Proposal: making ruby breakable #19
Comments
|
At the meeting on 2022-8-16, the following points were requested.
They will be reflected to the proposal above (done!). |
|
I have some concerns about this, mostly having to do with the complexities of layout and how to adjust the spacing when a given ruby run is broken across lines.
|
|
Thank you Nat for sharing your concerns.
no, providing a subdivision is optional. I assume majority of rubies will not have subdivisions because providing subdivisions right now is a labour intensive work. I am hoping that in the future we have better tools, and we have text engines that are aware of the content of the text and provide sophisticated breaking points automatically.
Today, showing reading for the word on a character-by-character basis is not possible unless you make each character a mono-ruby. Jukugo ruby is a superior method, but it is not supported by most implementations. I am hoping that the proposal with expanded use of subdivisions makes it more appealing to the developer community.
Right, the subdivision is to be used as you mentioned. Whether the specific reading can be applied outside the context depends because, for example, there are cases where a Kanji is read in a certain way only within a particular jukugo. 'Rendaku' is another similar case.
Right, it is a compromise like I mentioned in the proposal. A compromise between a big justification amount with large spaces between characters, and potentially unfamiliar division of rubies when you have a long ruby hanging at the end of a line. At the same time, the proposal provides a way to restrict breaks to very long rubies only or to entirely prohibit breaks. By default rubies are unbreakable when it is equal to or under two fullwidth character length.
not sure. If you know the breaking opportunities for the base text (which you already know) and ruby text (new), you can relatively easily figure out the optimal breaking point.
Unless a break happens, all subdivisions are put together and it behave like one monolithic ruby. I will clarify this point in the proposal. When a ruby (e.g. aka group ruby) is broken into two lines, I assume each part will behave like independent rubies, one at the end of a line and the other at the beginning of a line. This might be an area where we can come up with a better layout recommendation to improve the readability of broken rubies. Bin-sensei mentioned that are are books with such examples. We could extract something from these books and/or discuss with people who are working with such a layout. |
|
One reason InDesign (and I assume others) did not implement jukugo ruby is due to the overhang allowed when unbroken, causing the different width broken to unbroken problem and how that affects layout complexity and performance. Mono ruby and group ruby can, in a static world, be used to achieve most of the layout possibilities of jukugo ruby manually. I hope that more engines explore supporting jukugo ruby in dynamic layout in the future, because if that remains "too hard", then breaking ruby anywhere and preserving the overhang and spacing required for good quality will also be "too hard". The easy way is just throw ruby above the base and not bother with all that, but that will be a big step backward. |
Do you have an idea on how jukugo and foldable ruby can be changed with a good compromise to solve the issue? Does simple-ruby solve that issue? Let's discuss it at the next online meeting. The problem is that the width changes before and after the break, right? |
|
As seen in https://www.w3.org/TR/2008/WD-jlreq-20081015/ja/Images/img2_30.png, you can see the layout of the ruby over each base character, and the width of the base and ruby for each character changes if you break the line in the middle of the run. So, the engine must calculate all possible breaks and their corresponding layouts, which is "hard". |
{kind=link}
|
Now I understand. I believe we should come up with a simple/basic rule of breaking ruby that is without this complexity. It would not be optimal but should be practical. At the same time we will also describe an ideal layout rule. |
|
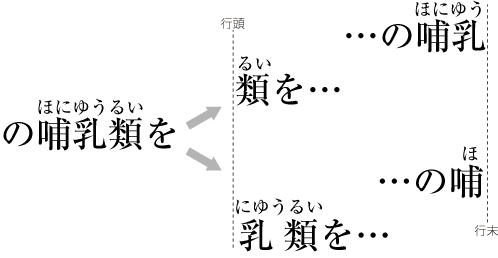
@macnmm , could you help me understanding the nature of the complexity a bit more in details? For simplicity let's assume for now overhanging part of ruby does not sits on top of the surrounding character. Assume you have a ruby block that is '哺乳類(ほにゅうるい)'. First you might want to see if the whole fits at the end of the line you are working on. It does not. Then you see if the first character fits. Assume the base character '哺' fit. Now you look at the ruby and find the ruby fragment that corresponds to '哺', which is 'ほ'. The ruby also fits. Now you try to fit the second base character '乳' and find that it does not. Now you are done with composing the line. You start working on the next line. You process '乳類(にゅうるい)' normally. Now you are done with processing '哺乳類(ほにゅうるい)' In the case of 周期律, you get the ruby fragment 'しゅう' that corresponds to the first base character. It is longer than the base by 1/2 of fullwidth. You find that it barely fits, or not. etc. For a moment I thought I understood the complexity but I found I did not… thank you for your help. |
|
Natさんのいう熟語ルビの分割の困難さは,理解できます.ただし,熟語ルビの字数は多くは2文字です.多くても5文字程度で,こうした字数の多いものは,数多くありません. となれば,蝟集(いしゆう)を例にすると,以下の例において,2つケースの文字列の幅を計算したデータをあらかじめ作っておけばいいのではないでしょうか? 小夜曲(さよきよく)を例にすれば,以下の3つのデータが必要になる. なお,熟語の場合,1文字1文字の読み方が問題となり,1文字1文字の読み方を漢字に対応させたいという場合がある.この場合は,モノルビで対応すればよいことになる.あるいは,上記の例に従えば,以下の対応のデータを作成しておけばよいことになる. 熟語のまとまりを重視したいか,1文字1文字の読み方を重視したいかは,著者なり,編集者の判断によります.実際の本でも,両方の処理例があります.(活版時代は,熟語のまとまりを重視派が多く,最近では処理の簡単さから1文字1文字の読み方重視派がやや増えているかなと感じています.) |
When composing ruby and base text, you first determine if the ruby is wider than the base text, and then whether or not the wide ruby is allowed to overhang the adjacent characters, to determine the final width of the base text/ruby combination. In addition, the positioning of the ruby above the base text is determined (kata-tsuki, etc). Knowing the final width, each completed block is then able to be put into the growing line width to find the line maximum. When the above calculations have to be redone for a given block/word when the ruby run is broken across lines, i.e. the width of the combination grows or shrinks, or the positioning of the ruby changes, or both, then you must do that calculation in the same step in anticipation of the possible line breaks. Paragraph composition is especially so, since it is done by pre-calculating all line breaks for the paragraph and choosing the best overall path for the best average color (=character and word spacing) over multiple lines. Any time the line break causes a width change or layout change (like when hyphenating Dutch words that change spelling) can cause this type of issue, but it is more severe with ruby layout due to how complex the rules are. |
|
macnmmさんの指摘された事項は,よく分かります. |
|
@KobayashiToshi 先生のご指摘の通り、ルビ文字列と親文字文字列は場合によって幅と文字の配置の計算を行頭、行中、行末のバリエーションで繰り返してやる必要です。熟語ルビの難しさは内部のインプリによるでしょうが、モノルビと違うのは複数の単語(親文字群)を同時に調整する必要です。モノルビの場合は各単語に閉じてできるのでちょっと簡単。 |
|
Simple Rubyは、レイアウトの最低限レベルと考えていただきたいです。高度なデザインのためにもっといいルビレイアウトは必須だと信じています。
そうです.Simple Rubyは,もし簡単化したいとしたら,こう考えられるよ,というものです.ですから,高度なルビ処理は,是非とも挑戦してほしいと思います.
それとともに,熟語ルビも,これまで多くの書籍で実際に行われてきたものですので,ぜひ挑戦してほしい課題かとも考えています.(もちろん,Simple Rubyで解説した熟語ルビの処理方法も,かなり単純化したものです.)
|
|
ブラウザベンダはルビについてこれ以上何もやりたくないと考えているというのが現状です。WHATWGへのpull requestで、WHATWGのsteering committeeまでエスカレートさせないといけなかったのがその証拠です。
これらを全部主張しても、実装されないW3C仕様が出来るだけになることは疑いありません。 |
|
村田さん、同意です。まずは基本的で重要なことをいかにシンプルに達成できるか、それにフォーカスすべきだと思います。説得するにはどうすれば良いのか。jlreq-d はここを戦略的に攻めるべきだと思います。
ただ同時に、jlreq-d は web のみを対象にしたドキュメントではありませんし、現状の技術者間の状況のみを対象としたドキュメントでもありません。ので、より望ましいやり方も同時に記述すべきでしょう。奥深さも欲しいと思います。これら二つが混在しないように、はっきりとわかるように書きくべきですね。
|
|
Thank you @macnmm . I understand that you need to pre-calculate all possible breaks for paragraph composition, and it would require a lot of computing power. In the case of line-by-line composition, which I guess most web browsers do, can it be done with a reasonable code complexity and performance? or is it still too much? I guess the ability to determine quickly the width of a given base-ruby combination, without working on the layout details, would be important. Can the ruby layout rules be adjusted to help making the determination faster? |
JLReq-d においてルビの折り返しを可能にする提案 (ver. 2.1)
提案 1
JLReqにおいて三種類あるルビ(モノルビ、グループルビ、熟語ルビ)を、JLReq-dにおいては一つの名前「ルビ」とし、これを統一的に説明する。JLReqにおけるルビの名前は組版用語として説明する。
提案 2
JLReq-dにおいて、ルビを折り返し可能にする。
a) 親文字列の任意の場所で折り返しを許し、ソフトウェアがルビを自動的に分割する。この分割には通常の行の折り返しの規則を用いる。折り返しの前後でルビ文字数がゼロになるのを避けるなど、分割のルールや考え方を示す。
b) ただし規定値として、通常の行長(どのくらい?)の場合、ルビ+親文字の長さが全角二文字分(ルビ5文字で2.5?)の幅以下の場合の折り返しを避けることとする。行長がより長い場合には全角三文字分までは折り返しを避ける。反対に行長がより短い場合には二文字分でも折り返しを許す。
c) ルビが分割される場合の分割位置を示すことができる。このため親文字とルビをサブグループに分けることができる。例えば「京都(きょうと)」のルビを単純文字数で二分割すると「きょ」「うと」となるが、サブグループを使って「京(きょう)都(と)」と分割するように指示することができる。これはJLReqの熟語ルビである。また「先端技術(ハイテクノロジー)」が「先端/技術」と分割されるならば、サブグループを使ってルビは「ハイ/テクノロジー」と分割するように指示することができる。これはJLReqの熟語ルビの援用である。分割されない場合には、サブグループを無視して一体のルビとしてレイアウトする(熟語ルビのそれぞれのルビが親文字をはみ出ない場合のレイアウトをどうするか決める必要あり)。
分割位置が示されていることは、b), d) によるの分割の判断に影響を与えない分割位置が示されている場合、分割位置は折り返し可能で、また部分部分には b), d) による分割可否の判断を適用する。部分親文字列の切れ目以外の場所で折り返す場合には、部分親文字列にルビ分割ルールを適用する。d) 選択可能な動作として、行長幅に対するルビ+親文字幅の比によって b の動作の閾値を調節できる方法、およびJLReqと同一の動作すなわちルビの折り返しを許さない方法、を備えることが望ましい。
e) 形態素解析などの手法を使い、指示のない場合でもより良い分割位置を自動的に探せる可能性がある。これは英文におけるハイフネーション辞書の利用と似ている。
背景
長いルビは、それが行末にかかった場合に大きな行の調整量を必要とし、読みやすさや美しさを破綻させる可能性がある。
活字組版時代にはグループルビという概念はなく、人の手によってルビの分割が適宜行われていた。コンピューターによる組版が行われる時代になって、ルビは分割禁止のルールで処理されるようになり、問題のあるケースは、目視による校正によって発見、対処された。実際に、書籍でルビを分割している例は多く見つけることができる(例を敏先生に依頼する)。つまりルビの組版は、コンピューターによる自動処理と人間による目視の協調作業により行なっていたことになる。ルビの画一的な折り返し禁止ルールは、人の目で検査修正するという前提において、合理的であったと言える。
デジタルテキストにおいては、人の目による検査修正は存在せず、さまざまな行長に対して完全に自動的にそれなりの組みになる必要がある。よって、折り返しを許すことで、時に違和感のある折り返しが現れ得るという欠点を受容しつつ、行の破綻を避けるためのルールを提案する。このルールはルビの折り返しを許すという意味において、JLReqにおける熟語ルビの概念の拡張として捉えることもできる。
親文字が二文字の場合には、折り返しを禁止しても、調整量は禁則文字による場合と同じとなる。よって、規定値ではこの分割を禁止し、特に熟語に対する違和感のある分割の可能性を少なくするのは合理的であろう。行が長い場合には三文字の熟語も分割を避けたいかもしれない。反対に行が短い場合には、そのような場合に禁則を緩くするのと同様の考えで、二文字の親文字も分割可能にすべきであろう。一般に、親文字列の長いほど、行長の短いほど、また特に両端揃えにおいて、ルビが行の組みを破綻させるリスクは増大する。リスクを避けつつ、短い親文字は折り返さない方法の提供されることが望ましい。また、JLReqと同様の動作の欲しい場合もあるだろう。
ルビ文字列の長い場合に対する考察が不十分かもしれない。
用語と説明方法
三種類もあるルビの名前を覚え、それぞれの処理方法を理解することがルビを難しくしている一つの要素だと思われる。三種類のルールをよく読めば基本は共通であることがわかる。統一して記述し、例外を記述することで、わかりやすくできる。基本は共通であり、機能の理解に用語は必ずしも必要がない。用語が増えるとそれだけで複雑に感じる。よって、シンプルに「ルビ」としたようがわかりやすくなろう。用語自体は、囲み記事か何かで教養のための組版専門用語として説明すれば事足りよう。
熟語ルビは、熟語ルビと説明するよりも「ルビを分割 (subdivide) するための機能」と機能の立場で説明した方が、技術者には分かりやすいと思われる。従来熟語ルビの必要性を技術者に説得できていないが、ルビの折り返し位置を調節する、という新たな役目の説明が説得の突破口になる可能性がある。
The text was updated successfully, but these errors were encountered: