whiterabbit #35
Comments
|
定位在帮助完成后续ETL工作的这么一个工具。 1.源数据可以是txt文件,也可以是各种数据库(MySQL, Oracle, SQL Server, and PostgreSQL)。 设置输出扫描报告结果的文件夹 连接源数据 测试连接是否成功 选择待扫描的表和字段,完成扫描 表与表之间映射 字段与字段映射 生成ETL文档 |








|
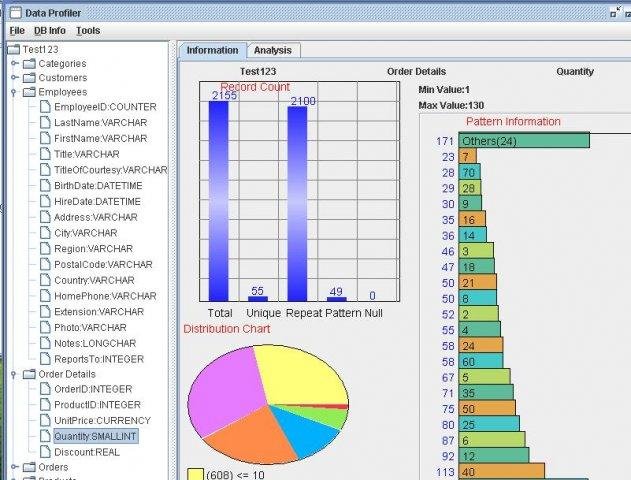
https://datacleaner.github.io/ The heart of DataCleaner is a strong data profiling engine for discovering and analyzing the quality of your data. Find the patterns, missing values, character sets and other characteristics of your data values. Interrogating and profiling your data is an essential activity of any Data Quality, Master Data Management or Data Governance program. If you don’t know what you’re up against, you have poor chances of fixing it. 1.连接数据源
3.完成扫描
|










What is Data Profiling? Process, Best Practices, Top 6 ToolsWritten by An Bui|June 19, 2018 Data processing and analysis can’t happen without data profiling—reviewing source data for content and quality. As data gets bigger and infrastructure moves to the cloud, data profiling is increasingly important. Need to achieve big data profiling with limited time and resources? Learn about:
What is data profiling?Data profiling is the process of reviewing source data, understanding structure, content and interrelationships, and identifying potential for data projects. Data profiling is a crucial part of:
Data profiling involves:
Types of data profilingThere are three main types of data profiling: Structure discoveryValidating that data is consistent and formatted correctly, and performing mathematical checks on the data (e.g. sum, minimum or maximum). Structure discovery helps understand how well data is structured—for example, what percentage of phone numbers do not have the correct number of digits. Content discoveryLooking into individual data records to discover errors. Content discovery identifies which specific rows in a table contain problems, and which systemic issues occur in the data (for example, phone numbers with no area code). Relationship discovery Discovering how parts of the data are interrelated. For example, key relationships between database tables, references between cells or tables in a spreadsheet. Understanding relationships is crucial to reusing data; related data sources should be united into one or imported in a way that preserves important relationships. Data profiling steps—an efficient process for data profilingRalph Kimball, a father of data warehouse architecture, suggests a four-step process for data profiling:
Data profiling and data quality analysis best practicesBasic data profiling techniques:
Advanced data profiling techniques:
6 data profiling tools—open source and commercialData profiling, a tedious and labor intensive activity, can be automated with tools, to make huge data projects more feasible. These are essential to your data analytics stack. Open source data profiling tools
2. Aggregate Profiler (Open Source Data Quality and Profiling)—key features include:
3. Talend Open Studio—a suite of open source tools, data quality features include:
Commercial data profiling tools4. Data Profiling in Informatica—key features include:
5. Oracle Enterprise Data Quality—key features include:
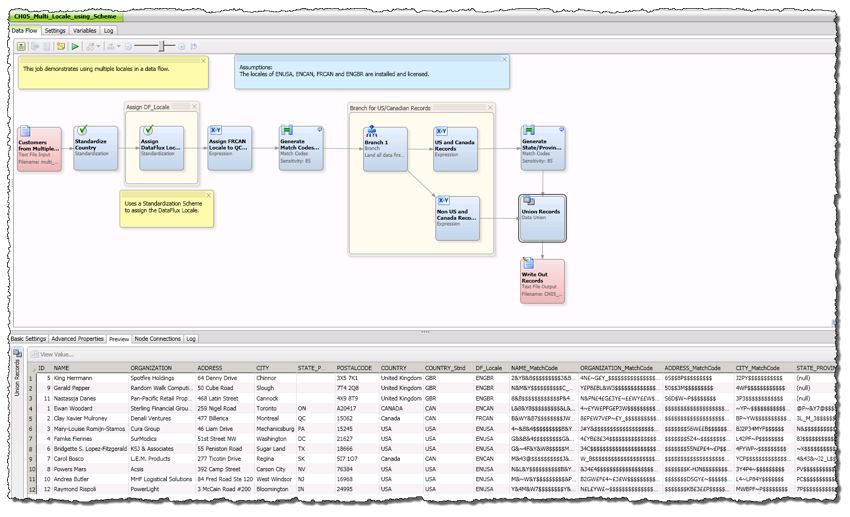
6. SAS DataFlux—key features include:
Data profiling in a cloud-based data pipeline: the need for speedTraditional data profiling, as described in this post, is a complex activity performed by data engineers prior to, and during, ingestion of data to a data warehouse. Data is meticulously analyzed and processed (with partial automation) before it is ready to enter the pipeline. Today more organizations are moving data infrastructure to the cloud, and discovering that data ingestion can happen at the click of a button. Cloud data warehouses, data management tools and ETL services come pre-integrated with hundreds of data sources. But if you can click a button and move data instantly into your target system, what about data profiling? Data profiling is more crucial than ever, with huge volumes flowing through the big data pipeline and the prevalence of unstructured data. In an cloud-based data pipeline architecture, you need an automated data warehouse that can take care of data profiling and preparation on its own. Instead of analyzing and treating the data using a data profiling tool, just pour it into the automated data warehouse, and it will automatically be cleaned, optimized and prepared for analysis. |









No description provided.
The text was updated successfully, but these errors were encountered: