。
コンテナは、コンテナ・イメージから実行されます。
コンテナ・イメージは、コンテナ内に存在すべきすべてのファイルや環境変数、そしてデフォルトのコマンド/プログラムを静的にバージョン化したものです。 ここでの静的とは、コンテナイメージは実行されておらず、パッケージ化されたファイルとメタデータのみであることを意味します。
保存された静的コンテンツである「コンテナイメージ」とは対照的に、「コンテナ」は通常、実行中のインスタンス、つまり実行されているものを指します。
コンテナが起動され実行されるとき(コンテナイメージから起動されるとき)、ファイルや環境変数などが作成されたり変更されたりする可能性があります。
これらの変更はそのコンテナ内にのみ存在しますが、基盤となるコンテナ・イメージには残りません(ディスクに保存されません)。
コンテナイメージは プログラム ファイルやその内容、例えば python と main.py ファイルに匹敵します。
そして、コンテナ自体は(コンテナイメージとは対照的に)イメージをもとにした実際の実行中のインスタンスであり、プロセスに匹敵します。
実際、コンテナが実行されているのは、プロセスが実行されているときだけです(通常は単一のプロセスだけです)。 コンテナ内で実行中のプロセスがない場合、コンテナは停止します。
Dockerは、コンテナ・イメージとコンテナを作成・管理するための主要なツールの1つです。
そして、DockerにはDockerイメージ(コンテナ)を共有するDocker Hubというものがあります。
Docker Hubは 多くのツールや環境、データベース、アプリケーションに対応している予め作成された公式のコンテナ・イメージをパブリックに提供しています。
例えば、公式イメージの1つにPython Imageがあります。
その他にも、データベースなどさまざまなイメージがあります:
- PostgreSQL
- MySQL
- MongoDB
- Redis, etc.
予め作成されたコンテナ・イメージを使用することで、異なるツールを組み合わせて使用することが非常に簡単になります。例えば、新しいデータベースを試す場合に特に便利です。ほとんどの場合、公式イメージを使い、環境変数で設定するだけで良いです。
そうすれば多くの場合、コンテナとDockerについて学び、その知識をさまざまなツールやコンポーネントによって再利用することができます。
つまり、データベース、Pythonアプリケーション、Reactフロントエンド・アプリケーションを備えたウェブ・サーバーなど、さまざまなものを複数のコンテナで実行し、それらを内部ネットワーク経由で接続します。
すべてのコンテナ管理システム(DockerやKubernetesなど)には、こうしたネットワーキング機能が統合されています。
通常、コンテナ・イメージはそのメタデータにコンテナの起動時に実行されるデフォルトのプログラムまたはコマンドと、そのプログラムに渡されるパラメータを含みます。コマンドラインでの操作とよく似ています。
コンテナが起動されると、そのコマンド/プログラムが実行されます(ただし、別のコマンド/プログラムをオーバーライドして実行させることもできます)。
コンテナは、メイン・プロセス(コマンドまたはプログラム)が実行されている限り実行されます。
コンテナは通常1つのプロセスを持ちますが、メイン・プロセスからサブ・プロセスを起動することも可能で、そうすれば同じコンテナ内に複数のプロセスを持つことになります。
しかし、少なくとも1つの実行中のプロセスがなければ、実行中のコンテナを持つことはできないです。メイン・プロセスが停止すれば、コンテナも停止します。
ということで、何か作りましょう!🚀
FastAPI用のDockerイメージを、公式Pythonイメージに基づいてゼロからビルドする方法をお見せします。
これはほとんどの場合にやりたいことです。例えば:
- Kubernetesまたは同様のツールを使用する場合
- Raspberry Piで実行する場合
- コンテナ・イメージを実行してくれるクラウド・サービスなどを利用する場合
アプリケーションのパッケージ要件は通常、何らかのファイルに記述されているはずです。
パッケージ要件は主にインストールするために使用するツールに依存するでしょう。
最も一般的な方法は、requirements.txt ファイルにパッケージ名とそのバージョンを 1 行ずつ書くことです。
もちろん、FastAPI バージョンについて{.internal-link target=_blank}で読んだのと同じアイデアを使用して、バージョンの範囲を設定します。
例えば、requirements.txt は次のようになります:
fastapi>=0.68.0,<0.69.0
pydantic>=1.8.0,<2.0.0
uvicorn>=0.15.0,<0.16.0
そして通常、例えば pip を使ってこれらのパッケージの依存関係をインストールします:
$ pip install -r requirements.txt
---> 100%
Successfully installed fastapi pydantic uvicorn!!! info パッケージの依存関係を定義しインストールするためのフォーマットやツールは他にもあります。
Poetryを使った例は、後述するセクションでご紹介します。👇
appディレクトリを作成し、その中に入ります- 空のファイル
__init__.pyを作成します main.pyファイルを作成します:
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}同じプロジェクト・ディレクトリにDockerfileというファイルを作成します:
# (1)
FROM python:3.9
# (2)
WORKDIR /code
# (3)
COPY ./requirements.txt /code/requirements.txt
# (4)
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
# (5)
COPY ./app /code/app
# (6)
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80"]
-
公式のPythonベースイメージから始めます
-
現在の作業ディレクトリを
/codeに設定しますここに
requirements.txtファイルとappディレクトリを置きます。 -
要件が書かれたファイルを
/codeディレクトリにコピーします残りのコードではなく、最初に必要なファイルだけをコピーしてください。
このファイルは頻繁には変更されないので、Dockerはこのステップではそれを検知しキャッシュを使用し、次のステップでもキャッシュを有効にします。
-
要件ファイルにあるパッケージの依存関係をインストールします
--no-cache-dirオプションはダウンロードしたパッケージをローカルに保存しないようにpipに指示します。これは、同じパッケージをインストールするためにpipを再度実行する場合にのみ有効ですが、コンテナで作業する場合はそうではないです。!!! note
--no-cache-dirはpipに関連しているだけで、Dockerやコンテナとは何の関係もないです。--upgradeオプションは、パッケージが既にインストールされている場合、pipにアップグレードするように指示します。何故ならファイルをコピーする前のステップはDockerキャッシュによって検出される可能性があるためであり、このステップも利用可能な場合はDockerキャッシュを使用します。
このステップでキャッシュを使用すると、開発中にイメージを何度もビルドする際に、毎回すべての依存関係をダウンロードしてインストールする代わりに多くの時間を節約できます。
-
./app
ディレクトリを/code` ディレクトリの中にコピーする。これには最も頻繁に変更されるすべてのコードが含まれているため、Dockerのキャッシュはこれ以降のステップに簡単に使用されることはありません。
そのため、コンテナイメージのビルド時間を最適化するために、
Dockerfileの 最後 にこれを置くことが重要です。 -
uvicornサーバーを実行するためのコマンドを設定しますCMDは文字列のリストを取り、それぞれの文字列はスペースで区切られたコマンドラインに入力するものです。このコマンドは 現在の作業ディレクトリから実行され、上記の
WORKDIR /codeにて設定した/codeディレクトリと同じです。そのためプログラムは
/codeで開始しその中にあなたのコードがある./appディレクトリがあるので、Uvicorn はapp.mainからappを参照し、インポート することができます。
!!! tip コード内の"+"の吹き出しをクリックして、各行が何をするのかをレビューしてください。👆
これで、次のようなディレクトリ構造になるはずです:
.
├── app
│ ├── __init__.py
│ └── main.py
├── Dockerfile
└── requirements.txt
Nginx や Traefik のような TLS Termination Proxy (ロードバランサ) の後ろでコンテナを動かしている場合は、--proxy-headersオプションを追加します。
このオプションは、Uvicornにプロキシ経由でHTTPSで動作しているアプリケーションに対して、送信されるヘッダを信頼するよう指示します。
CMD ["uvicorn", "app.main:app", "--proxy-headers", "--host", "0.0.0.0", "--port", "80"]このDockerfileには重要なトリックがあり、まず依存関係だけのファイルをコピーします。その理由を説明します。
COPY ./requirements.txt /code/requirements.txtDockerや他のツールは、これらのコンテナイメージを段階的にビルドし、1つのレイヤーを他のレイヤーの上に追加します。Dockerfileの先頭から開始し、Dockerfileの各命令によって作成されたファイルを追加していきます。
Dockerや同様のツールは、イメージをビルドする際に内部キャッシュも使用します。前回コンテナイメージを構築したときからファイルが変更されていない場合、ファイルを再度コピーしてゼロから新しいレイヤーを作成する代わりに、前回作成した同じレイヤーを再利用します。
ただファイルのコピーを避けるだけではあまり改善されませんが、そのステップでキャッシュを利用したため、次のステップでキャッシュを使うことができます。
例えば、依存関係をインストールする命令のためにキャッシュを使うことができます:
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txtパッケージ要件のファイルは頻繁に変更されることはありません。そのため、そのファイルだけをコピーすることで、Dockerはそのステップではキャッシュを使用することができます。
そして、Dockerは次のステップのためにキャッシュを使用し、それらの依存関係をダウンロードしてインストールすることができます。そして、ここで多くの時間を節約します。✨ ...そして退屈な待ち時間を避けることができます。😪😆
パッケージの依存関係をダウンロードしてインストールするには数分かかりますが、キャッシュを使えばせいぜい数秒です。
加えて、開発中にコンテナ・イメージを何度もビルドして、コードの変更が機能しているかどうかをチェックすることになるため、多くの時間を節約することができます。
そしてDockerfileの最終行の近くですべてのコードをコピーします。この理由は、最も頻繁に変更されるものなので、このステップの後にあるものはほとんどキャッシュを使用することができないのためです。
COPY ./app /code/appすべてのファイルが揃ったので、コンテナ・イメージをビルドしましょう。
- プロジェクトディレクトリに移動します(
Dockerfileがある場所で、appディレクトリがあります) - FastAPI イメージをビルドします:
$ docker build -t myimage .
---> 100%!!! tip
末尾の . に注目してほしいです。これは ./ と同じ意味です。 これはDockerにコンテナイメージのビルドに使用するディレクトリを指示します。
この場合、同じカレント・ディレクトリ(`.`)です。
- イメージに基づいてコンテナを実行します:
$ docker run -d --name mycontainer -p 80:80 myimageDockerコンテナのhttp://192.168.99.100/items/5?q=somequery や http://127.0.0.1/items/5?q=somequery (またはそれに相当するDockerホストを使用したもの)といったURLで確認できるはずです。
アクセスすると以下のようなものが表示されます:
{"item_id": 5, "q": "somequery"}これらのURLにもアクセスできます: http://192.168.99.100/docs や http://127.0.0.1/docs (またはそれに相当するDockerホストを使用したもの)
アクセスすると、自動対話型APIドキュメント(Swagger UIが提供)が表示されます:
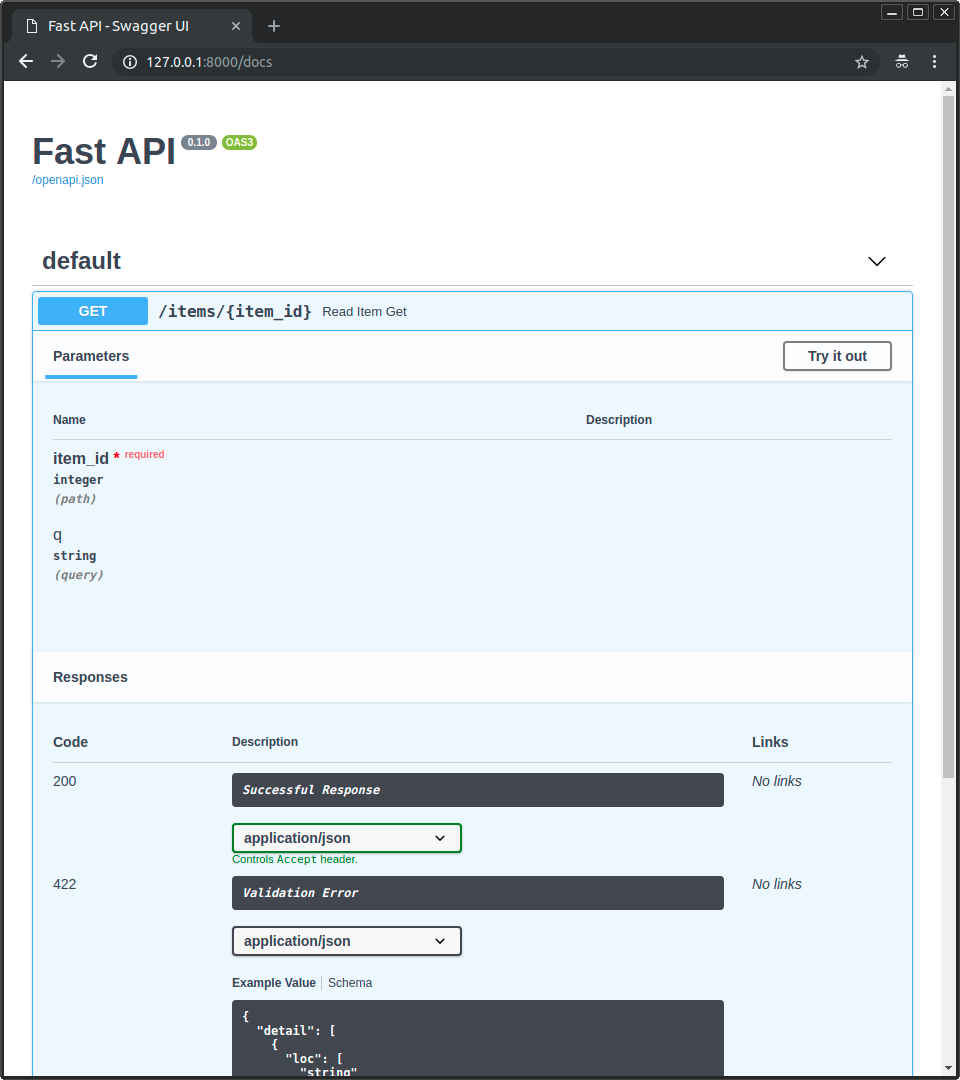
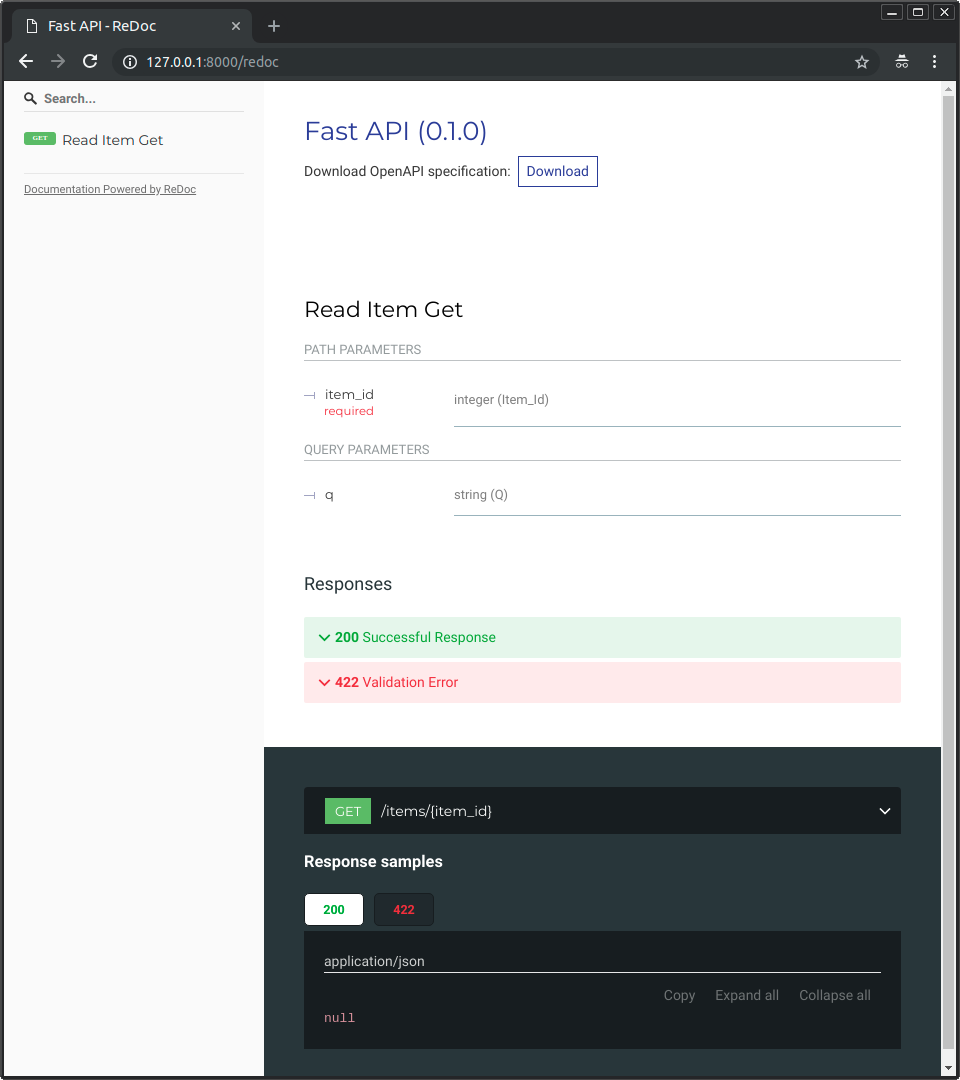
また、http://192.168.99.100/redoc や http://127.0.0.1/redoc (またはそれに相当するDockerホストを使用したもの)にもアクセスできます。
代替の自動ドキュメント(ReDocによって提供される)が表示されます:
FastAPI が単一のファイル、例えば ./app ディレクトリのない main.py の場合、ファイル構造は次のようになります:
.
├── Dockerfile
├── main.py
└── requirements.txt
そうすれば、Dockerfileの中にファイルをコピーするために、対応するパスを変更するだけでよいです:
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
# (1)
COPY ./main.py /code/
# (2)
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "80"]
-
main.py
ファイルを/code` ディレクトリに直接コピーします。 -
Uvicornを実行し、
mainからappオブジェクトをインポートするように指示します(app.mainからインポートするのではなく)。
次にUvicornコマンドを調整して、app.main の代わりに新しいモジュール main を使用し、FastAPIオブジェクトである app をインポートします。
コンテナという観点から、デプロイのコンセプト{.internal-link target=_blank}に共通するいくつかについて、もう一度説明しましょう。
コンテナは主に、アプリケーションのビルドとデプロイのプロセスを簡素化するためのツールですが、これらのデプロイのコンセプトを扱うための特定のアプローチを強制するものではないです。
良いニュースは、それぞれの異なる戦略には、すべてのデプロイメントのコンセプトをカバーする方法があるということです。🎉
これらのデプロイメントのコンセプトをコンテナの観点から見直してみましょう:
- セキュリティ - HTTPS
- 起動時の実行
- 再起動
- レプリケーション(実行中のプロセス数)
- メモリ
- 開始前の事前ステップ
FastAPI アプリケーションの コンテナ・イメージ(および後で実行中の コンテナ)だけに焦点を当てると、通常、HTTPSは別のツールを用いて外部で処理されます。
例えばTraefikのように、HTTPSと証明書の自動取得を扱う別のコンテナである可能性もあります。
!!! tip TraefikはDockerやKubernetesなどと統合されているので、コンテナ用のHTTPSの設定や構成はとても簡単です。
あるいは、(コンテナ内でアプリケーションを実行しながら)クラウド・プロバイダーがサービスの1つとしてHTTPSを処理することもできます。
通常、コンテナの起動と実行を担当する別のツールがあります。
それは直接Dockerであったり、Docker Composeであったり、Kubernetesであったり、クラウドサービスであったりします。
ほとんどの場合(またはすべての場合)、起動時にコンテナを実行し、失敗時に再起動を有効にする簡単なオプションがあります。例えばDockerでは、コマンドラインオプションの--restartが該当します。
コンテナを使わなければ、アプリケーションを起動時や再起動時に実行させるのは面倒で難しいかもしれません。しかし、コンテナで作業する場合、ほとんどのケースでその機能はデフォルトで含まれています。✨
Kubernetes や Docker Swarm モード、Nomad、あるいは複数のマシン上で分散コンテナを管理するための同様の複雑なシステムを使ってマシンのクラスターを構成している場合、 各コンテナで(Workerを持つGunicornのような)プロセスマネージャを使用する代わりに、クラスター・レベルでレプリケーションを処理したいと思うでしょう。
Kubernetesのような分散コンテナ管理システムの1つは通常、入ってくるリクエストのロードバランシングをサポートしながら、コンテナのレプリケーションを処理する統合された方法を持っています。このことはすべてクラスタレベルにてです。
そのような場合、UvicornワーカーでGunicornのようなものを実行するのではなく、上記の説明のようにDockerイメージをゼロからビルドし、依存関係をインストールして、単一のUvicornプロセスを実行したいでしょう。
コンテナを使用する場合、通常はメイン・ポートでリスニングしているコンポーネントがあるはずです。それはおそらく、HTTPSを処理するためのTLS Termination Proxyでもある別のコンテナであったり、同様のツールであったりするでしょう。
このコンポーネントはリクエストの 負荷 を受け、 (うまくいけば) その負荷をバランスよく ワーカーに分配するので、一般に ロードバランサ とも呼ばれます。
!!! tip HTTPSに使われるものと同じTLS Termination Proxyコンポーネントは、おそらくロードバランサーにもなるでしょう。
そしてコンテナで作業する場合、コンテナの起動と管理に使用する同じシステムには、ロードバランサー(TLS Termination Proxyの可能性もある)からネットワーク通信(HTTPリクエストなど)をアプリのあるコンテナ(複数可)に送信するための内部ツールが既にあるはずです。
Kubernetesや同様の分散コンテナ管理システムで作業する場合、その内部のネットワーキングのメカニズムを使用することで、メインのポートでリッスンしている単一のロードバランサーが、アプリを実行している可能性のある複数のコンテナに通信(リクエスト)を送信できるようになります。
アプリを実行するこれらのコンテナには、通常1つのプロセス(たとえば、FastAPIアプリケーションを実行するUvicornプロセス)があります。これらはすべて同一のコンテナであり同じものを実行しますが、それぞれが独自のプロセスやメモリなどを持ちます。そうすることで、CPUの異なるコア、あるいは異なるマシンでの並列化を利用できます。
そして、ロードバランサーを備えた分散コンテナシステムは、順番にあなたのアプリを含む各コンテナにリクエストを分配します。つまり、各リクエストは、あなたのアプリを実行している複数のレプリケートされたコンテナの1つによって処理されます。
そして通常、このロードバランサーは、クラスタ内の他のアプリケーション(例えば、異なるドメインや異なるURLパスのプレフィックスの配下)へのリクエストを処理することができ、その通信をクラスタ内で実行されている他のアプリケーションのための適切なコンテナに送信します。
この種のシナリオでは、すでにクラスタ・レベルでレプリケーションを処理しているため、おそらくコンテナごとに単一の(Uvicorn)プロセスを持ちたいでしょう。
この場合、Uvicornワーカーを持つGunicornのようなプロセスマネージャーや、Uvicornワーカーを使うUvicornは避けたいでしょう。コンテナごとにUvicornのプロセスは1つだけにしたいでしょう(おそらく複数のコンテナが必要でしょう)。
(GunicornやUvicornがUvicornワーカーを管理するように)コンテナ内に別のプロセスマネージャーを持つことは、クラスターシステムですでに対処しているであろう不要な複雑さを追加するだけです。
もちろん、特殊なケースとして、Gunicornプロセスマネージャを持つコンテナ内で複数のUvicornワーカープロセスを起動させたい場合があります。
このような場合、公式のDockerイメージを使用することができます。このイメージには、複数のUvicornワーカープロセスを実行するプロセスマネージャとしてGunicornが含まれており、現在のCPUコアに基づいてワーカーの数を自動的に調整するためのデフォルト設定がいくつか含まれています。詳しくは後述のGunicornによる公式Dockerイメージ - Uvicornで説明します。
以下は、それが理にかなっている場合の例です:
アプリケーションをシンプルな形で実行する場合、プロセス数の細かい調整が必要ない場合、自動化されたデフォルトを使用するだけで、コンテナ内にプロセスマネージャが必要かもしれません。例えば、公式Dockerイメージでシンプルな設定が可能です。
Docker Composeでシングルサーバ(クラスタではない)にデプロイすることもできますので、共有ネットワークとロードバランシングを維持しながら(Docker Composeで)コンテナのレプリケーションを管理する簡単な方法はないでしょう。
その場合、単一のコンテナで、プロセスマネージャが内部で複数のワーカープロセスを起動するようにします。
また、1つのコンテナに1つのプロセスを持たせるのではなく、1つのコンテナに複数のプロセスを持たせる方が簡単だという他の理由もあるでしょう。
例えば、(セットアップにもよりますが)Prometheusエクスポーターのようなツールを同じコンテナ内に持つことができます。
この場合、複数のコンテナがあると、デフォルトでは、Prometheusがメトリクスを読みに来たとき、すべてのレプリケートされたコンテナの蓄積されたメトリクスを取得するのではなく、毎回単一のコンテナ(その特定のリクエストを処理したコンテナ)のものを取得することになります。
その場合、複数のプロセスを持つ1つのコンテナを用意し、同じコンテナ上のローカルツール(例えばPrometheusエクスポーター)がすべての内部プロセスのPrometheusメトリクスを収集し、その1つのコンテナ上でそれらのメトリクスを公開する方がシンプルかもしれません。
重要なのは、盲目的に従わなければならない普遍のルールはないということです。
これらのアイデアは、あなた自身のユースケースを評価し、あなたのシステムに最適なアプローチを決定するために使用することができます:
- セキュリティ - HTTPS
- 起動時の実行
- 再起動
- レプリケーション(実行中のプロセス数)
- メモリ
- 開始前の事前ステップ
コンテナごとに単一のプロセスを実行すると、それらのコンテナ(レプリケートされている場合は1つ以上)によって消費される多かれ少なかれ明確に定義された、安定し制限された量のメモリを持つことになります。
そして、コンテナ管理システム(Kubernetesなど)の設定で、同じメモリ制限と要件を設定することができます。
そうすれば、コンテナが必要とするメモリ量とクラスタ内のマシンで利用可能なメモリ量を考慮して、利用可能なマシンにコンテナをレプリケートできるようになります。
アプリケーションがシンプルなものであれば、これはおそらく問題にはならないでしょうし、ハードなメモリ制限を指定する必要はないかもしれないです。
しかし、多くのメモリを使用している場合(たとえば機械学習モデルなど)、どれだけのメモリを消費しているかを確認し、各マシンで実行するコンテナの数を調整する必要があります(そしておそらくクラスタにマシンを追加します)。
コンテナごとに複数のプロセスを実行する場合(たとえば公式のDockerイメージで)、起動するプロセスの数が利用可能なメモリ以上に消費しないようにする必要があります。
コンテナ(DockerやKubernetesなど)を使っている場合、主に2つのアプローチがあります。
複数のコンテナがあり、おそらくそれぞれが単一のプロセスを実行している場合(Kubernetesクラスタなど)、レプリケートされたワーカーコンテナを実行する前に、単一のコンテナで事前のステップの作業を行う別のコンテナを持ちたいと思うでしょう。
!!! info もしKubernetesを使用している場合, これはおそらくInit コンテナでしょう。
ユースケースが事前のステップを並列で複数回実行するのに問題がない場合(例:データベースの準備チェック)、メインプロセスを開始する前に、それらのステップを各コンテナに入れることが可能です。
単純なセットアップで、単一のコンテナで複数のワーカー・プロセス(または1つのプロセスのみ)を起動する場合、アプリでプロセスを開始する直前に、同じコンテナで事前のステップを実行できます。公式Dockerイメージは、内部的にこれをサポートしています。
前の章で詳しく説明したように、Uvicornワーカーで動作するGunicornを含む公式のDockerイメージがあります: Server Workers - Gunicorn と Uvicorn{.internal-link target=_blank}で詳しく説明しています。
このイメージは、主に上記で説明した状況で役に立つでしょう: 複数のプロセスと特殊なケースを持つコンテナ(Containers with Multiple Processes and Special Cases)
!!! warning このベースイメージや類似のイメージは必要ない可能性が高いので、上記の: FastAPI用のDockerイメージをビルドする(Build a Docker Image for FastAPI)のようにゼロからイメージをビルドする方が良いでしょう。
このイメージには、利用可能なCPUコアに基づいてワーカー・プロセスの数を設定するオートチューニングメカニズムが含まれています。
これは賢明なデフォルトを備えていますが、環境変数や設定ファイルを使ってすべての設定を変更したり更新したりすることができます。
また、スクリプトで開始前の事前ステップを実行することもサポートしている。
!!! tip すべての設定とオプションを見るには、Dockerイメージのページをご覧ください: tiangolo/uvicorn-gunicorn-fastapi
このイメージのプロセス数は、利用可能なCPUコアから自動的に計算されます。
つまり、CPUから可能な限りパフォーマンスを引き出そうとします。
また、環境変数などを使った設定で調整することもできます。
しかし、プロセスの数はコンテナが実行しているCPUに依存するため、消費されるメモリの量もそれに依存することになります。
そのため、(機械学習モデルなどで)大量のメモリを消費するアプリケーションで、サーバーのCPUコアが多いがメモリが少ない場合、コンテナは利用可能なメモリよりも多くのメモリを使おうとすることになります。
その結果、パフォーマンスが大幅に低下する(あるいはクラッシュする)可能性があります。🚨
この画像に基づいてDockerfileを作成する方法を以下に示します:
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.9
COPY ./requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt
COPY ./app /app複数のファイルを持つ大きなアプリケーション{.internal-link target=_blank}を作成するセクションに従った場合、Dockerfileは次のようになります:
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.9
COPY ./requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt
COPY ./app /app/appおそらく、Kubernetes(または他のもの)を使用していて、すでにクラスタレベルで複数のコンテナでレプリケーションを設定している場合は、この公式ベースイメージ(または他の類似のもの)は使用すべきではありません。
そのような場合は、上記のようにゼロからイメージを構築する方がよいでしょう: FastAPI用のDockerイメージをビルドする(Build a Docker Image for FastAPI) を参照してください。
このイメージは、主に上記の複数のプロセスと特殊なケースを持つコンテナ(Containers with Multiple Processes and Special Cases)で説明したような特殊なケースで役に立ちます。
例えば、アプリケーションがシンプルで、CPUに応じたデフォルトのプロセス数を設定すればうまくいく場合や、クラスタレベルでレプリケーションを手動で設定する手間を省きたい場合、アプリで複数のコンテナを実行しない場合などです。
または、Docker Composeでデプロイし、単一のサーバで実行している場合などです。
コンテナ(Docker)イメージを手に入れた後、それをデプロイするにはいくつかの方法があります。
例えば以下のリストの方法です:
- 単一サーバーのDocker Compose
- Kubernetesクラスタ
- Docker Swarmモードのクラスター
- Nomadのような別のツール
- コンテナ・イメージをデプロイするクラウド・サービス
もしプロジェクトの依存関係を管理するためにPoetryを利用する場合、マルチステージビルドを使うと良いでしょう。
# (1)
FROM python:3.9 as requirements-stage
# (2)
WORKDIR /tmp
# (3)
RUN pip install poetry
# (4)
COPY ./pyproject.toml ./poetry.lock* /tmp/
# (5)
RUN poetry export -f requirements.txt --output requirements.txt --without-hashes
# (6)
FROM python:3.9
# (7)
WORKDIR /code
# (8)
COPY --from=requirements-stage /tmp/requirements.txt /code/requirements.txt
# (9)
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
# (10)
COPY ./app /code/app
# (11)
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80"]
-
これは最初のステージで、
requirements-stageと名付けられます -
/tmpを現在の作業ディレクトリに設定します ここでrequirements.txtというファイルを生成します。 -
このDockerステージにPoetryをインストールします
-
pyproject.toml
とpoetry.lockファイルを/tmp` ディレクトリにコピーします./poetry.lock*(末尾に*)を使用するため、そのファイルがまだ利用できない場合でもクラッシュすることはないです。 -
requirements.txt`ファイルを生成します
-
これは最後のステージであり、ここにあるものはすべて最終的なコンテナ・イメージに保存されます
-
現在の作業ディレクトリを
/codeに設定します -
requirements.txtファイルを/codeディレクトリにコピーします このファイルは前のDockerステージにしか存在しないため、--from-requirements-stageを使ってコピーします。 -
生成された
requirements.txtファイルにあるパッケージの依存関係をインストールします -
app
ディレクトリを/code` ディレクトリにコピーします -
uvicorn
コマンドを実行して、app.mainからインポートしたapp` オブジェクトを使用するように指示します !!! tip "+"の吹き出しをクリックすると、それぞれの行が何をするのかを見ることができます
DockerステージはDockerfileの一部で、一時的なコンテナイメージとして動作します。
最初のステージは Poetryのインストールと Poetry の pyproject.toml ファイルからプロジェクトの依存関係を含む**requirements.txtを生成**するためだけに使用されます。
この requirements.txt ファイルは後半の 次のステージで pip と共に使用されます。
最終的なコンテナイメージでは、最終ステージのみが保存されます。前のステージは破棄されます。
Poetryを使用する場合、Dockerマルチステージビルドを使用することは理にかなっています。
なぜなら、最終的なコンテナイメージにPoetryとその依存関係がインストールされている必要はなく、必要なのはプロジェクトの依存関係をインストールするために生成された requirements.txt ファイルだけだからです。
そして次の(そして最終的な)ステージでは、前述とほぼ同じ方法でイメージをビルドします。
繰り返しになりますが、NginxやTraefikのようなTLS Termination Proxy(ロードバランサー)の後ろでコンテナを動かしている場合は、--proxy-headersオプションをコマンドに追加します:
CMD ["uvicorn", "app.main:app", "--proxy-headers", "--host", "0.0.0.0", "--port", "80"]コンテナ・システム(例えばDockerやKubernetesなど)を使えば、すべてのデプロイメントのコンセプトを扱うのがかなり簡単になります:
- セキュリティ - HTTPS
- 起動時の実行
- 再起動
- レプリケーション(実行中のプロセス数)
- メモリ
- 開始前の事前ステップ
ほとんどの場合、ベースとなるイメージは使用せず、公式のPython Dockerイメージをベースにしたコンテナイメージをゼロからビルドします。
DockerfileとDockerキャッシュ内の命令の順番に注意することで、ビルド時間を最小化することができ、生産性を最大化することができます(そして退屈を避けることができます)。😎
特別なケースでは、FastAPI用の公式Dockerイメージを使いたいかもしれません。🤓