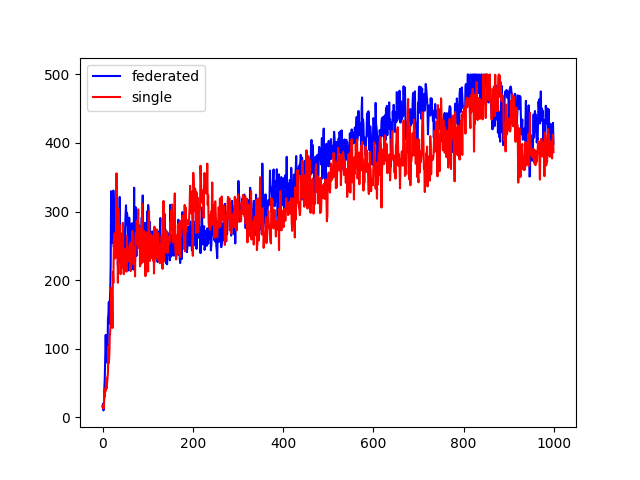
The purpose of this project is to assess the effect of parallel training of multiple Deep Reinforcement Learning agents using the Federated Averaging (FedAVG) algorithm -- after training the agents for specific timesteps, all of the Deep Q Network models are aggregated by taking the average of their parameters and subsequently the averaged model will be set for all of the agents for more training rounds.
- CartPole
- Lunar Lander
- Super Mario Bros
- Deep Q Network
- Double Deep Q Network



| Env 1-1 | Env 1-2 |
|---|---|
 |
 |
| Env 1-3 | Env 1-4 |
 |
 |