Reduce Websocket copies / accept memoryviews #2102
Comments
This will work, but each one will do a system call. For a small write, it's probably going to be better to do the copy than to do two system calls. But this is a question that can be verified empirically: how big does a copy need to be to be more expensive than a system call? There are also interactions with
Python 3 has
Yeah, when the buffered writes are big enough (or when |
|
First thing that must be done - is the benchmarking and profiling. I would like to fix the problem |
#!/usr/bin/python3
import time
import tornado.ioloop
import tornado.web
import tornado.websocket
from tornado import gen
MSG = b'x' * 65536
class ChatSocketHandler(tornado.websocket.WebSocketHandler):
def get_compression_options(self):
# Non-None enables compression with default options.
return None
@gen.coroutine
def on_message(self, message):
iterations = 10000
start = time.monotonic()
for _ in range(iterations):
yield self.write_message(MSG) # yielding here changes from 319 to 265 MB/s
stop = time.monotonic()
print('Speed: {:0.02f} MB/s'.format(iterations * len(MSG) / ((stop - start) * 1000000)))
self.close()
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.set_header('content-type', 'text/html')
self.write('''
<body>
<script>
var ws = new WebSocket("ws://localhost:1234/test");
ws.onopen = function() {
ws.send("start!");
};
ws.onmessage = function (evt) {
// alert(evt.data);
};
</script>
</body>
''')
def main():
app = tornado.web.Application(handlers=[
(r'/', MainHandler),
(r"/test", ChatSocketHandler)
])
app.listen(1234)
tornado.ioloop.IOLoop.current().start()
if __name__ == "__main__":
main()Gives about 290 MB/s on my laptop. |
|
@bryevdv please provide typical usage patterns. I've profiled write-intensive case shown above. Here is the distribution:
I'll investigate further what is the bottleneck. First, I need to discover how really slow copying is. Stay tuned. |
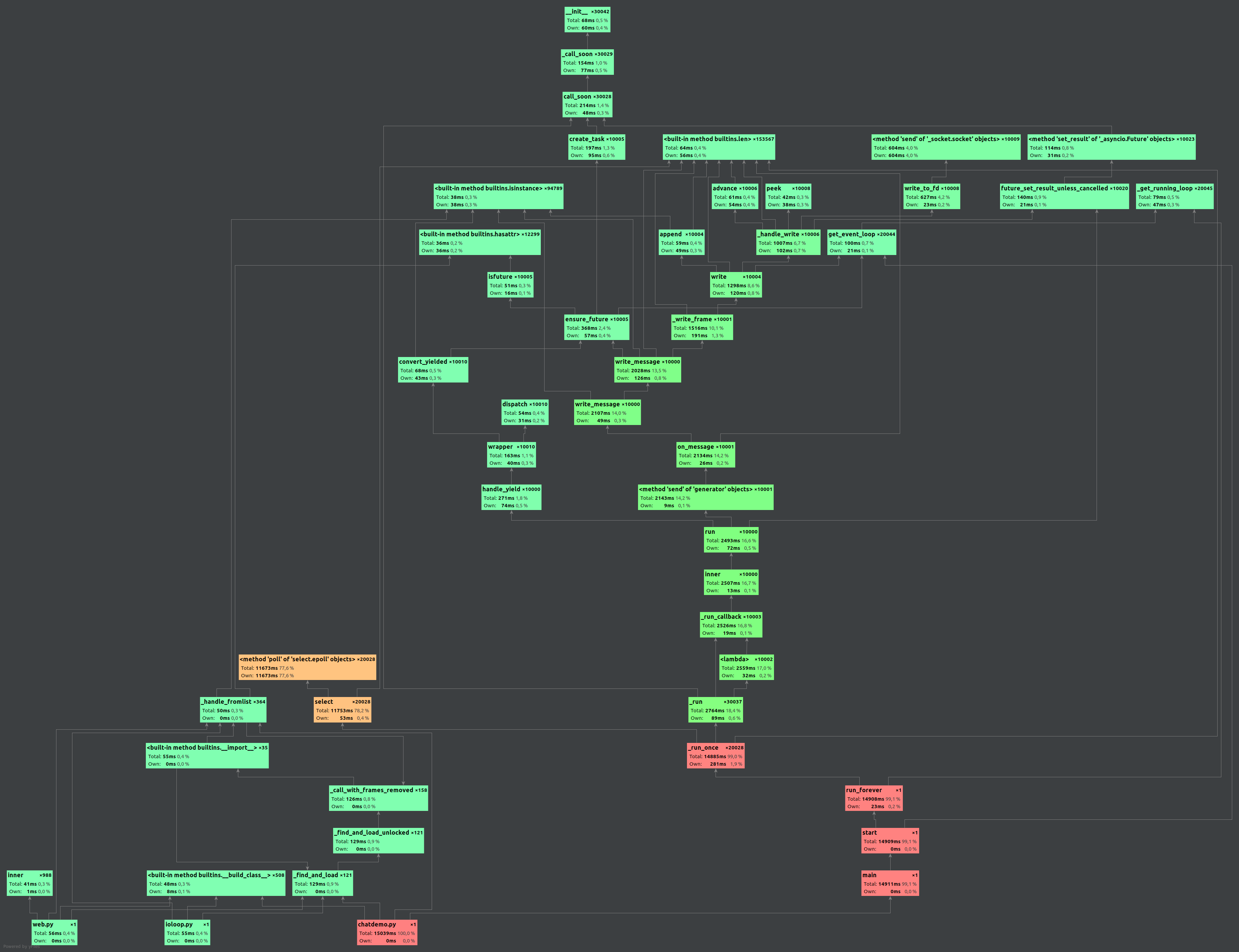
|
@socketpair here is a Bokeh server example that transfers dense 2d arrays every time a slider updates: https://github.com/bokeh/bokeh/blob/master/examples/app/image_blur.py That's probably the simplest example of the kind of usage Bokeh specifically would benefit from (but anyone transmitting dense arrays, I imagine). That example uses a 512x512 array and it performs acceptably on my laptop. Going to 1024x1024 is somewhat laggier. To run it: If you need to do any instrumentation and have questions I'd suggest pinging me on the gitter dev channel: https://gitter.im/bokeh/bokeh-dev |
|
@bryevdv Please describe the usage pattern that is used during websocket operations. As far as I understand from previous messages, it sendы about 3MB of data in one big websocket message. Right? If yes, does this message constructed from small pieces before transferring it to tornado webocket API? if no, what is the typical size of the messages? Does websocket client acknowledges each piece after reception? I need to construct realistic test application in order to distinguish between tornado websocket implementation inefficiency and Bokeh problems. Also, does compression make sense ? I mean, additional deplay may be caused by compression. Even more, I did not find usage of Do you really think, that the main reason of delays is in Tornado ? Yep, I can try to dive into Bokeh sources to make performance better. But this should be discussed in a different Github project. Please answer to the all questions from the message. |
|
@socketpair As a precursor, here is is the Bokeh message protocol:
Not entirely sure how to answer. Each NumPy array is sent as a single buffer, in the protocol above. The entire overall message is an assembly, but the buffers are not. They are basically just a pointers to NumPy array memory that passed to the write calls, they are not encoded, chunked, serialized, or assembled in any way before passing to tornado.
There is no typical size. Users will send whatever they send. We would just like to make the ceiling for reasonable use as high as possible. E.g. 2000x2000 RGBA image array updating in a response to a slider drag would be a great goal to achieve (I"m not sure if that is possible or not, but that's what I'd aim for) The protocol has an initial ACK, but subsequently there is not any ACK after every message.
It's possible, though offhand I expect it would depend on the payload sizes.
I don't recall that we use it, we can certainly enable it if it makes sense.
I think there are definitely avoidable copies in the Tornado codepaths, as described above (e.g. the |
|
Here is the important codepath for Bokeh: https://github.com/bokeh/bokeh/blob/master/bokeh/protocol/messages/patch_doc.py Specifically: As events are serialized, any NumPy arrays that are encountered are represented in the JSON with a small identifier, and and actually numpy data is returned separately in a Edit: Also if it would help to have a call, I'm happy to do a screenshare and go through the Bokeh sides of things. |
I don't think I agree with this unless I am misunderstanding it. In the protocol message description above, Bokeh sends all of the parts listed individually. It does not concatenate them. The possibility I was wondering about then is the (potentially large) payload buffer for arrays (which bokeh sends individually) being copied internally in tornado. Edit: Maybe I was confusing in stating "the entire message is an assembly" I did not mean that the entire message is concatenated. Every sub-piece of out messages are sent individually: where |
|
@socketpair actually I did forget one important thing. Bokeh has to do this below, because Tornado The |
|
@bryevdv I've managed to make a dirty (but working) patch to Tornado that does everything you need: memoryviews, and ability to pass an array of items to I've provided test of new API in the PR. strace shows: As you can see, no concatenation happened. Also, I know that Python's implementation of IOV allocates an array every time you call socket.sendmsg(). In other words, we eliminate copying, but add allocation and filling of this array, which could be slower than concatenation if we pass many small-sized buffers. |

|
You may already try to use this patched version of Tornado with slight changes in Bokeh. If such change appropriate for you, I can work on cleaning the patch. |
|
And also, TCP_NODELAY would greatly help in bokeh. |
@socketpair That would be great, I have a three day weekend coming up in a few day where I planned to catch up on a lot of Bokeh work, I will check out things in detail then
Where would this be set? |
|
@bryevdv TCP_NODELAY should be set once in every connection. Somewhere after connection establishment. This is especially important since you split big message to small ones. Without setting it, you are having delay after each submessage. Delays are OS-specific, and by my measures could reach 0.5 seconds. |
|
Because of websocket framing, I would discourage you from splitting big message to small parts. |
|
... looks like this is done automatically for the tornado websocket client (which uses SimpleAsyncHTTPClient) |
FYI @socketpair I don't have an opinion on this, it's not something I was thinking of previously, and I don't think it has any bearing on performance? I was mostly interested in:
In any case I will see about changing the Bokeh code to send a memory view this weekend. |
|
|
I've fixed code again (two lines) and now you can pass memoryview without any arrays, like |
|
@bryevdv could you please test performance using Bokeh ? Please remove any concatenations and conversion to bytes. Yes, my patch is dirty alot, but should work. If ok, I will write own benchmark, tests and cleanup everything in the patch. |
|
@socketpair We don't currently do any concatenations on the Bokeh side? I am about to try passing the |
|
@socketpair if I make this change to pass a Then I see an assertion error in Tornado when I run the |
|
@socketpair do you have any thoughts on he error above when passing a |
Since masking of inbound (client->server) message is mandated by RFC, a copy in that case is unavoidable. However outbound masking (server->client) is not mandated, and appears to be turned off by default:
https://github.com/tornadoweb/tornado/blob/master/tornado/websocket.py#L587
https://github.com/tornadoweb/tornado/blob/master/tornado/websocket.py#L461-L462
(It is set to
Truein the WS client connection class, as expected)This outbound case is the most relevant and important one for Bokeh, so any improvements to reduce copies on outbound messages would be beneficial for Bokeh users.
Below are some ideas from tracing through the code, I am sure there are many details I am not familiar with, but perhaps this can start a discussion.
Allow
write_messagesto accept amemoryview. Then in_write_frame, instead of doing all these concatenations:https://github.com/tornadoweb/tornado/blob/master/tornado/websocket.py#L762-L767
Place the message chunks on the stream write buffer individually. I am not sure if multiple calls to
self.stream.write(chunk)would suffice (I'm guessing not), or ifiostream.writewould have be modified to accept multiple ordered chunks. However, it seems thatiostream.writeis already capable of storing a list of pending writes when the write buffer is "frozen". Currently all of these buffers get concatenated:https://github.com/tornadoweb/tornado/blob/master/tornado/iostream.py#L840
But perhaps instead of concatenating before clearing pending writes, the list of buffers could be copied instead, then
_handle_writecould loop over these, instead of expecting one concatenated array.The text was updated successfully, but these errors were encountered: