


A high performance LLM/RAG evaluation framework
Explore the docs »
Prepare your unstructured data for RAG »
Report Bug
·
Request Feature
·
Quick Start
Table of Contents
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.
Good RAG systems start with good inputs. Are you blocked on pre-processing messy, complex unstructured data into a standardized format for embedding and ingestion into your vector database?
Tonic Textual is a privacy-focused ETL for LLMs that standardizes unstructured data for AI development and uses proprietary NER models to create metadata tags that enable improved retreival performance via metadata filtering. If you're spending too much time on data preparation, we can help; reach out to us for a demo.
This is an example of how you may give instructions on setting up your project locally. To get a local copy up and running follow these simple example steps.
-
Install Tonic Validate
pip install tonic-validate -
Use the following code snippet to get started.
from tonic_validate import ValidateScorer, Benchmark import os os.environ["OPENAI_API_KEY"] = "your-openai-key" # Function to simulate getting a response and context from your LLM # Replace this with your actual function call def get_llm_response(question): return { "llm_answer": "Paris", "llm_context_list": ["Paris is the capital of France."] } benchmark = Benchmark(questions=["What is the capital of France?"], answers=["Paris"]) # Score the responses for each question and answer pair scorer = ValidateScorer() run = scorer.score(benchmark, get_llm_response)
This code snippet, creates a benchmark with one question and reference answer and then scores the answer. Providing a reference answer is not required for most metrics (see below Metrics table).
Many users find value in running evaluations during the code review/pull request process. You can create your own automation here using the snippet above and knowledge found in our documentation and this readme OR you can take advantage of our absolutely free Github Action in the Github Marketplace. The listing is here. It's easy to setup but if you have any questions, just create an issue in the corresponding repository.
Metrics are used to score your LLM's performance. Validate ships with many different metrics which are applicable to most RAG systems. You can create your own metrics as well by providing your own implementation of metric.py. To compute a metric, you must provide it data from your RAG application. The table below shows a few of the many metrics we offer with Tonic Validate. For more detail explanations of our metrics refer to our documentation.
| Metric Name | Inputs | Score Range | What does it measure? |
|---|---|---|---|
| Answer similarity score | QuestionReference answerLLM answer |
0 to 5 | How well the reference answer matches the LLM answer. |
| Retrieval precision | QuestionRetrieved Context |
0 to 1 | Whether the context retrieved is relevant to answer the given question. |
| Augmentation precision | QuestionRetrieved ContextLLM answer |
0 to 1 | Whether the relevant context is in the LLM answer. |
| Augmentation accuracy | Retrieved ContextLLM answer |
0 to 1 | Whether all the context is in the LLM answer. |
| Answer consistency | Retrieved ContextLLM answer |
0 to 1 | Whether there is information in the LLM answer that does not come from the context. |
| Latency | Run Time |
0 or 1 | Measures how long it takes for the LLM to complete a request. |
| Contains Text | LLM Answer |
0 or 1 | Checks whether or not response contains the given text. |
Metric inputs in Tonic Validate are used to provide the metrics with the information they need to calculate performance. Below, we explain each input type and how to pass them into Tonic Validate's SDK.
What is it: The question asked
How to use: You can provide the questions by passing them into the Benchmark via the questions argument.
from tonic_validate import Benchmark
benchmark = Benchmark(
questions=["What is the capital of France?", "What is the capital of Germany?"]
)What is it: A prewritten answer that serves as the ground truth for how the RAG application should answer the question.
How to use: You can provide the reference answers by passing it into the Benchmark via the answers argument. Each reference answer must correspond to a given question. So if the reference answer is for the third question in the questions list, then the reference answer must also be the third item in the answers list. The only metric that requires a reference answer is the Answer Similarity Score
from tonic_validate import Benchmark
benchmark = Benchmark(
questions=["What is the capital of France?", "What is the capital of Germany?"]
answers=["Paris", "Berlin"]
)What is it: The answer the RAG application / LLM gives to the question.
How to use: You can provide the LLM answer via the callback you provide to the Validate scorer. The answer is the first item in the tuple response.
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Score the responses
scorer = ValidateScorer()
run = scorer.score(benchmark, ask_rag)If you are manually logging the answers without using the callback, then you can provide the LLM answer via llm_answer when creating the LLMResponse.
from tonic_validate import LLMResponse
# Save the responses into an array for scoring
responses = []
for item in benchmark:
# llm_answer is the answer that LLM gives
llm_response = LLMResponse(
llm_answer="Paris",
benchmark_item=item
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)What is it: The context that your RAG application retrieves when answering a given question. This context is what's put in the prompt by the RAG application to help the LLM answer the question.
How to use: You can provide the LLM's retrieved context list via the callback you provide to the Validate scorer. The answer is the second item in the tuple response. The retrieved context is always a list
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Score the responses
scorer = ValidateScorer()
run = scorer.score(benchmark, ask_rag)If you are manually logging the answers, then you can provide the LLM context via llm_context_list when creating the LLMResponse.
from tonic_validate import LLMResponse
# Save the responses into an array for scoring
responses = []
for item in benchmark:
# llm_answer is the answer that LLM gives
# llm_context_list is a list of the context that the LLM used to answer the question
llm_response = LLMResponse(
llm_answer="Paris",
llm_context_list=["Paris is the capital of France."],
benchmark_item=item
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)What is it: Used for the latency metric to measure how long it took the LLM to respond.
How to use: If you are using the Validate scorer callback, then this metric is automatically calculated for you. If you are manually creating the LLM responses, then you need to provide how long the LLM took yourself via the run_time argument.
from tonic_validate import LLMResponse
# Save the responses into an array for scoring
responses = []
for item in benchmark:
run_time = # Float representing how many seconds the LLM took to respond
# llm_answer is the answer that LLM gives
# llm_context_list is a list of the context that the LLM used to answer the question
llm_response = LLMResponse(
llm_answer="Paris",
llm_context_list=["Paris is the capital of France."],
benchmark_item=item
run_time=run_time
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)Most metrics are scored with the assistance of a LLM. Validate supports OpenAI and Azure OpenAI but other LLMs can easily be integrated (just file an github issue against this repository).
In order to use OpenAI you must provide an OpenAI API Key.
import os
os.environ["OPENAI_API_KEY"] = "put-your-openai-api-key-here"If you already have the OPENAI_API_KEY set in your system's environment variables then you can skip this step. Otherwise, please set the environment variable before proceeding.
If you are using Azure, instead of setting the OPENAI_API_KEY environment variable, you instead need to set AZURE_OPENAI_API_KEY and AZURE_OPENAI_ENDPOINT. AZURE_OPENAI_ENDPOINT is the endpoint url for your Azure OpenAI deployment and AZURE_OPENAI_API_KEY is your API key.
import os
os.environ["AZURE_OPENAI_API_KEY"] = "put-your-azure-openai-api-key-here"
os.environ["AZURE_OPENAI_ENDPOINT"] = "put-your-azure-endpoint-here"If you already have the GEMINI_API_KEY set in your system's environment variables then you can skip this step. Otherwise, please set the environment variable before proceeding.
import os
os.environ["GEMINI_API_KEY"] = "put-your-gemini-api-key-here"Note that to use gemini, your Python version must be 3.9 or higher.
If you already have the ANTHROPIC_API_KEY set in your system's environment variables then you can skip this step. Otherwise, please set the environment variable before proceeding.
import os
os.environ["ANTHROPIC_API_KEY"] = "put-your-anthropic-api-key-here"To use metrics, instantiate an instance of ValidateScorer.
from tonic_validate import ValidateScorer
scorer = ValidateScorer()The default model used for scoring metrics is GPT 4 Turbo. To change the OpenAI model, pass the OpenAI model name into the model_evaluator argument for ValidateScorer. You can also pass in custom metrics via an array of metrics.
from tonic_validate import ValidateScorer
from tonic_validate.metrics import AnswerConsistencyMetric, AnswerSimilarityMetric
scorer = ValidateScorer([
AnswerConsistencyMetric(),
AugmentationAccuracyMetric()
], model_evaluator="gpt-3.5-turbo")You can also pass in other models like Google Gemini or Claude by setting the model_evaluator argument to the model name like so
scorer = ValidateScorer(model_evaluator="gemini/gemini-1.5-pro-latest")scorer = ValidateScorer(model_evaluator="claude-3")If an error occurs while scoring an item's metric, the score for that metric will be set to None. If you instead wish to have Tonic Validate throw an exception when there's an error scoring, then set fail_on_error to True in the constructor
scorer = ValidateScorer(fail_on_error=True)If you are using Azure, you MUST set the model_evaluator argument to your deployment name like so
scorer = ValidateScorer(model_evaluator="your-deployment-name")After you instantiate the ValidateScorer with your desired metrics, you can then score the metrics using the callback you defined earlier.
from tonic_validate import ValidateScorer, ValidateApi
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Score the responses
scorer = ValidateScorer()
run = scorer.score(benchmark, ask_rag)If you don't want to use the callback, you can instead log your answers manually by iterating over the benchmark and then score the answers.
from tonic_validate import ValidateScorer, LLMResponse
# Save the responses into an array for scoring
responses = []
for item in benchmark:
llm_response = LLMResponse(
llm_answer="Paris",
llm_context_list=["Paris is the capital of France"],
benchmark_item=item
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)There are two ways to view the results of a run.
You can manually print out the results via python like so
print("Overall Scores")
print(run.overall_scores)
print("------")
for item in run.run_data:
print("Question: ", item.reference_question)
print("Answer: ", item.reference_answer)
print("LLM Answer: ", item.llm_answer)
print("LLM Context: ", item.llm_context)
print("Scores: ", item.scores)
print("------")which outputs the following
Overall Scores
{'answer_consistency': 1.0, 'augmentation_accuracy': 1.0}
------
Question: What is the capital of France?
Answer: Paris
LLM Answer: Paris
LLM Context: ['Paris is the capital of France.']
Scores: {'answer_consistency': 1.0, 'augmentation_accuracy': 1.0}
------
Question: What is the capital of Spain?
Answer: Madrid
LLM Answer: Paris
LLM Context: ['Paris is the capital of France.']
Scores: {'answer_consistency': 1.0, 'augmentation_accuracy': 1.0}
------
You can easily view your run results by uploading them to our free to use UI. The main advantage of this method is the Tonic Validate UI provides graphing for your results along with additional visualization features. To sign up for the UI, go to here.
Once you sign up for the UI, you will go through an onboarding to create an API Key and Project.
Copy both the API Key and Project ID from the onboarding and insert it into the following code
from tonic_validate import ValidateApi
validate_api = ValidateApi("your-api-key")
validate_api.upload_run("your-project-id", run)
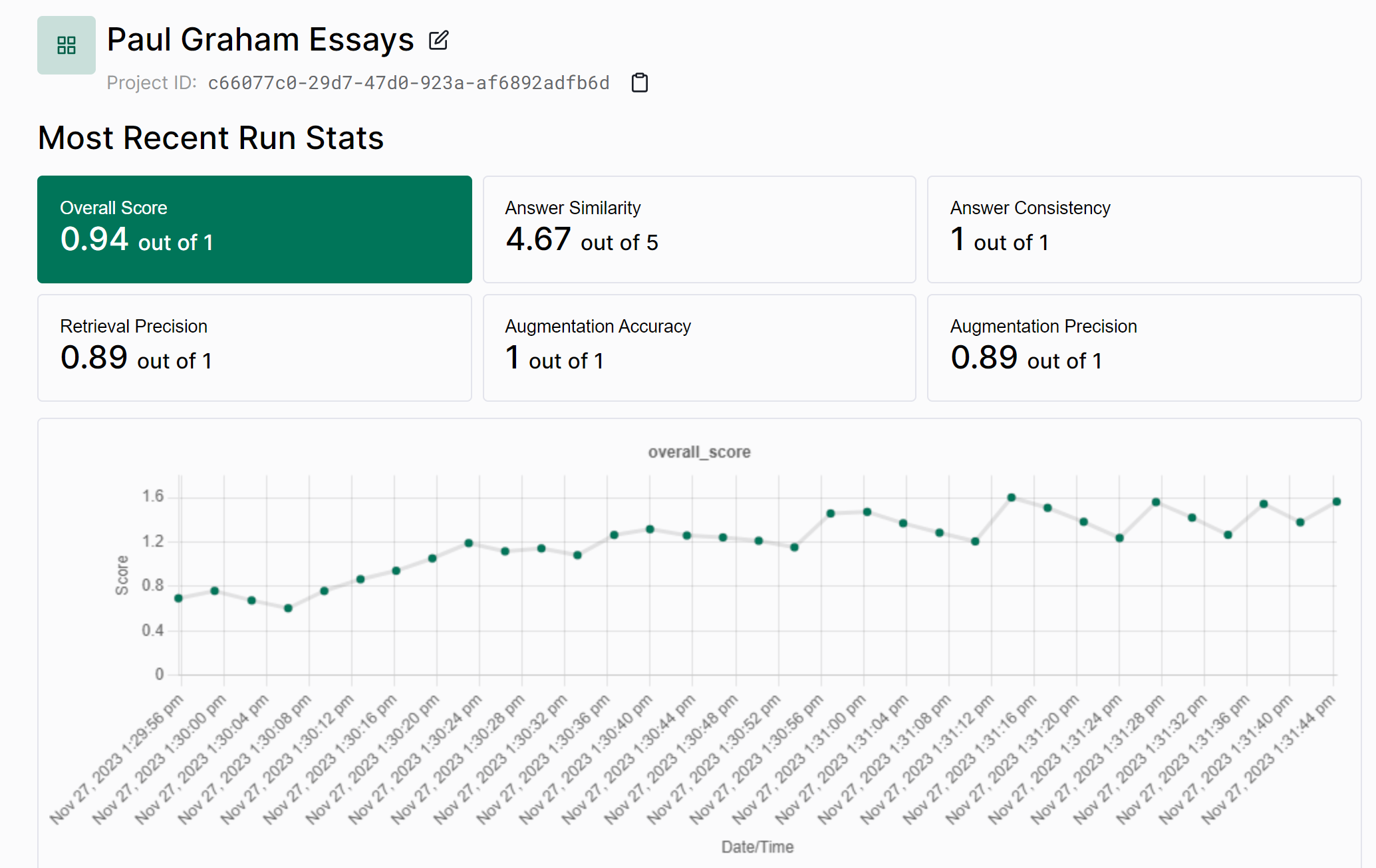
This will upload your run to the Tonic Validate UI where you can view the results. On the home page (as seen below) you can view the change in scores across runs over time.
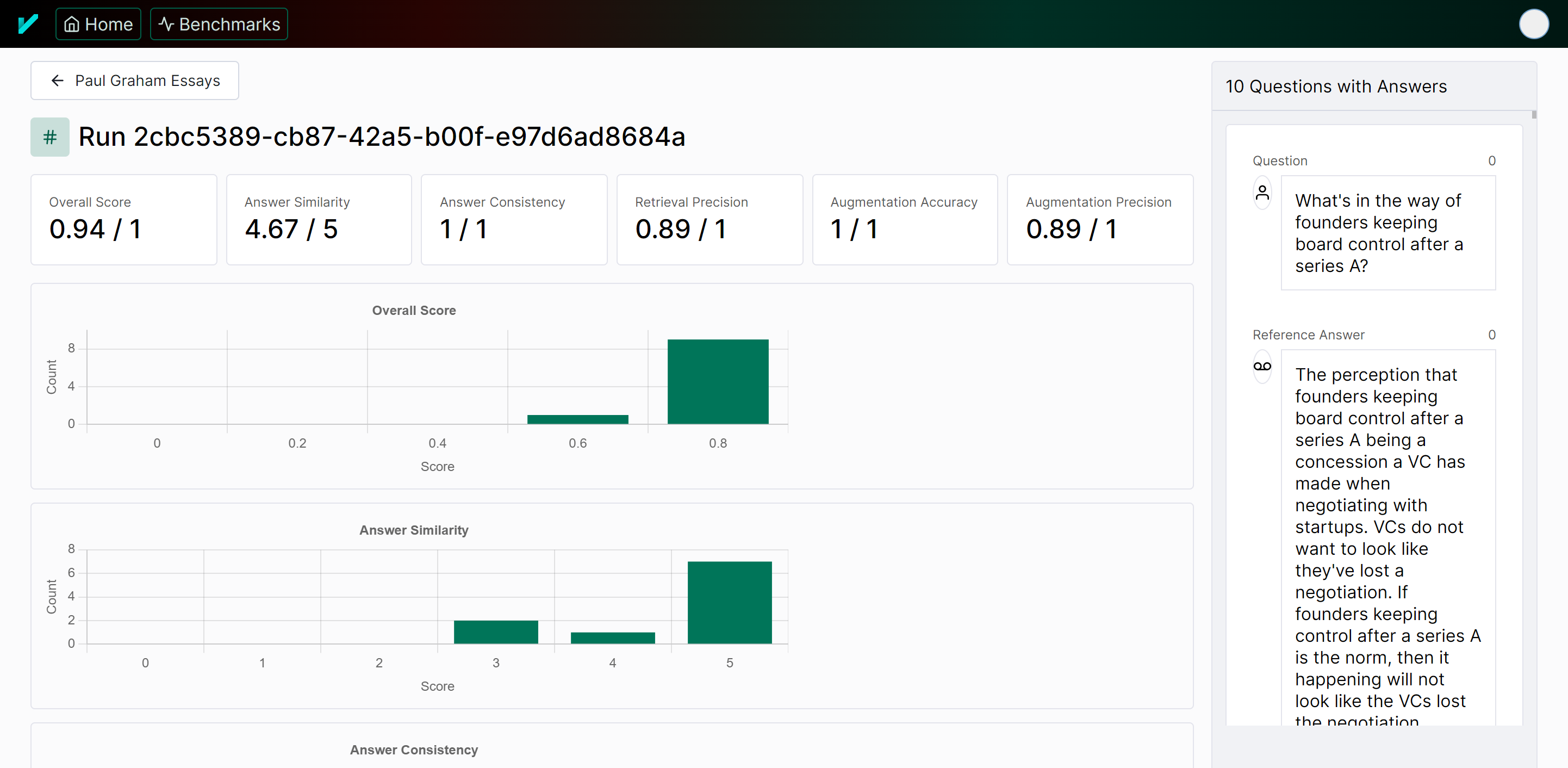
You can also view the results of an individual run in the UI as well.
Tonic Validate collects minimal telemetry to help us figure out what users want and how they're using the product. We do not use any existing telemetry framework and instead created our own privacy focused setup. Only the following information is tracked
- What metrics were used for a run
- Number of questions in a run
- Time taken for a run to be evaluated
- Number of questions in a benchmark
- SDK Version being used
We do NOT track things such as the contents of the questions / answers, your scores, or any other sensitive information. For detecting CI/CD, we only check for common environment variables in different CI/CD environments. We do not log the values of these environment variables.
We also generate a random UUID to help us figure out how many users are using the product. This UUID is linked to your Validate account only to help track who is using the SDK and UI at once and to get user counts. If you want to see how we implemented telemetry, you can do so in the tonic_validate/utils/telemetry.py file
If you wish to opt out of telemetry, you only need to set the TONIC_VALIDATE_DO_NOT_TRACK environment variable to True.
We currently allow the family of chat completion models from Open AI, Google, Anthropic, and more. We are always looking to add more models to our evaluator. If you have a model you would like to see added, please file an issue against this repository.
We'd like to add more models as choices for the LLM evaluator without adding to the complexity of the package too much.
The default model used for scoring metrics is GPT 4 Turbo. To change the model, pass the model name into the model argument for ValidateScorer
scorer = ValidateScorer([
AnswerConsistencyMetric(),
AugmentationAccuracyMetric()
], model_evaluator="gpt-3.5-turbo")Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are greatly appreciated.
If you have a suggestion that would make this better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement". Don't forget to give the project a star! Thanks again!
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
Distributed under the MIT License. See LICENSE.txt for more information.