COCO Finetuning Evolution #918
Comments
|
Thanks @glenn-jocher . I’ve created a jupyterlab docker for evolve and set 4 containers to run. Would there be bottleneck if those 4 containers read from the same coco directory? |
|
@NanoCode012 The results of above process is weights of model or hyper parameter files? |
|
Hi @buimanhlinh96 , it evolves hyperparameters. It indeed takes a lot of time. Since I'm not using my GPUs atm, I'm letting them all evolve. It's quite fast since one generation is only 3.3 hours on each of my GPUs. Btw, @glenn-jocher , it may be good idea to make the batch-size an argument for the bash script too, as you've said, "2080Ti needs to use a smaller batch-size". On the other hand, I need a higher batch-size. Since you haven't uploaded the code here, I can't make a PR, but it should be something like this, # Hyperparameter evolution commands
while true; do
python train.py --batch $1 --weights yolov5m.pt --data coco.yaml --img 640 --epochs 10 --evolve --bucket ult/evolve/coco/fine10 --device $2
donethen, # Start containers
$bs = 32
for i in 0 1 2 3; do
t=ultralytics/yolov5:evolve_coco_fine10 && sudo docker pull $t && sudo docker run -d --ipc=host --gpus all -v "$(pwd)"/coco:/usr/src/coco $t bash utils/evolve.sh $bs $i
sleep 60 # avoid simultaneous evolve.txt read/write
done |
|
@NanoCode012 awesome, great! We can see the realtime results here, we already have a bunch of generations. Not too much change yet though. Ah yes, you are right. I'm not great at bash, but maybe there is a way to make the docker command execute an arbitrary bash script that would include the while loop with train.py and skip evolve.py? EDIT: for reference, initial mAPs (gen 0) were 0.613 and 0.412. @buimanhlinh96 results of hyp evolution is a hyperparameter file. You then train with this hyperparameter file, i.e.: |
Oh, I see. I thought the initial were the lowest results. Then, I guess there isn't much change as you've said.
I think the current method works well. All a user has to do is copy the "start container" code and run it. # end dockerfile
CMD ['python','train.py','--evolve']but you could pass in environmental variables to a docker call |
|
@NanoCode012 no, evolve.txt is read, updated, sorted, saved, and uploaded (if bucket) after each generation, so the top row is the best result. Unfortunately chronological results are not available currently. Just checked, we have 60 generations, but the top result is not moving much, currently at 0.617 and 0.415, vs 0.613 and 0.412 originally (not 0.413). Let's wait a bit more. |
|
@glenn-jocher is there a way how to use weighted fine-tuning? So far I found in code only this hard-coded Line 496 in c8e5181 which means that alternative elif parent == 'weighted' never runs... correct?
|
|
@Borda ah, this line is part of the genetic algorithm parent selection method for the next generation. If parent == 'single', then a single parent from the top n population is randomly selected for mutation based on their weights. The highest fitness parents carry higher weights, and are more likely to be selected. This is the default method. If parent == 'weighted', then the top n population is instead merged togethor using a weighted mean, where the weights again are the individual fitness. The selected parent is then mutated based on the mutation probability and sigma, and this child's fitness is subsequently evaluated, and appended to the population list in evolve.txt when complete, whereafter the process repeats. # Select parent(s)
parent = 'single' # parent selection method: 'single' or 'weighted'
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combinationEDIT: yes, since parent is hardcoded as 'single', the weighted combination method is never used. |
|
Hi @glenn-jocher , I think the evolve has been plateauing. I recall that the top hyp has been constant for more than 100 generations/3 days.
What should be the next step? Should we try to do a full 300 coco scratch run on the 5m with the new hyp? Evolving with 20 epochs? I used one of the top hyps to finetune for 20 epochs. I notice that the warmup strategy doesn't make a drop in the mAP at the start too, so that's good.
The below is for finetuning 10 epochs for comparison.
We see that the hyps may be overfitting to 10 epochs.. Edit: I stand corrected. It would seem that mAP 0.5:0.95 just hit 41.9 |
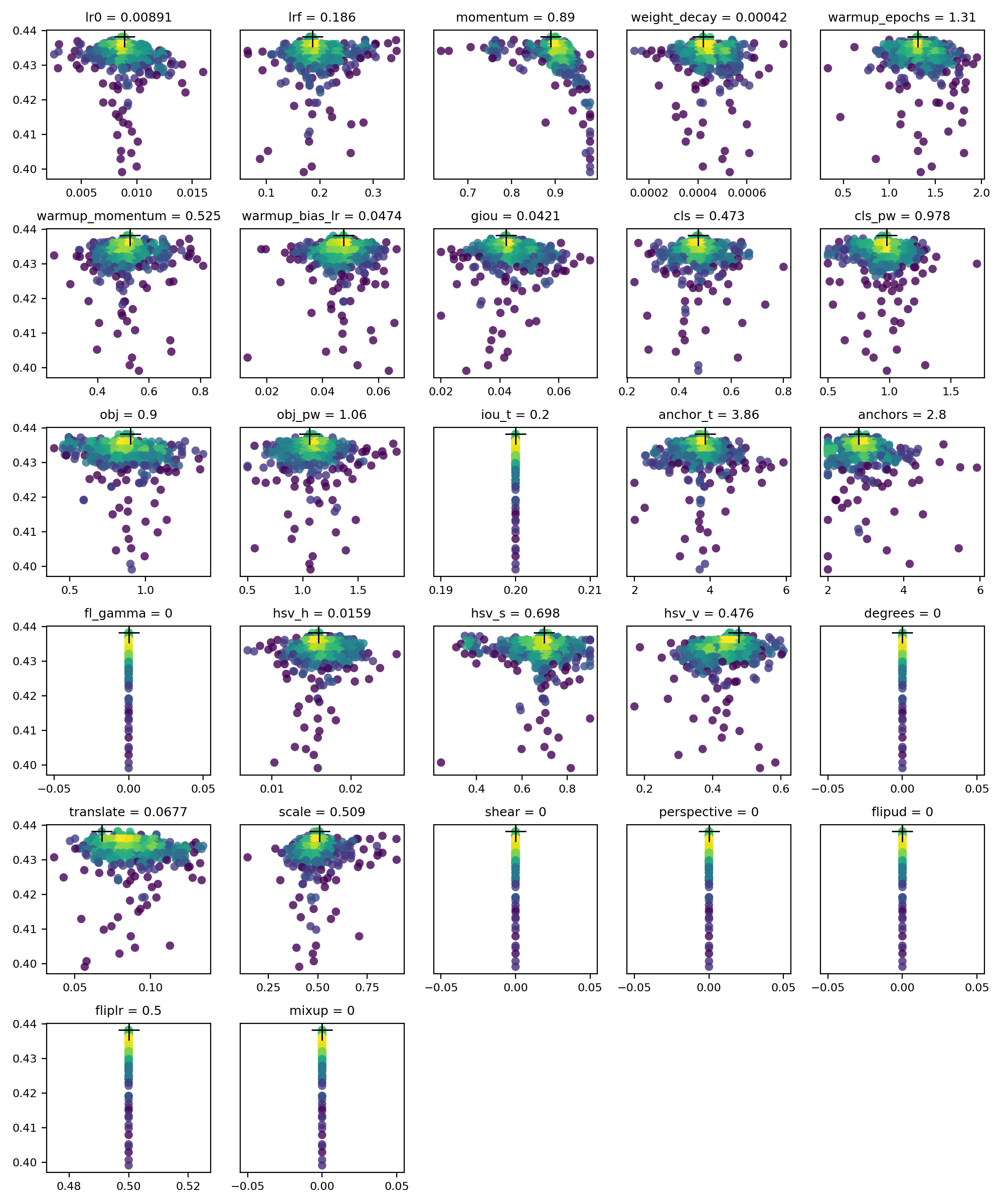
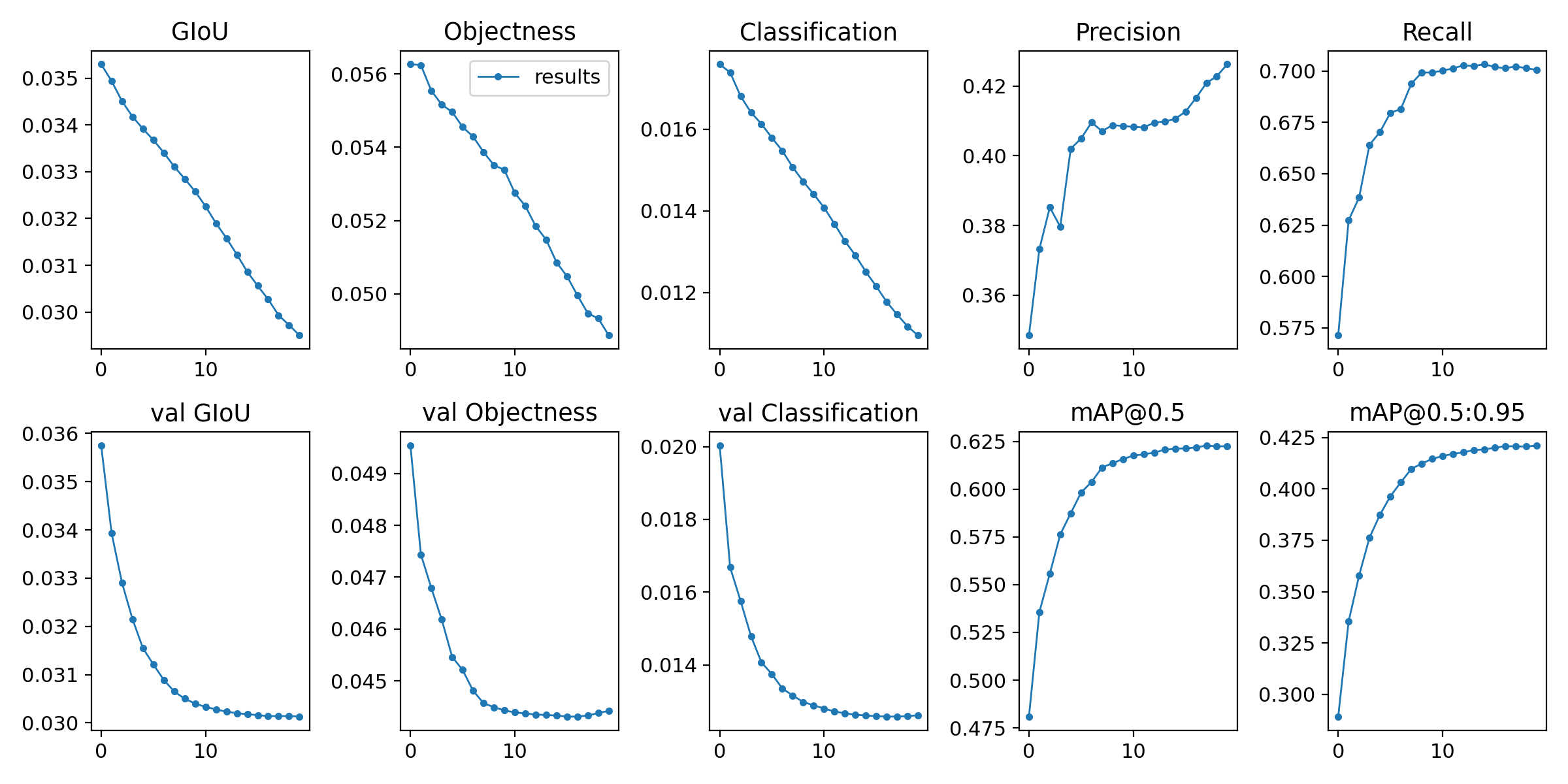
|
@NanoCode012 hey good analysis! Yes you are right, we are settled into a local minima for a while now, and also as you said perhaps we are overfitting for 10 epochs. I've seen this pattern before, whereby most of the improvement occurs in the first 100 generations, i.e. the 80 20 rule is in good effect here, and after sufficient generations (i.e. maybe 200-400) there is no more improvement, indicating that the parameters have settled into a minimum. Unfortunately our results here are disappointing. For custom datasets it's not uncommon to see 5-10% improvement in both mAP@0.5 and mAP@0.5:0.95 when starting from the COCO hyps. I suppose this may be indicating that the optimal scratch hyps for a given dataset are not dissimilar to the optimal finetuning hyps. Before we do anything else I am going to add a timestamp to the evolution output, this should allow us to 1) more automatically track the number of plateaued generations, 2) plot the actual improvement vs generation to see what the curve actually looks like (I've never seen this), which should be interesting. I've also integrated most of the docker image changes into master now, and actually found out that the docker image may add some overhead in certain cases, so I've come up with a better evolution execution that simply relies on cloning a branch and running each GPU in it's own screen (no docker required). I'll try to get these changes done today and then I'll update here. |
|
Hi @glenn-jocher , could you provide the |
|
@NanoCode012 I've uploaded yolov5m results here: The very last epoch shows a bump because we used to have a line in train.py that would pass pad=0.5 on the final epoch, to match the padding used when testing directly from test.py. This caused best.pt to always turn into last.pt though most of the time, so I eliminated the line. Epochs 0-298 should be the same as what we see now when training. |
|
Hi @glenn-jocher , this is my brief analysis on the
Note:
This shows that the An interesting point is that the I also noticed a drop at epoch 2 (with warmup) for I have one curiosity. How would the new |
|
@NanoCode012 hey there, thanks for the analysis. I'm sorry, I've been busy recently with export and updating the iOS app. The app now has two new supercool features, realtime threshold settings (confidence and NMS) via slider and rotation to landscape/upside down, and uses all the very latest models with hardswish activations, including YOLOv5x, which incredibly runs at about 20-25 FPS (!) on an iPhone 11. I've also drafted a plan for easier export with pytorch hub, so users can load a pretrained model and simply pass it cv2/PIL/numpy images for inference, with automatic letterboxing and NMS, without any complicated pre/post processing steps. This should help usability, works without cloning the repo, and the same work can be reutilized for our pip package soon. Regarding the evolution, it's very interesting. I've evolved on a few custom datasets that always produce a very good jump in mAP, i.e. +10%, but for COCO I suspect the hyps may already be sitting in a decent local minima (from earlier evolutions on yolov3-spp), and so the potential improvements are harder to come by. My most recent experience is this. I had 3 datasets I was working with: COCO, VOC, supermarket (custom). I finetuned VOC using I finetuned supermarket dataset using both But our COCO finetuning evolution did not produce good results. The conclusion is that coco hyps may already be decently evolved. Second conclusion is that it seems very hard to generalize hyps across datasets, and indeed the VOC and supermarket hyps are nothing alike. Hyps do seem to generalize well across models though, as all 4 models improved similarly in my above experiments, even though I evolved only yolvo5m. One other item to note is that many hyps really require full training to correctly evolve. For example weight decay will always hurt short trainings (i.e. 10 epochs), but usually always helps out longer trainings (i.e. 300 epochs), so 10 epoch evolutions will surely always cause weight_decay and many augmentation settings to reduce, which will hurt when applied to 300 epochs |
No worries. I am amazed how you could manage this repo and your own work at the same time!
This is interesting. Do you mean to say
It could be a combination of both. Since there are so many different kinds of datasets, I don't think it's possible for a one fit all scenario. It would be better to provide many hyps that people can choose from although that would defeat the goal of simplicity for this repo.
I'm going to test with changing a few hyps (like warmup) from the Edit: It could also be that 10 epochs evolve is too short, and we should go with a larger epoch number. |
|
Hi @glenn-jocher , glad to see you back. I've also got caught up with some stuff irl, but I got some results from some random trainings I proposed above. Commit: 7220cee
Notes:
Problems:
I proposed 2 ideas above on what to do next for hyps.
Would it be logical to have hyps for each dataset and letting users test them out? |
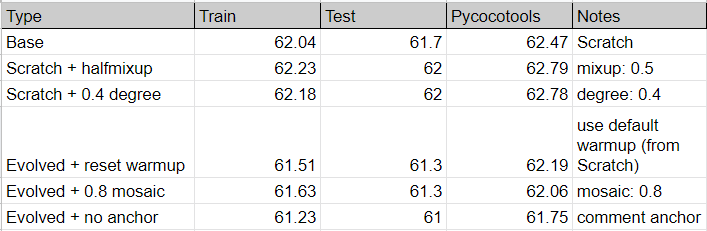
|
@NanoCode012 hmm, ok lots of things to think about, I'll sleep on it. To quickly answer your questions though:
Yes, I think it definitely makes sense to simply label the hyps for each dataset. For example hyps.finetune.yaml are actually VOC finetune hyps, which oddly enough are quite different than COCO hyps: |
|
Hi @glenn-jocher , I would like to just give an update. I tried to fine tune evolve for 30 epochs for around ~150 generations. I got around 62.8 and 42.6 as the map 0.5 / 0.5:0.95 respectively. I tried to use those hype to fine tune from the 5m and only got 62.4 / 42.6 (from test.py). I’m not sure why using the same hyps do not get the same results. Is there some random factor at play? Anyways, the results are just below the current 5m models, so I think finetuning is not the way to go. I haven’t tried using the hyps to train a full model, but I doubt it’ll be fare much better. |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
@hal-314 any luck integrating optuna or ray tune on yolov5? |
|
@lleye I didn't try it. |
just curious, is there any hyper-param sharing to avoid duplicate runs with the same configuration on different devices? |
|
@Borda this is a fascinating topic because the default Single-GPU evolution is essentially GE with population size 1 for 300 generations (with elitism and mutation). As you introduce more GPUs, i.e. following the above example for 4 GPUs, evolution starts to behave more like population size 4, which I've observed to produce worse results if you assume the same computational time total, i.e. 4x75 is worse than 1x300. 4x300 is better than both obviously, but most people will probably use Multi-GPU to evolve less generations. To answer your question, no this is not a problem, only at the very start of training will all GPUs train with identical hyperparameters (for 1 generation), then afterward every GPU will pull from the common evolve.csv to get the very latest results before mutation and training. This is expandable to multi-node also with the --bucket argument, where evolve.csv is sent to a GCP bucket and all nodes all GPUs download and upload this same evolve.csv file. In the --bucket scenario you can be evolving on distributed resources, i.e. a Colab notebook, your on-premise hardware, AWS and GCP instances can all be evolving simultaneously to the same central |
|
One more question the way of using multiple GPUs is to spin multiple docker, correct? |
|
@Borda you can run any number of GPUs in a Docker container. The main benefit of the Docker image is the isolated environment, i.e. torch and all the dependencies are already installed and functioning correctly, and reproducible across Windows, Linux, MacOS. The images also have yolov5 git cloned, but you can also clone any other repo/branch/fork you want and run that also instead. |
that sounds cool, do you have somewhere dritten what CUDA is used? |
|
@Borda actually the node has it's own CUDA and then the container also has its own. In our case the node is on 11.2 and the container is on 11.4. The YOLOv5 containers start from NVIDIA PyTorch base images at https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch Lines 1 to 5 in cb2ad9f
|

|
@glenn-jocher thank you, just one more question, seems that the docker names are quite outdated, and would it be possible to share what is inside the |
|
One more question, just found docs that suggest using |
|
@Borda nohup is just a bash command to run in background. Docker image is just an environment, you can execute any bash commands you want. Imagine Docker image like a venv, except its an entire Linux OS instead of just a Python environment. |
|
@Borda the Docker purpose is largely the same, you can reproduce the same results across different hardware/OS, and if you break your container you can just delete it and spin a new one up. |
🚀 Feature
COCO finetuning evolution will attempt to evolve hyps better tuned to finetune COCO from official (pretrained COCO) YOLOv5 weights in https://github.com/ultralytics/yolov5/releases/tag/v3.0
A docker image has been created at ultralytics/yolov5:evolve with a new hyp.coco.finetune.yaml file identical to hyp.scratch.yaml, but with added hyps for warmup evolution:
Image train.py has been updated to accept these additional hyps:
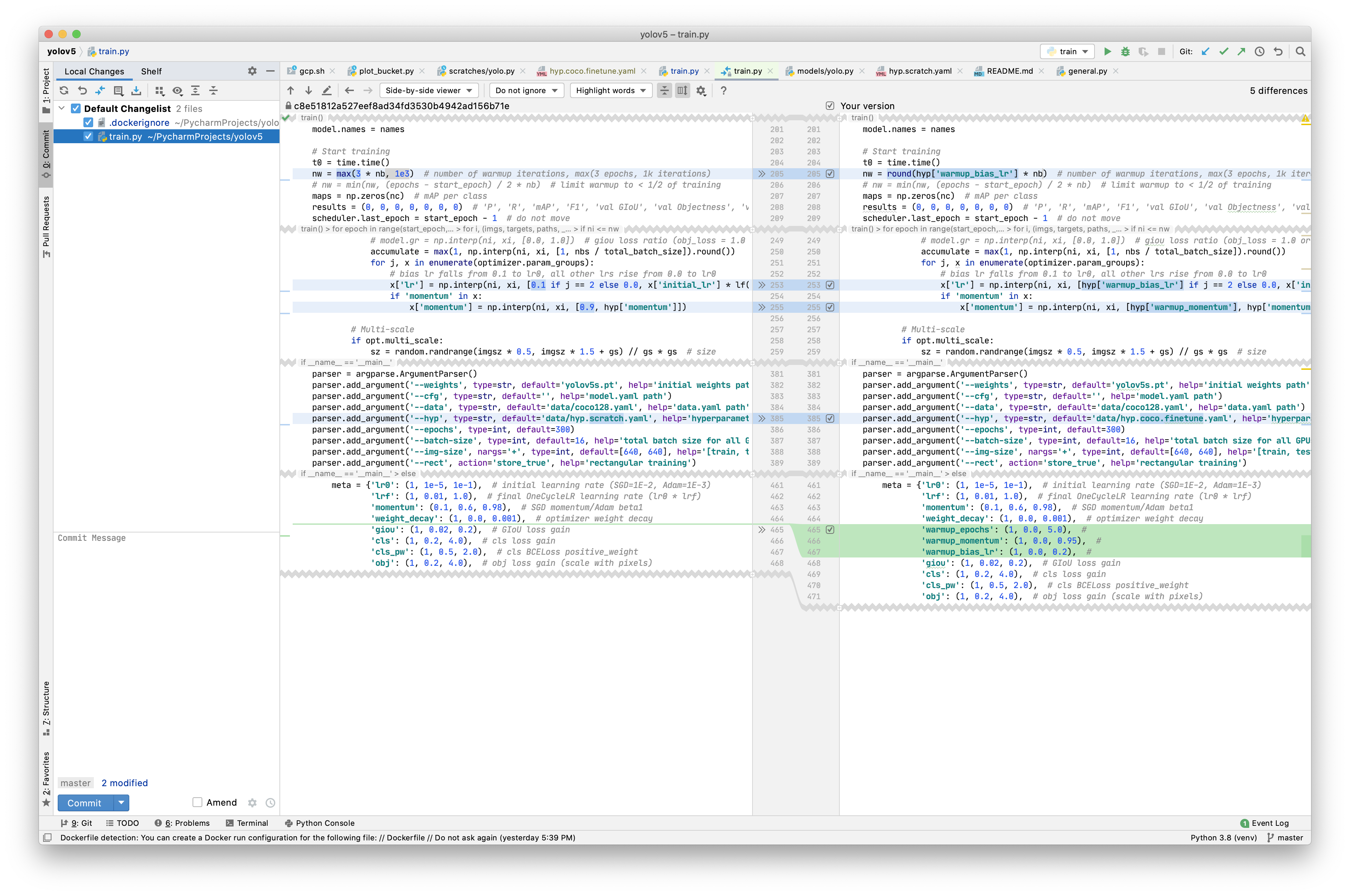
Initial evolution will use a shorter training schedule to maximize evolution rate for 300 generations:
Pending analysis of above results, a longer period may be used to reduce overfitting and improve results:
@NanoCode012 and anyone with available GPUs is invited to participate! We need all of the help we can get to improve our hyps to help people better train on their own custom datasets. Our docker image reads and writes evolution results from each generation from a centralized GCP bucket, so multiple distributed nodes can evolve simultaneously and seamlessly. The steps on a unix machine are:
1. Navigate to (or download) COCO
Open a new terminal and navigate to the directory containing
/coco, or download usingyolov5/data/scripts/get_coco.sh:2. Pull Image
Pull and run docker image in interactive mode with access to GPUs, mounting coco volume:
3. Evolve
From within the running image, select your
--deviceand run this loop to start evolution. When you want to free up resources or stop contributing, simply terminate the docker container. Runsudo docker psto display running containers, and thensudo docker kill CONTAINER_ID. Restart anytime from step 2.Optional parallel evolution on a multi-GPU machine, one container per GPU for devices 0, 1, 2, 3:
4. Batchsize
--batch 32 uses about 11.9GB of CUDA mem. If you are using a 2080Ti with 11GB you can use the same commands above with --batch 28 or 24 with minimal impact on results.
The text was updated successfully, but these errors were encountered: