UnexpectedAdmissionError Allocate failed due to rpc error: code = Unknown desc = failed to find gpu id, which is unexpected #2701
Comments
|
currently, we only support using volcano.sh/gpu-memory or volcano.sh/gpu-number, setting them both is not supported right now, it will be implemented in the next version |
|
@archlitchi no I just use volcano.sh/gpu-memory , I don't know where you get this info. I just run the example on your install md |
|
volcano-controllers error log |
|
could you show the log of volcano-device-plugin plz? |
|
volcano-device-plugin |
|
Oh, I found that why get this prolem volcano-scheduler-configmap format wrong - name: predicates
arguments:
predicate.GPUSharingEnable: true # 打开GPU share 开关But I get another error I use this https://github.com/volcano-sh/devices/blob/release-1.0/volcano-device-plugin.yml |
|
@631068264 please use the master version yaml instead |
|
Pod are running but I can't find any processes from
|
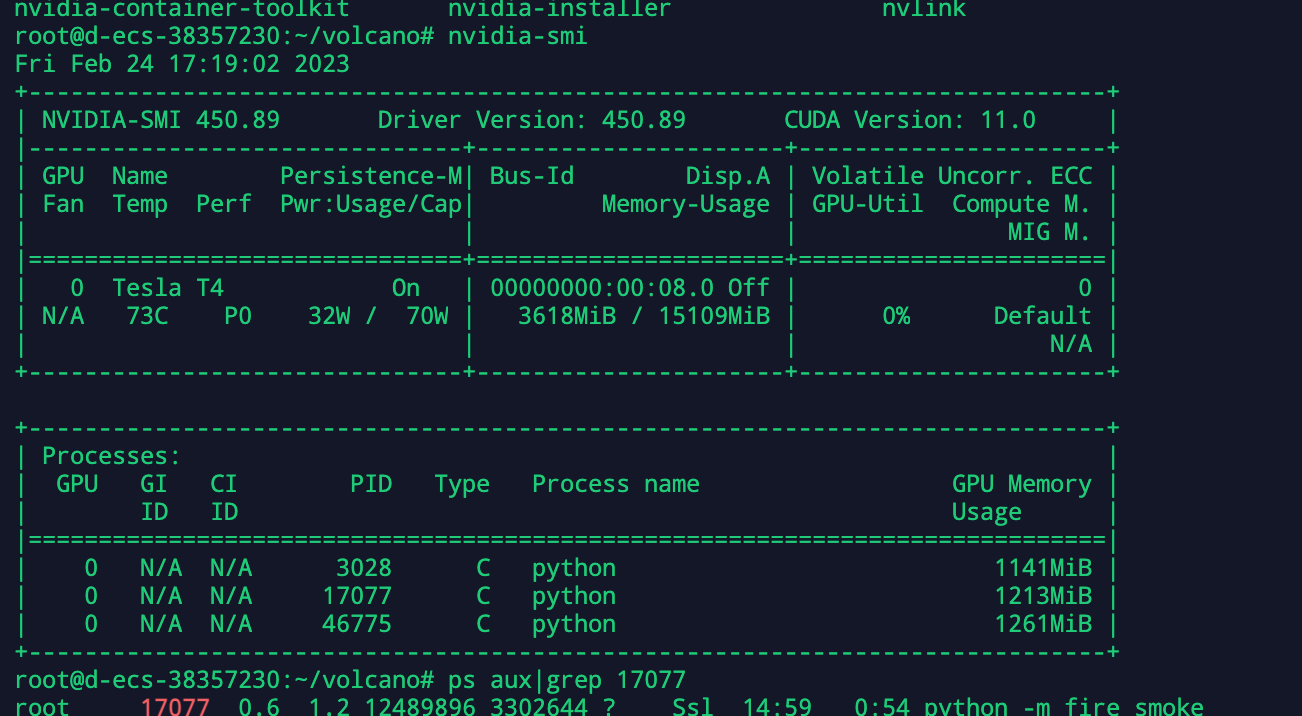

|
And I want to know that schedulerName is required ? How about another crd for example kubeflow inferenceservices Or only volcano.sh/gpu-memory is required ? |
|
I use kubeflow 1.6.1 to deploy not work But get error |
|
yeah, you can't see any process in nvidia-smi inside container, it's natural because the pid namespace is different. Currently you have to specify schedulerName to volcano in order for the gpu-share to work. |
No , this three process are running in docker container which I use NVIDIA Operator as device plugin |
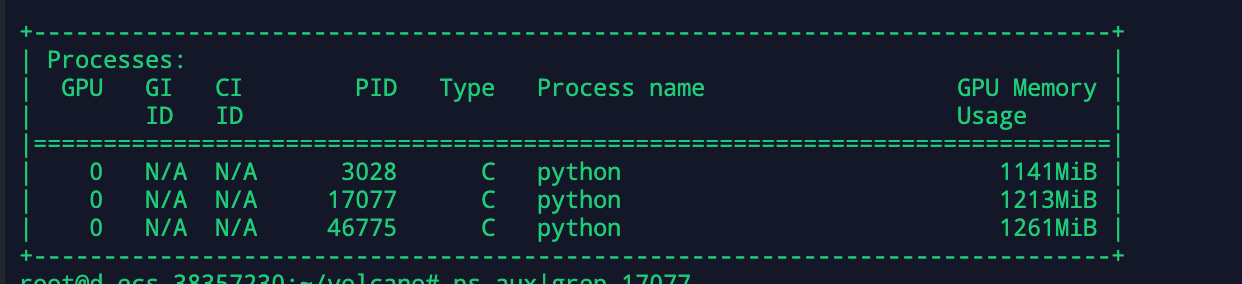
nvidia operator does apply a dozen of improvements for the original nvidia-device-plugin, including fix this problem. however, if you choose to deploy nvidia-device-plugin directly, you will encounter the same problem |
|
You can do a simple test, download and install nvidia-docker2, mount GPUs into container by using command "docker run -it --rm -e=NVIDIA_VISIBLE_DEVICES=all --runtime=nvidia {your image} {command}" |
What happened:
try to deploy example pod to test fail and follow this https://github.com/volcano-sh/volcano/blob/master/docs/user-guide/how_to_use_gpu_sharing.md to do
What you expected to happen:
How to reproduce it (as minimally and precisely as possible):
Anything else we need to know?:
Environment:
kubectl version):uname -a): Linux d-ecs-38357230 4.15.0-128-genericThe text was updated successfully, but these errors were encountered: