Document Retrieval. How to integrate with Vespa in external apps #3628
Comments
|
For feeding to Vespa clusters from external systems which is not part of your Vespa cluster we recommend http://docs.vespa.ai/documentation/vespa-http-client.html. For reading single get operations from Vespa the http RESTful API for GET described in http://docs.vespa.ai/documentation/document-api.html is the best option. The RESTful API for GET is built on top of the http://docs.vespa.ai/documentation/document-api-guide.html which is a low-level api to use on nodes which are part of a Vespa cluster already and have access to configuration like schema and content clusters and number of nodes. |
|
thanks @jobergum also, would be great if you can point out where can i refer for refresh-interval (or anything such analogous to elasticsearch refresh-interval). sorry for terse questions but the suggestions are helping me ramp up :) |
|
Maybe you could describe your use case, at least give an overview of what you are trying to use Vespa for? Is the primary use case to use Vespa as a key=> value store using GET operation? You don't need to get into specifics but some high level description would help us guide you in the right direction. http://docs.vespa.ai/documentation/elastic-vespa.html tries to explain document distribution/replication and how search is treated differently from get/visit operations. (Search is s scatter & gather across potentially all nodes) Vespa is designed to be real time so once you your document has been accepted it is live in search. You can control visibility-delay which by default is 0: http://docs.vespa.ai/documentation/reference/services-content.html#visibility-delay. We are here to help so feel free to ask any questions you like. |
|
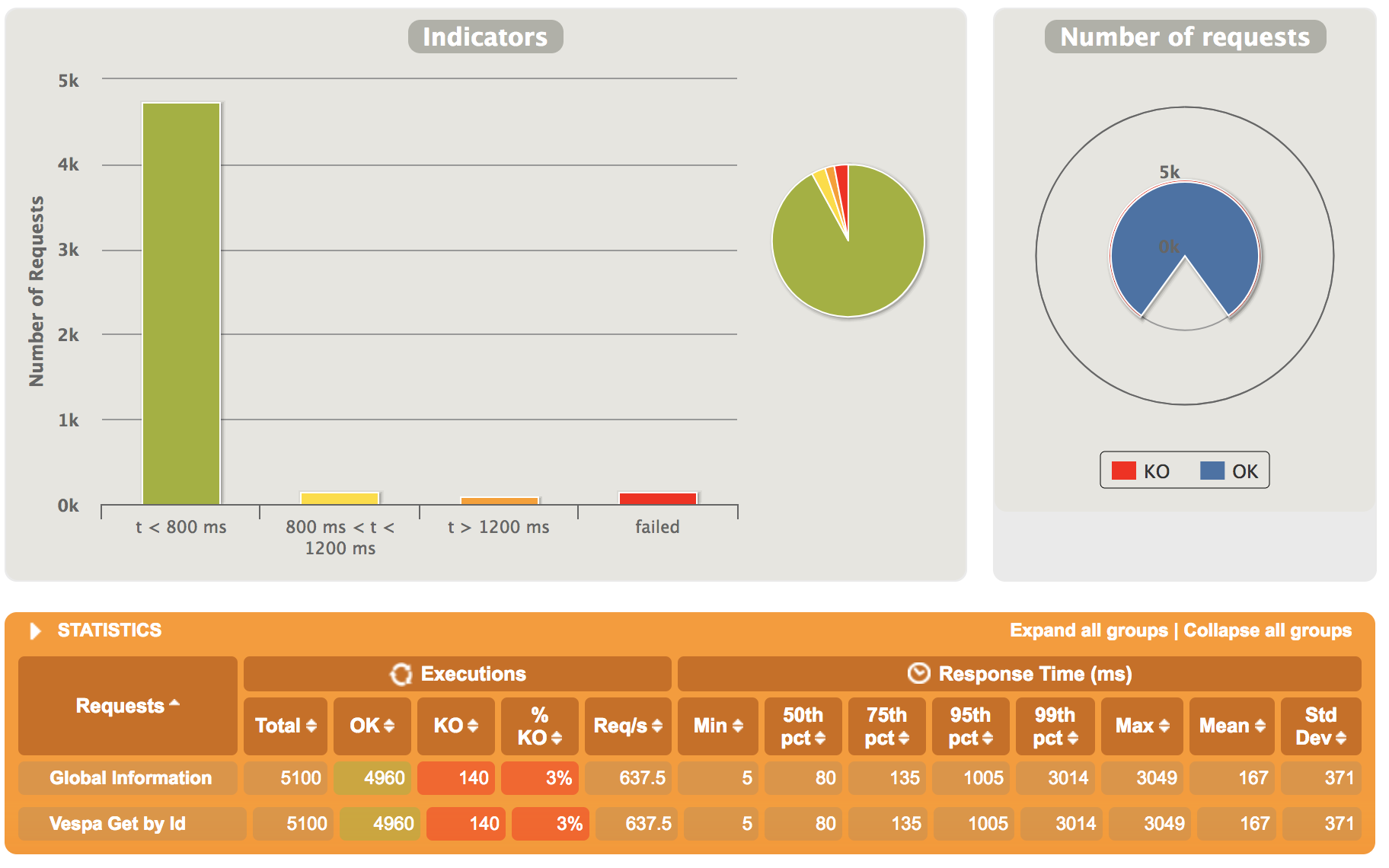
in very short, i am analysing Vespa as a viable alternative of Elasticsearch. as a positive sign, i've benchmarked Vespa on ~ 18G data (12mil documents) and have observed it perform better than ES under heavy concurrent load (though i used only REST interface and am now looking to make it better with Document API). e.g.
another important aspect is query aggregations and http://docs.vespa.ai/documentation/reference/grouping-syntax.html is very handy. thanks for pointing to visibility-delay. i sure forgot about that! additionally, i hope this helps. |

|
If i understand you correctly the primary use case is using vespa as a key value store which also vespa can be used for but is not our primary focus. Regardless get performance and scaling: Get is random access so performance really depends on the performance of your IO subsystem unless there is significant locality where caches can help. Vespa memory maps summary files (where content is stored) but you can also enable summary level cache which saves cost related to decompressing (http://docs.vespa.ai/documentation/content/setup-proton-tuning.html#summary-store-cache) if this is enabled directio should be used for summary reads to avoid using both os buffer cache and the application level cache. The GET interface described here http://docs.vespa.ai/documentation/document-api.html is tested internally as part of our internal performance test framework. For average 7 KB documents (single data field with indexing:summary) a single vespa instance (container & content) running on a single node is able to do 35 000 requests/s with no cache locality (unique requests) on a node with 2xE5-2680,1x 960GB SSD,10Gbps. At this rate of requests you are at about 2Gbps of network traffic. Replace NIC with a 1Gbps and you are down to 17 500 requests/s w, replace the SSD with a single spinning 7k rpm SATA and watch requests/s drop much further down and so on. |
|
please add some more to i am setting up a test with ~500G data (a smaller set from approx. 0.8 PB we run on in ES farm) on EC2 - [4 x (I3-4xLarge)] instances (16 vCPU, 122 G mem, E5-2686 v4 (Broadwell), 2 x 1.9 NVMe SSD) and hammer with full spectrum of search & rank analytics we want to drive through Vespa. my use cases will then expand to running Proximity Query, Cardinality Aggregation, Span Near Query and regular aggregations at scale. i did have a look at .idx, .dat and related file generation but am yet to ascertain if a full dataset will generate one monolithic index and how will access perform (with all above aggregation cases too as well) - pardon the gaps in my understanding..i am sure i'll plug this in few more hours. i am looking at proving real-time data updates and turn-around in queries as deep linking is fundamental to targeted solution space (in my use-case). edit : |
|
By that I mean that if you only want a keyvalue store for a static corpus there are other alternatives but if you need "Store, search, rank and organize big data" then you are at the right place. The summary store is log structured with a fixed size per summary log file and document get requests are routed to the correct summary log file and offset by a memory lookup. Data is stored in chunks for better compression ratio (zstd by default) so that is where the cache described above can help if requests have locality. The index & attribute data (in-memory) is really separate from the log store and is on a high level a memory index and a disk based index where the memory index is flushed and merged into the memory index. More on this in http://docs.vespa.ai/documentation/proton.html. On top of this comes documents db (schemas), redundancy and more. |
|
@shwetanks Can you paste a benchmark comparison between Vespa and Elastic Search , we are considering replace Elastic Search Cluster to Vespa. |
|
@theseusyang i am sorry for having lost this. vespa would potentially solve the matters but we shelved the effort for short time as deep aggregations are not supported very well. here are few discussions we opened for this that might help you decide based on depth of aggregations you perform https://stackoverflow.com/questions/46957804/how-to-make-aggregations-fast-on-vespa |
|
@shwetanks could you comment on what you mean by
|
|
Hi, compared to ES, we were not able to get faster aggregation on vespa on same hardware and similar dataset. the report with 1 thread per search. https://github.com/yogin16/tweet-vespa-app/blob/master/cluster-detail.md when aggregation query was timed out after 20 secs on 50M docs. and taking more than 10s for 1.5M matching docs. after further suggestions from documentation and from the stack overflow answer, we ensured:
Threads persearch is by default 1. After above changes we were able to get the search query to use 16 cores to 100% and aggregation was able to return just before 20 sec timeout. but which was still more time compared to ES's ~15secs. and there was no other writes or other query being served on the vespa cluster at the time of aggregation. We learned that Vespa is not made for aggregations with primary goal. The latency for write and search are much less than ES with same scale on identical hardware; but not aggregations, specially on multi-valued string field. |
|
Great write up @yogin16 and thanks for the clarification. |
|
Thanks @jobergum -shwetank |
|
Another question. If I want feed a binary file e.g. image or video file not a json file, does Vespa have the corresponding feed api? or using the existed feeding api? @jobergum Thanks ! |
|
@shwetanks we really appreciate your detailed feedback and we'll re-visit the performance of your specific use case with grouping over multi-valued string attributes with many unique values. @theseusyang You'll need to write custom connectors to extract meta data out of the binary data. |
|
Some more details to @theseusyang (next time create a separate ticket though, or use Stack Overflow): You can feed binary data directly by base64 encoding it: http://docs.vespa.ai/documentation/reference/document-json-put-format.html#base64 If you want to extract structured data into other fields from the binary content write a document processor to do the extraction: http://docs.vespa.ai/documentation/docproc-development.html |
|
hi guys! i've also been intently searching if vespa.ai has opened any IRC (we were talking about slack last time) where issues can be linked to and followed up with..will be of great help. |
|
Sorry, we haven't done any optimization of grouping over multi-valued string attributes with many unique values since we last discussed. It's on our backlog. No irc but we have a Gitter: https://gitter.im/vespa-engine/Lobby |
|
Closing this issue as work is tracked in other issues - thanks for contributing! |
Hello Vespa!
I am looking for an overview on what is required and how to connect with Vespa for retrieving indexed data at scale.
i've run stress tests on Vespa document RESTful API and as suggested in documentation, it has an upper bound.
http://docs.vespa.ai/documentation/document-api-guide.html
indicates the way forward but assumes a head-start on subject matter.
i can figure MessageBusDocumentAccess
and related stuff.
MessageBusDocumentApiTestCase is also a good pointer but to simply accept, it's quite large to put together fast.
The trouble is i can't find, if documented, any guide to clearly explain how to invoke vespa from an external system, or if that's not possible, clarify that it's only a fat client / has to be run as an embedded client and how it talks to vespa cluster.
please point me to if such an overview exists.
is DocumentRetriever.java the way forward? what other choices does one have?
thanks!
The text was updated successfully, but these errors were encountered: