why do i need to train from the pt model you have trained? #2990
Comments
|
👋 Hello @Fred199683, thank you for your interest in 🚀 YOLOv5! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution. If this is a 🐛 Bug Report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you. If this is a custom training ❓ Question, please provide as much information as possible, including dataset images, training logs, screenshots, and a public link to online W&B logging if available. For business inquiries or professional support requests please visit https://www.ultralytics.com or email Glenn Jocher at glenn.jocher@ultralytics.com. RequirementsPython 3.8 or later with all requirements.txt dependencies installed, including $ pip install -r requirements.txtEnvironmentsYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training (train.py), testing (test.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu every 24 hours and on every commit. |


|
@Fred199683 👋 Hello! Thanks for asking about improving training results. Most of the time good results can be obtained with no changes to the models or training settings, provided your dataset is sufficiently large and well labelled. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users first train with all default settings before considering any changes. This helps establish a performance baseline and spot areas for improvement. If you have questions about your training results we recommend you provide the maximum amount of information possible if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your We've put together a full guide for users looking to get the best results on their YOLOv5 trainings below. Dataset
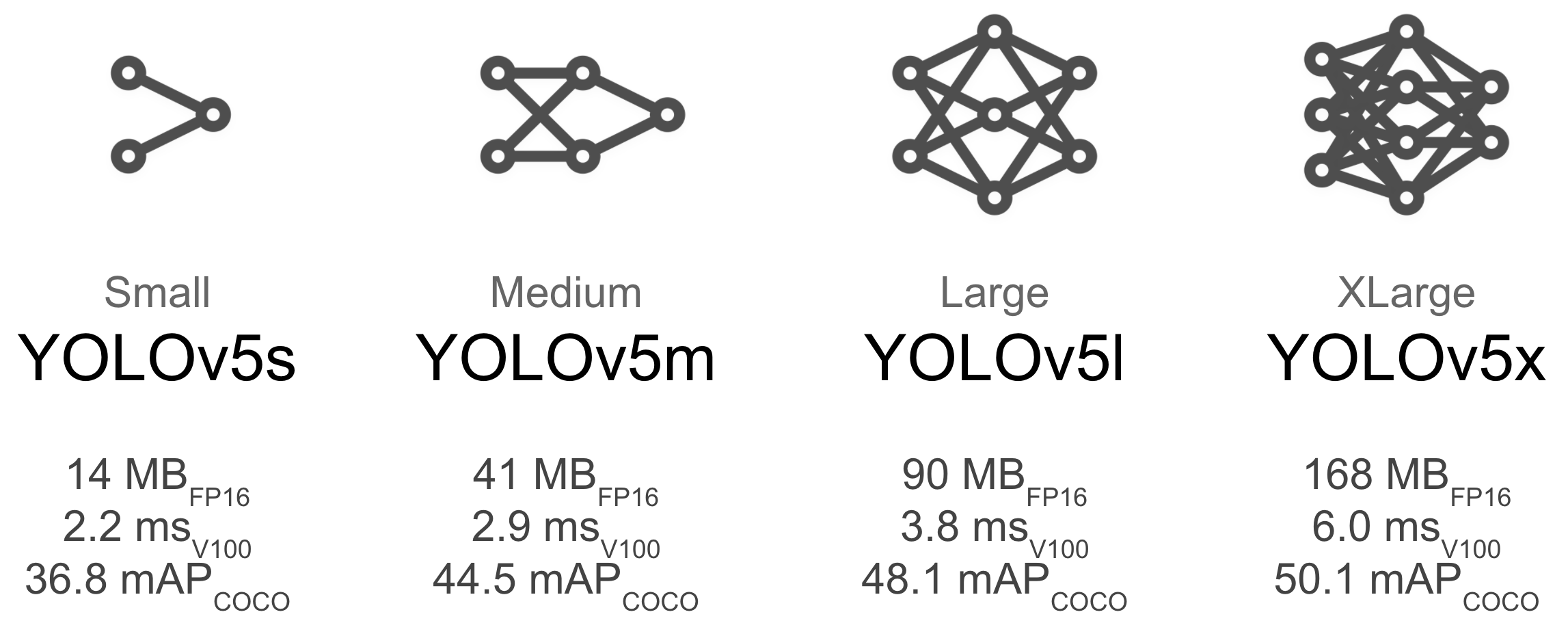
Model SelectionLarger models like YOLOv5x and YOLOv5x6 will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For mobile deployments we recommend YOLOv5s/m, for cloud deployments we recommend YOLOv5l/x. See our README table for a full comparison of all models.
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yamlTraining SettingsBefore modifying anything, first train with default settings to establish a performance baseline. A full list of train.py settings can be found in the train.py argparser.
Further ReadingIf you'd like to know more a good place to start is Karpathy's 'Recipe for Training Neural Networks', which has great ideas for training that apply broadly across all ML domains: |

Sry, i am wondering why u recommend us to train from the pretrained model u provided? train from scratch for 300 epochs will get worse result??? |
|
I think there will hardly be any difference. But since the filters in the beginning of the model are trying to obtain basic features(points, lines, curves etc.), these filters can be applied to many other applications without training from scratch. This reduce the training time needed. You might need 300 epochs for your model to fit your data originally, but by doing so you probably need only 100 epochs to converge. This is called "finetune" in training deep learning models. You can google it if you need further details. |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
Thanks for your repo. I am kind of confusing about why u recommend us to train coco128 from the pt model u provided. I mean the pt model is trained from scratch for 300epochs, so for coco128 i think why not train from scratch for 300epochs? if it's fine tuned from the pt model u provided, why it gets better results?(I think coco128 is a small dataset from coco, i think the pt model can works very well without fine-tuning.)
And if finetune from your pt model, so the weights is copied only from backbone? or from all(backbone+heads)?
Hope u can solve my problem, thank u!
The text was updated successfully, but these errors were encountered: