Spark streaming support three types of time windows:
- tumbling windows (fixed time window)
- sliding windows
- session windows.
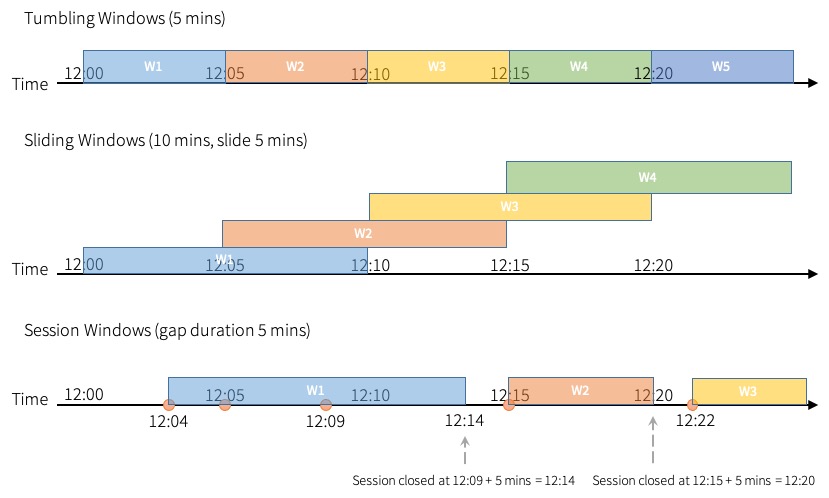 Source: Spark streaming programming
Source: Spark streaming programmingTumbling windows are fixed sized and static. They are non-overlapping and are contiguous intervals. Every ingested data can be (must be) bound to a singled window.
Sliding windows are also fixed sized and also static. Windows will overlap when the duration of the slide is smaller than the duration of the window. Ingested data can therefore be bound to two or more windows
Session windows are dynamic in size of the window length. The size depends on the ingested data. A session starts with an input and expands if the following input expands if the next ingested record has fallen within the gap duration.
For static window duration, a session window closes when there is no input received within gap duration. Both tumbling and sliding windows session uses session_window function.
Example of using dynamic session window with Python:
from pyspark.sql import functions as F
events = DataFrame { timestamp: Timestamp, userId: String, Value: Integer }
session_window = session_window(events.timestamp, \
F.when(events.userId == "user1", "5 seconds") \
.when(events.userId == "user2", "20 seconds").otherwise("5 minutes"))
# Group the data by session window and userId, and compute the count of each group
sessionizedCounts = events \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
session_window,
events.userId) \
.count()
In case of static window function, the session_window will not be defined. Example with Python:
sessionizedCounts = events \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
session_window(events.timestamp, "5 minutes"),
events.userId) \
.count()
Time windows functions are mandatory to be defined when there are ingest records with different durations or any kind of instability with ingest itself.
Tomorrow we will look into data manipulation and data engineering for Spark Streaming.
Compete set of code, documents, notebooks, and all of the materials will be available at the Github repository: https://github.com/tomaztk/Spark-for-data-engineers
Happy Spark Advent of 2021! 🙂