CUDA out of memory issue #1654
Comments
|
👋 Hello @ashishgupta582, thank you for your interest in YOLOv8 🚀! We recommend a visit to the YOLOv8 Docs for new users where you can find many Python and CLI usage examples and where many of the most common questions may already be answered. If this is a 🐛 Bug Report, please provide a minimum reproducible example to help us debug it. If this is a custom training ❓ Question, please provide as much information as possible, including dataset image examples and training logs, and verify you are following our Tips for Best Training Results. InstallPip install the pip install ultralyticsEnvironmentsYOLOv8 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all Ultralytics CI tests are currently passing. CI tests verify correct operation of all YOLOv8 Modes and Tasks on macOS, Windows, and Ubuntu every 24 hours and on every commit. |


|
@ashishgupta582
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
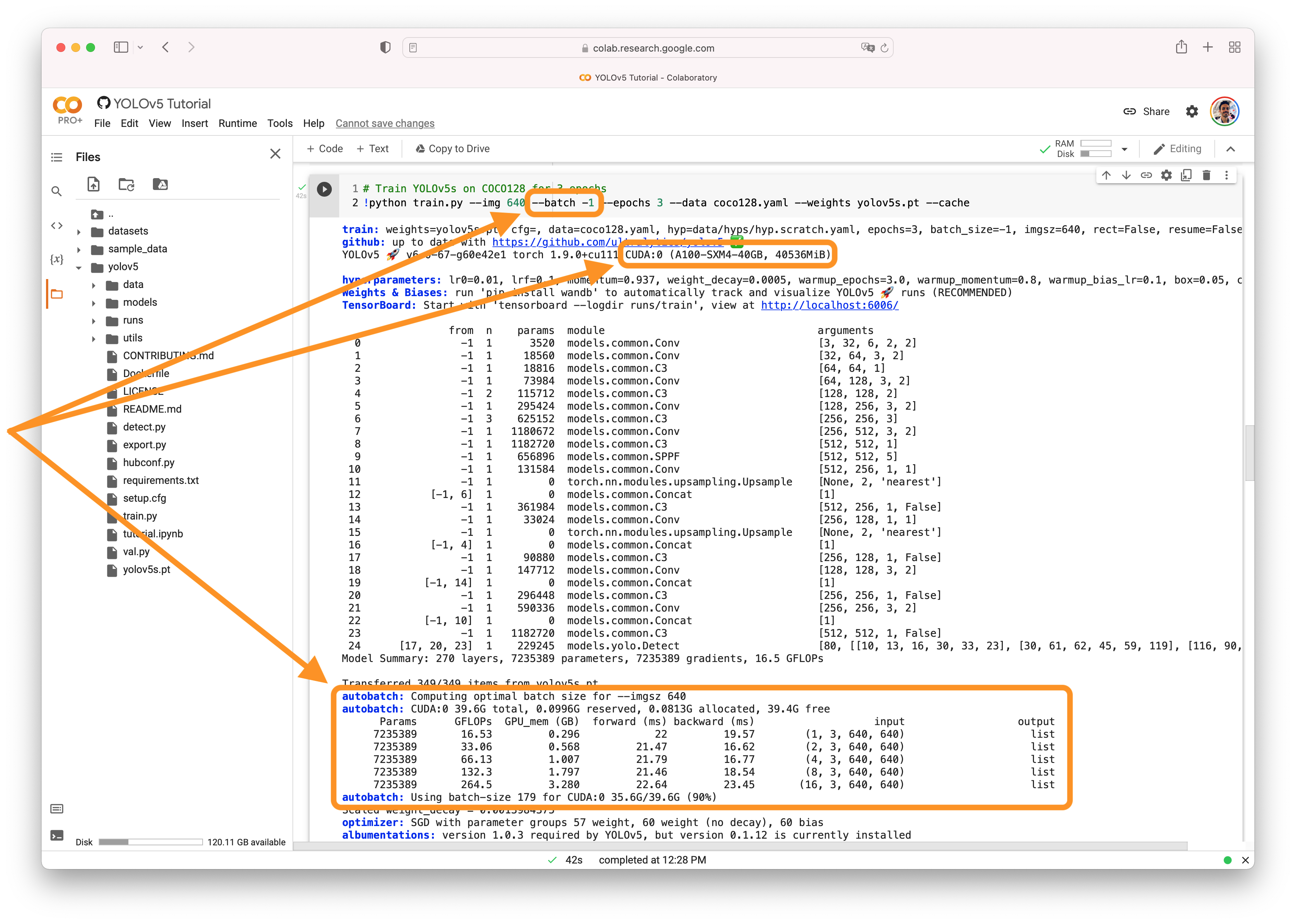
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |

|
While yolov5 seems to had a very stable memory usage, it seems that yolov8 doesn't have this benefit. Even when runing ray optimization, I decided to go low enough on the batch size to only use 20Gb of vram out of my 40 available, yet it still managed to crash (OOM) when I let it ran for few hours. |
|
@ExtReMLapin hello! We're sorry to hear that you're encountering memory-related issues while running YOLOv8 👎. If you encounter a CUDA Out Of Memory (OOM) Error, it is typically the result of a lack of available memory to perform a specific task. To help avoid this, we recommend lowering your batch size and/or reducing your training image size. If this does not work and you have a larger GPU, you could try increasing your GPU's memory to run your models. Another option that you might want to consider is tuning the We hope that helps! Let us know if you have any additional questions or run into any other issues. |
|
Sorry for the delayed answer, I guess the issue is the memory usage is unstable, hear me out, with yolov5 the memory usage was very stage, while internally, there are allocations that are invisible in nvidia-smi because pytorch has reserved memory, with yolov8 it seems that for some reasons, deep in the training it needs to reserve more memory. Starting a training on 35gb used out of 40gb sounds safe, but crashing two hours later is frustrating. please take a look at the following error : Each epoch + evaluation takes about one minute, and at epoch 120, the training ran for two hours straight. There was nothing else running on the server. Here are some metrics from wandb
At the very end there is peak, but I'm unsure what it is, or if it's caused by the crash itself. |

|
@ExtReMLapin hi there, Apologies for the delayed response. It appears that the memory usage of YOLOv8 is more unstable compared to YOLOv5. While YOLOv5 may have hidden memory allocations that are not visible in Starting the training with 35GB of VRAM out of 40GB may seem safe, but it eventually crashes after running for a couple of hours. The error message you shared indicates that there was a CUDA Out Of Memory (OOM) error at epoch 129 when allocating additional memory. One potential solution is to reduce the batch size and/or image size during training to lower the memory requirements. Another option is to increase the available GPU memory if you have a larger GPU or consider adjusting the From the Wandb metrics you shared, there is a peak at the very end, but it's unclear whether it caused the crash or is a result of the crash itself. Please let us know if you have any further questions or if there's anything else we can assist you with. |
|
👋 Hello there! We wanted to give you a friendly reminder that this issue has not had any recent activity and may be closed soon, but don't worry - you can always reopen it if needed. If you still have any questions or concerns, please feel free to let us know how we can help. For additional resources and information, please see the links below:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLO 🚀 and Vision AI ⭐ |
|
I have a similar issue. I have access to two NVIDIA A5000 GPUs with 24GB each. I use the pretrained yolov8m model. I get an OOM for an image size of 640 and a batch size of 4(!!). I am using cached images on disk for the training, but the error message says:
Why does PyTorch reserve 18GB? That does sound like it is too much. |
|
@thurnbauermatthi hi there, The PyTorch CUDA out of memory error you're encountering generally indicates that your GPU does not have enough memory to store the computations needed for training your model. In your case, with the pretrained YOLOv8m model, image size of 640 and a batch size of 4 on NVIDIA A5000 GPUs, it seems like PyTorch is indeed trying to reserve more memory than what's available on your GPUs. The memory reserved by PyTorch isn't just for the model parameters. It's also used to store intermediate variables for backpropagation, optimizer states, and more. Moreover, PyTorch tends to cache memory to avoid the cost of allocating and deallocating memory every time it’s needed. The memory requirement can increase with the complexity of the model, the size of the input data, and the batch size. While batch size and input size are more direct factors because they affect how much data is loaded into memory at once, the model complexity indirectly affects the memory requirement through the computational graph used for backpropagation. Here are a few solutions you could try:
I hope this information will help you! Let us know if there's anything else we could do to assist you. |
|
@glenn-jocher |
|
@dt140120 hello, Thanks for reaching out. It appears you're experiencing an Out of Memory (OOM) error when attempting to train with a batch size of 4 and image size of 640 using RTX 2080 Ti (12GB). The GPU memory requirement for training a model is primarily affected by input data size and model complexity. In this case, your batch size, model, and input image size are likely demanding more GPU memory than the available 12GB during training. To resolve this issue, you could try several approaches:
Please note that these solutions come with trade-offs and can potentially impact the accuracy of the model. I hope this helps, and do let us know if you have further questions! |
Search before asking
YOLOv8 Component
Training
Bug
I landed up into the following Runtime Error several times whenever I pick any model from Ultralytics package. The error snippet, given below, I got for yolov5n.pt model. Interestingly, when I train the same model directly from Yolov5 github repository [https://github.com/ultralytics/yolov5], it works perfectly without any error. Even I was able to train the large model Yolov5l.pt also with no errors. So, essentially, it seems an issue with the memory management in Ultralytics package. Please look into it.
RuntimeError: CUDA out of memory. Tried to allocate 572.00 MiB (GPU 0; 23.99 GiB total capacity; 21.62 GiB already allocated; 0 bytes free; 22.67 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Environment
-- Ultralytics YOLOv8.0.57 Python-3.9.12 torch-1.12.0 CUDA:0 (NVIDIA RTX A5000, 24564MiB)
-- OS Ubuntu 22.04
Minimal Reproducible Example
No response
Additional
No response
Are you willing to submit a PR?
The text was updated successfully, but these errors were encountered: