- 不要死磕
- 五毒神掌(敢于放手、敢于死记硬背代码)
- 不懒于看高票答案
最佳方式:5-15分钟想不出来,直接看题解或者高票代码,用五毒神掌变成自己的东西。
最差方式:不借助外部帮助,死磕2-3小时或一晚上,导致精疲力尽,丧失信心.
- 改变自己的学习习惯(不要死磕)
- 五毒神掌(重要的是五!过遍数,而不是每次花伸长时间)
- 不要死磕AC,要看高票答案和高质量题解
最大误区:LeetCode题目只做一遍!
- Chunk it up 切碎知识点
- Deliberate Practicing 刻意练习
- Feedback 反馈
- 一维:
- 基础:数组array,链表linked list
- 高级:栈stack、队列queue、双端队列deque、集合set、映射map(hash or map)、etc
- 二维:
- 基础:树tree、图graph
- 高级:二叉搜索树binary search tree(red-black tree、AVL)、堆heap、并查集disjoint set、字典树Trie、etc
- 特殊:
- 位运算bitwise、布隆过滤器bloomFilter
- LRU Cache
- if-else,switch--->branch
- for,while loop--->iteration
- 递归Recursion(Divide & Conquer,Backtrace)
- 搜索Search:深度优先搜索 Depth first search,广度优先搜索Breadth first search,A*,etc
- 动态规划Dynamic Programming
- 二分查找Binary Search
- 贪心Greedy
- 数学Math,几何Geometry
- Clarification 沟通
- Possible solutions 所有可能的解法 比较优劣
- Coding
- Test case
- 第一遍
- 5-15分钟:读题+思考
- 直接看题解:注意多解法,比较解法优劣
- 背诵、默写好的解法
- 第二遍
- 马上自己写-->LeetCode提交
- 多种解法比较、体会-->优化
- 第三遍
- 过了一天,再重复做题
- 不同解法的熟练程度-->专项练习
- 第四遍
- 过了一周:反复回来练习相同的题目
- 第五遍
- 前一周恢复性训练
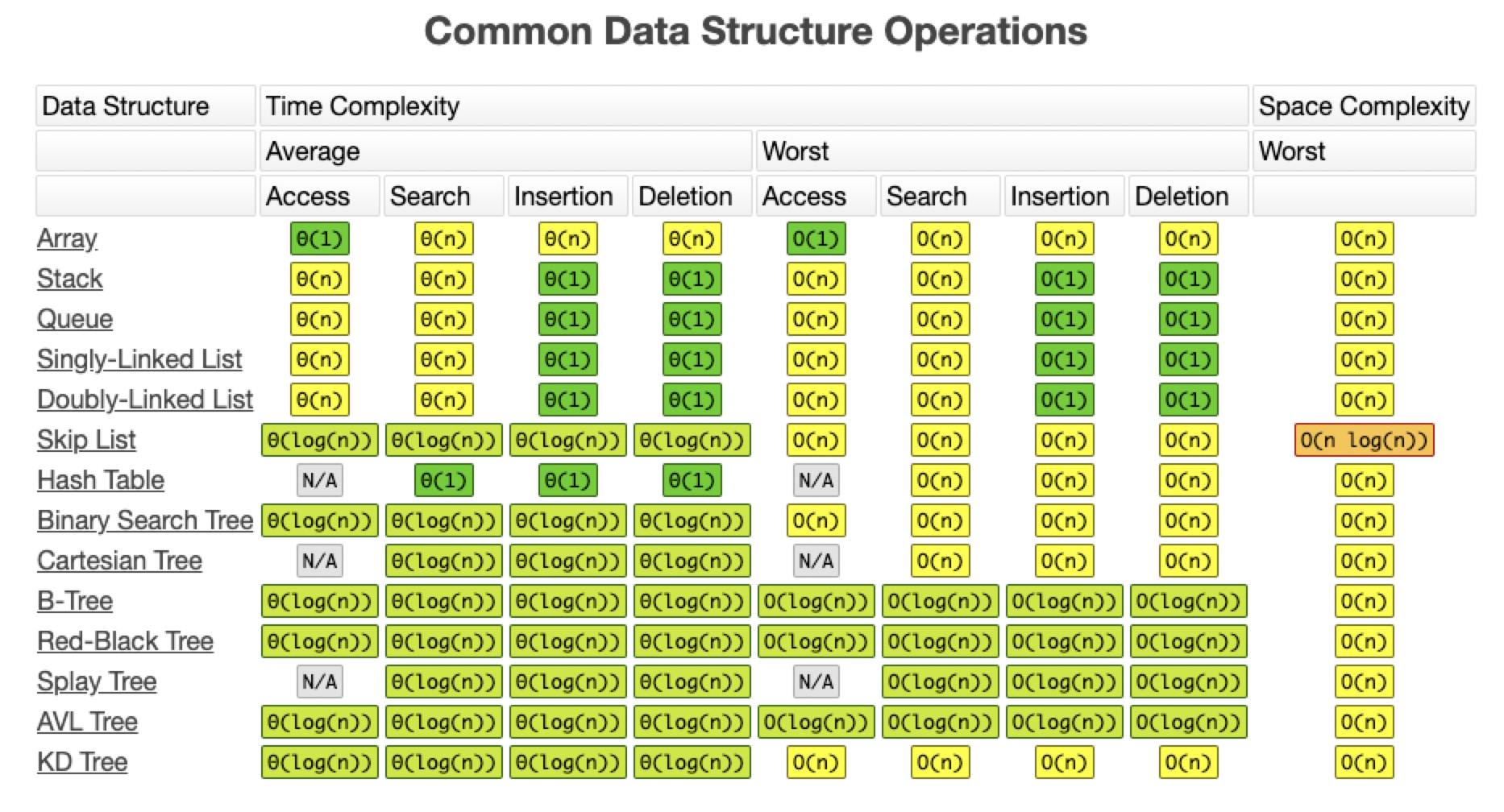
- O(1): Constant Complexity 常数复杂度
- O(log n): Logarithmic Complexity 对数复杂度
- O(n): Linear Complexity 线性复杂度
- O(n^2): N square Complexity 平方复杂度
- O(n^3): N cubic Complexity 立方复杂度
- O(2^n): Exponential Complexity 指数复杂度
- O(n^2): Factorial 阶乘复杂度
- 只能用于元素有序的情况
- 跳表对标的是平衡树(AVL)和二分查找,是一种插入/删除/搜索都是O(log n)的数据结构
- 优势:原理简单、容易实现、方便扩展、效率更高
升维思想+空间换时间
给有序链表加速
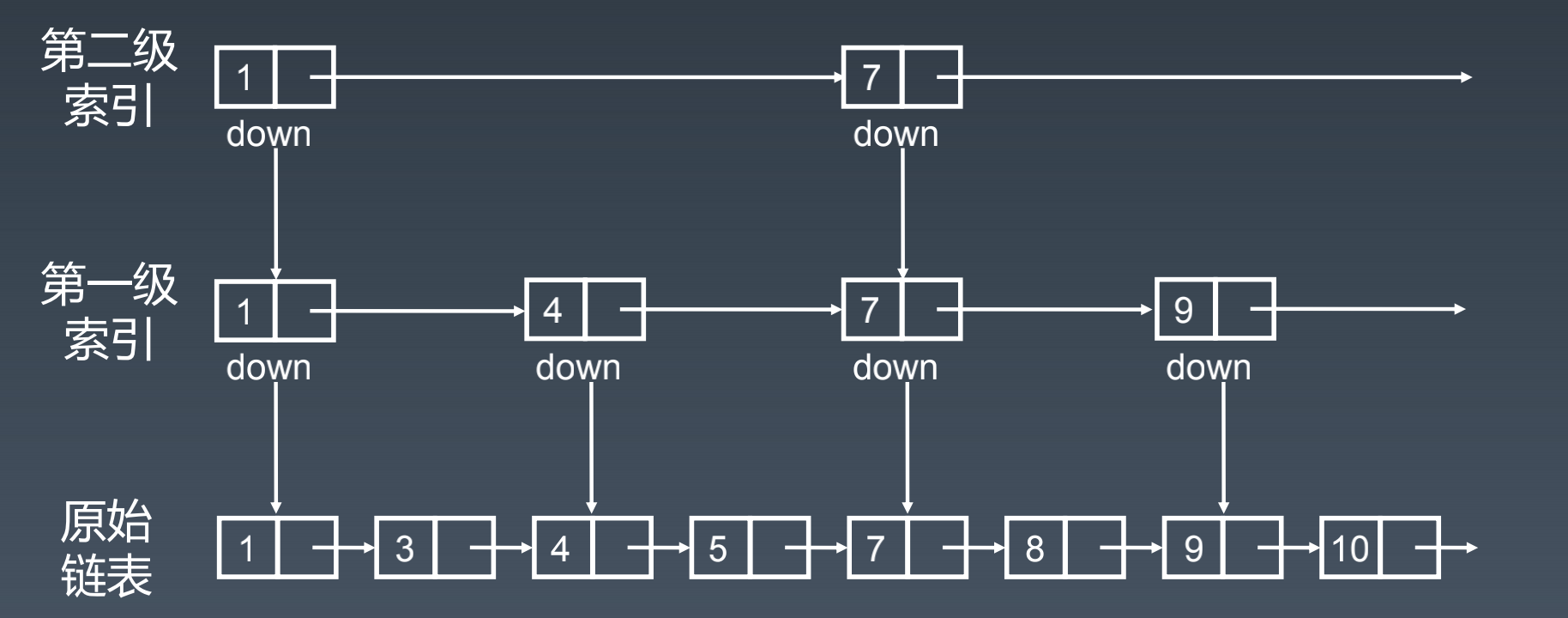 多级索引
多级索引
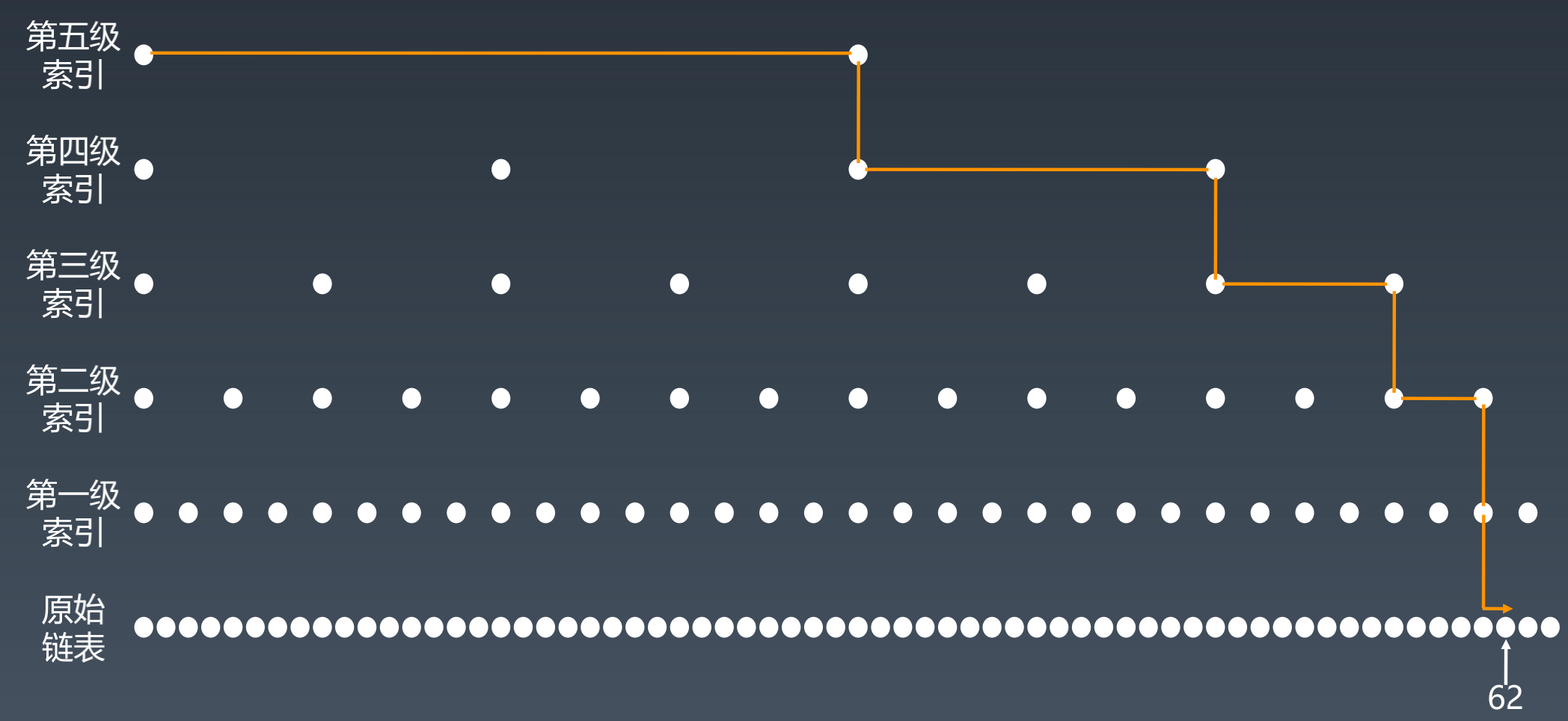 现实中跳表的形态
现实中跳表的形态
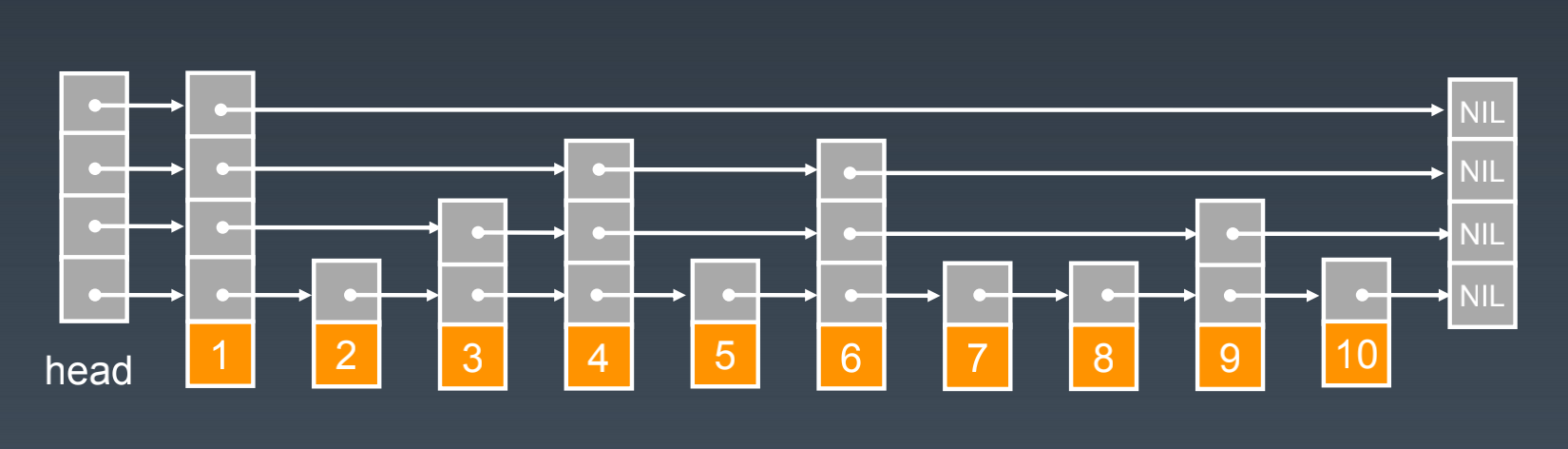
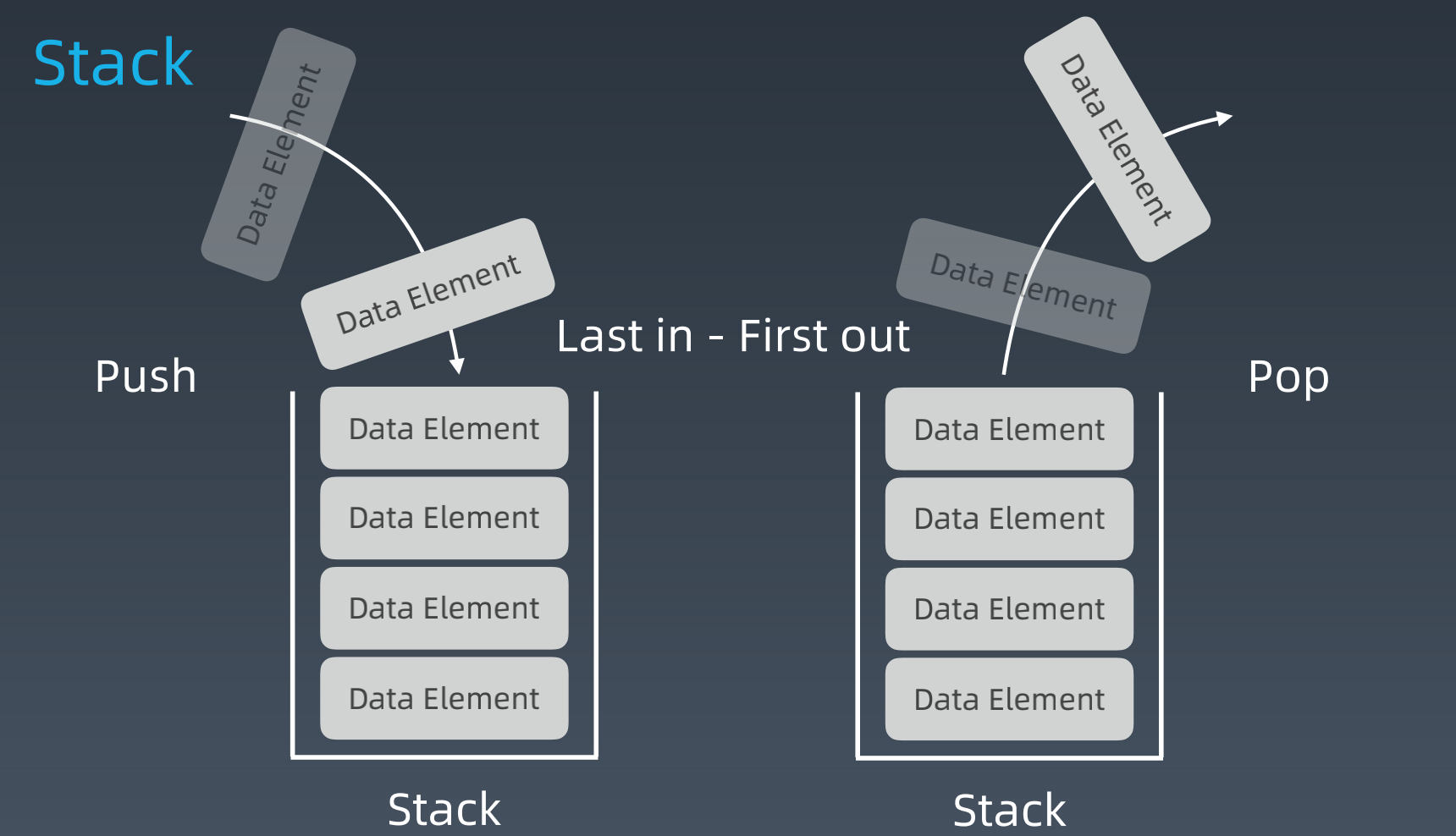
Stack:先入后出;添加、删除皆为O(1)

Queue:先入先出;添加、删除皆为O(1)
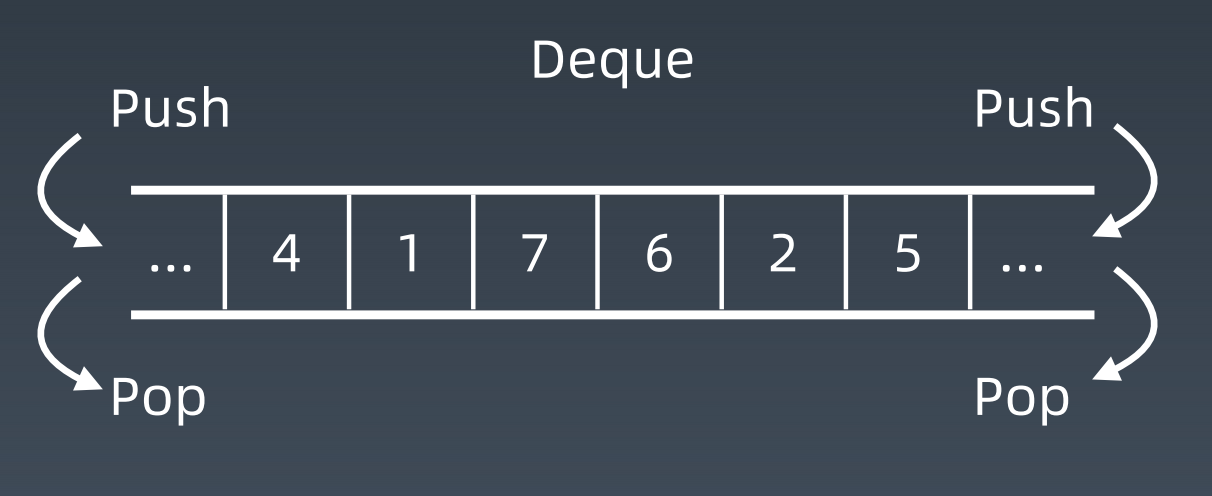
- 简单理解:双端可以进出的Queue
- 插入和删除都是O(1)操作
- 插入操作:O(1)
- 取出操作:O(logN)-按照元素的优先级取出
- 底层具体实现的数据结构较为多样和复杂:heap、bst、treap
TODO: Go heap实现代码
- 哈希表也叫散列表,是根据关键码值(Key value)而直接进行访问的数据结构;
- 通过把关键码值映射到表中的一个位置来访问记录,以加快查找的速度;
- 这个映射函数叫做散列函数。
注意:哈希冲突(拉链式)、因子、链表
Map:key-value对,key不重复 Set:不重复元素的集合
Linked List是特殊化的Tree
Tree是特殊化的Graph
-
树Tree
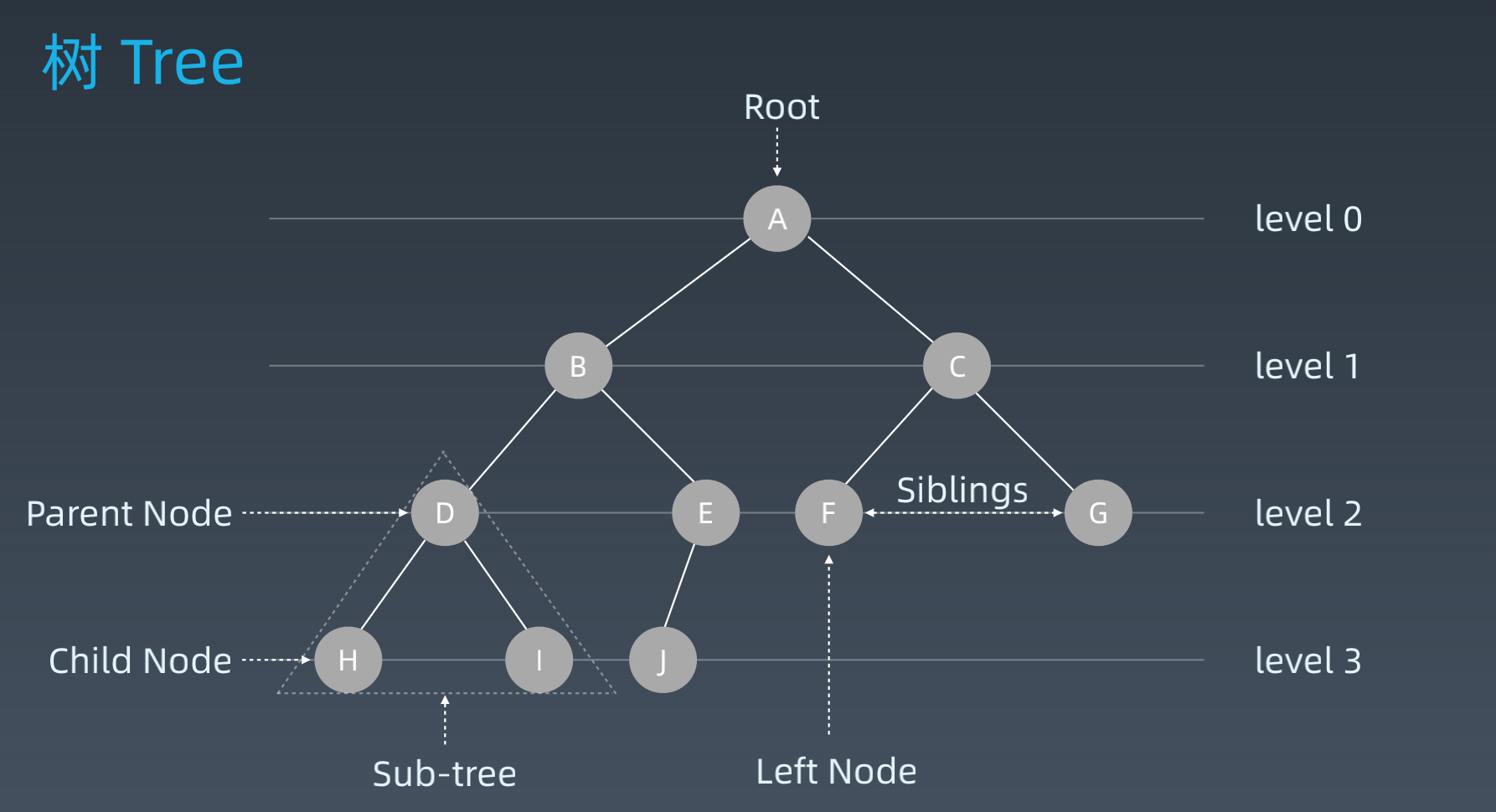
-
二叉树
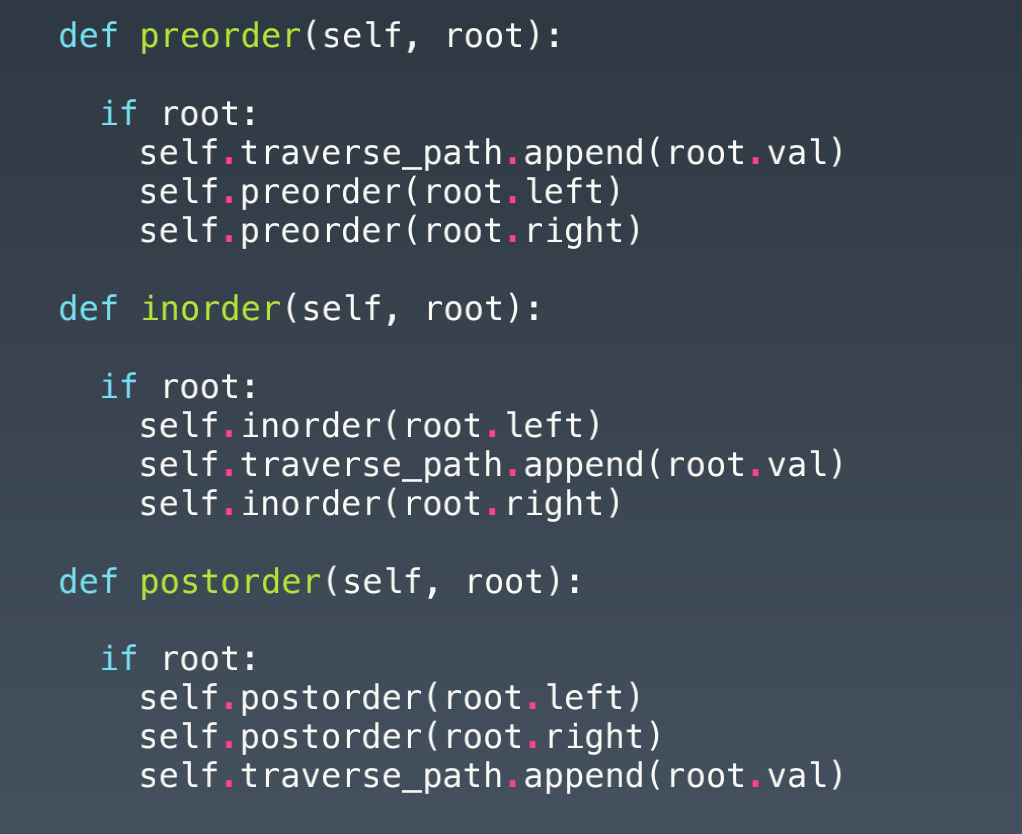
- 遍历:
- 前序(pre-order): 根-左-右
- 中序(in-order): 左-根-右
- 后序(post-order): 左-右-根
- 示例代码:
- 二叉搜索树Binary Search Tree
- 定义:二叉搜索树也称有序二叉树、排序二叉树,是指一颗空树或者具有下列性质的二叉树:
- 左子树上所有结点的值均小于它的根结点的值;
- 右子树上所有结点的值均大于它的根节点的值;
- 以此类推:左、右子树也分别为二叉查找树(重复性)。
- 字典树Trie
- 基本结构:
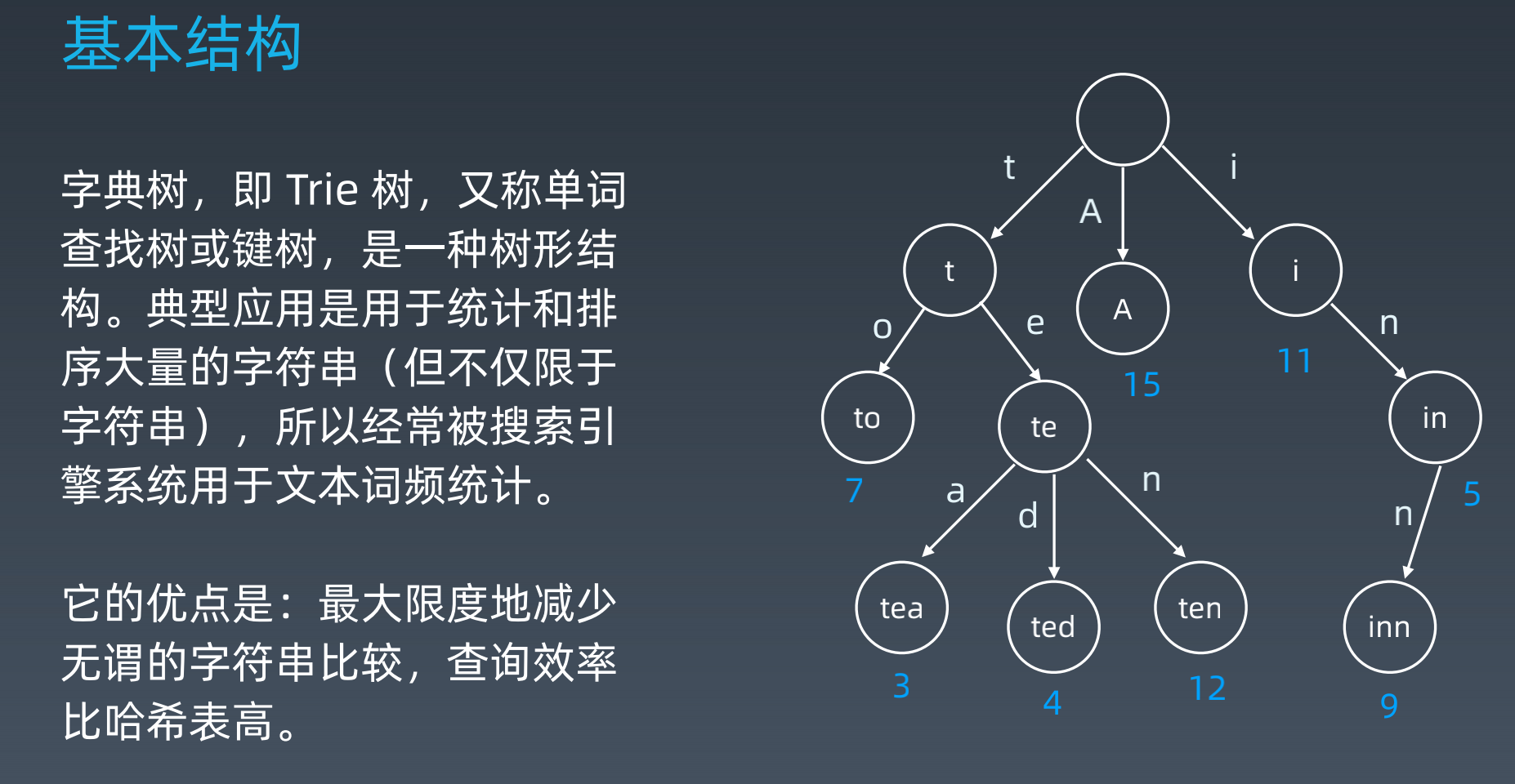
- 基本性质
- 节点本身不存完整的单词;
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点路径代表的字符都不相同。
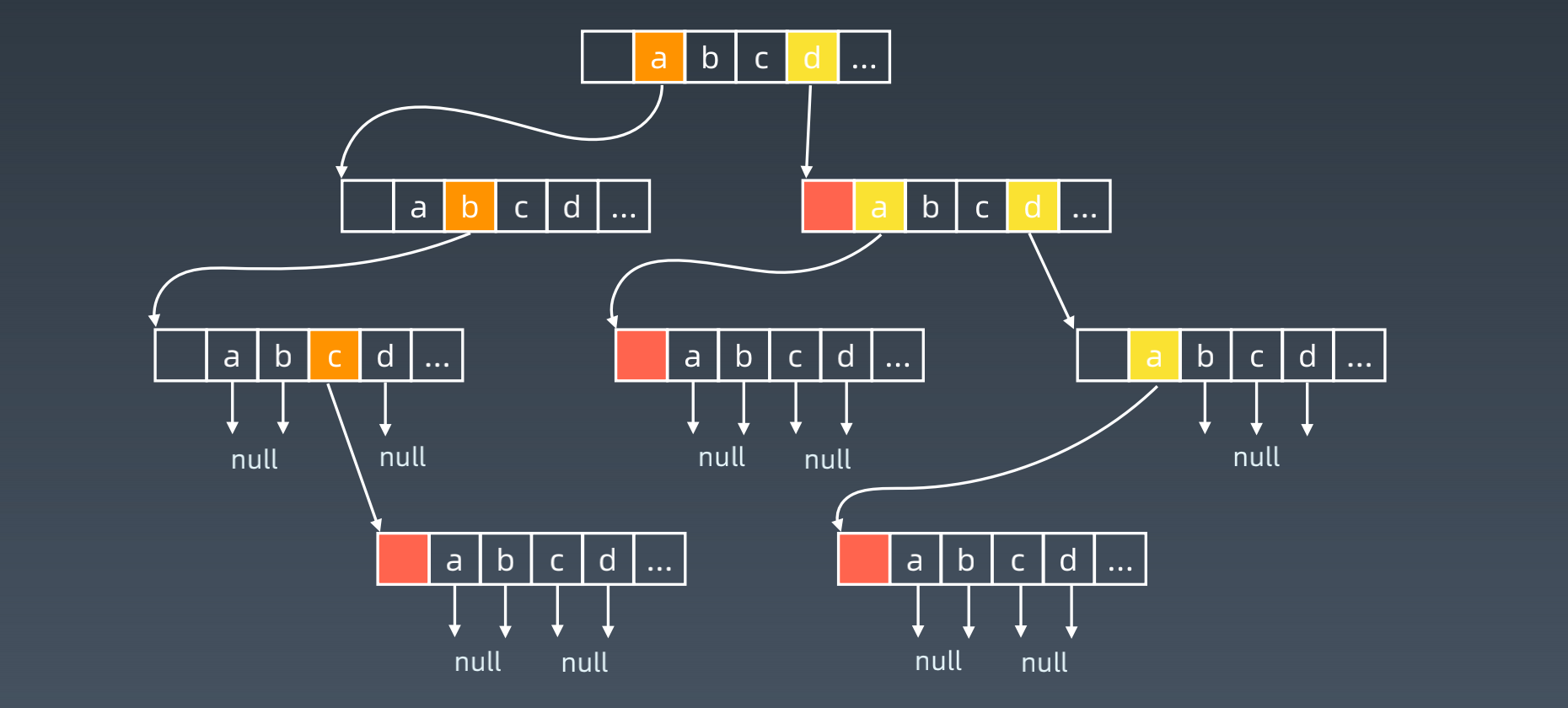
- 节点的内部实现:
- 核心思想
- 空间换时间
- 利用字符串的公共前缀来降低查询时间的开销已达到提高效率的目的。
- 代码示例:
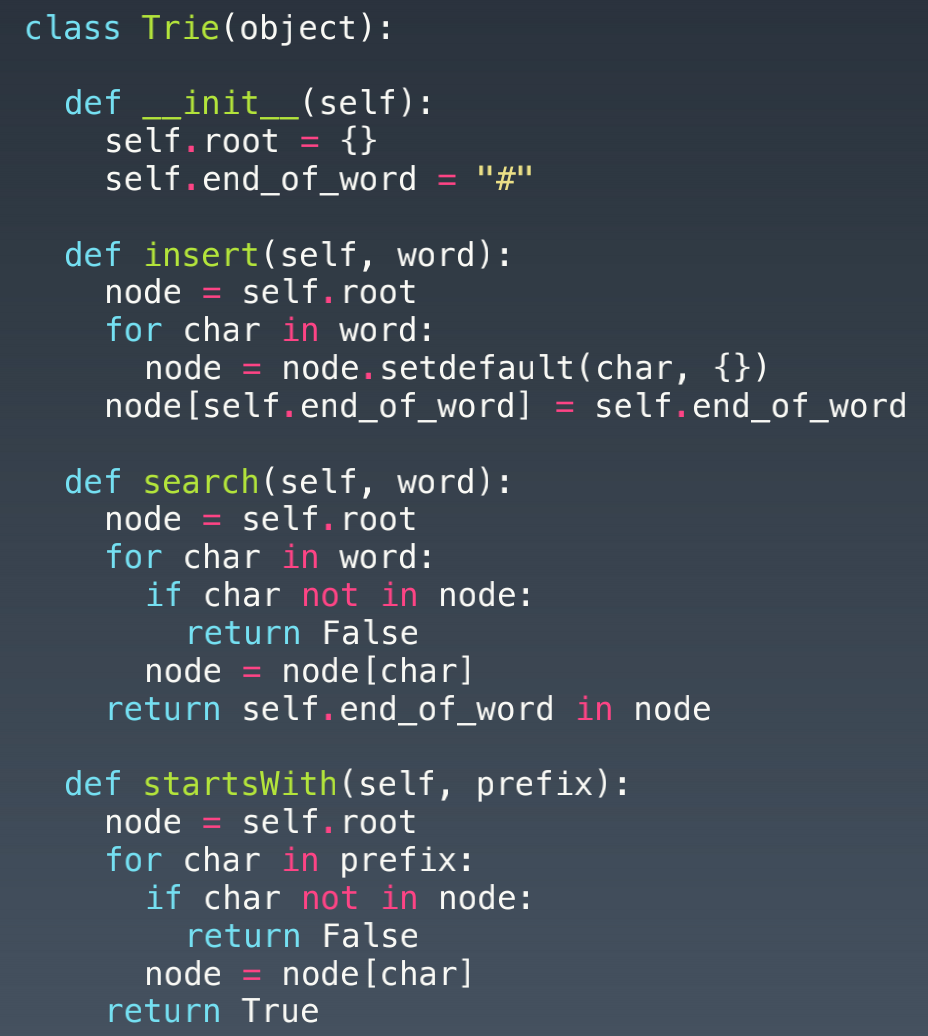
-
AVL树
- 发明者G.M.Adelson-Velsky和Evgenii Landis
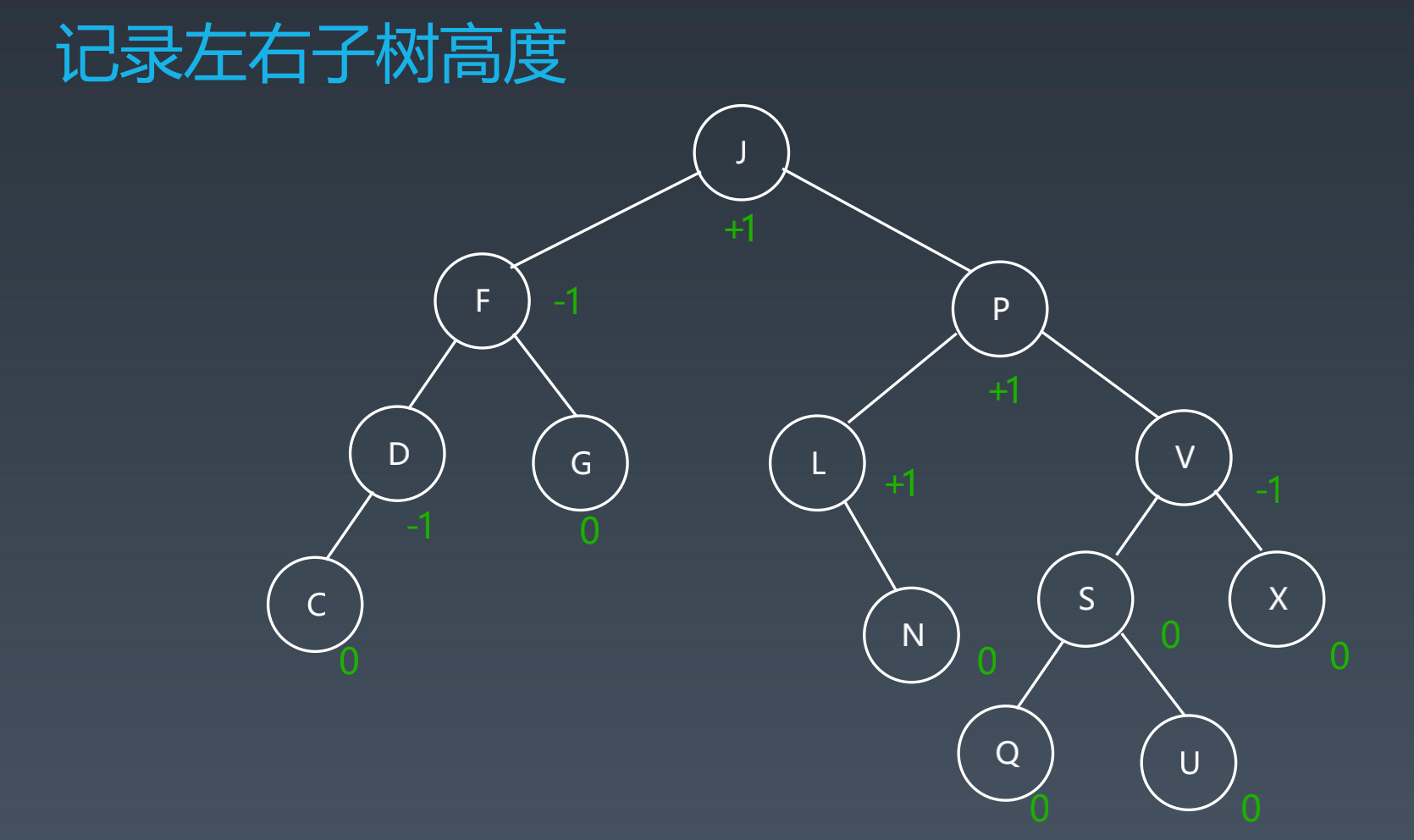
- Balance Factor(平衡因子):它的左子树高度减去它的右子树高度。balance factor = {-1, 0, 1}
- 通过旋转操作来进行平衡(四种)
- https://en.wikipedia.org/wiki/Self-balancing_binary_search_tree
参考动画:https://zhuanlan.zhihu.com/p/63272157
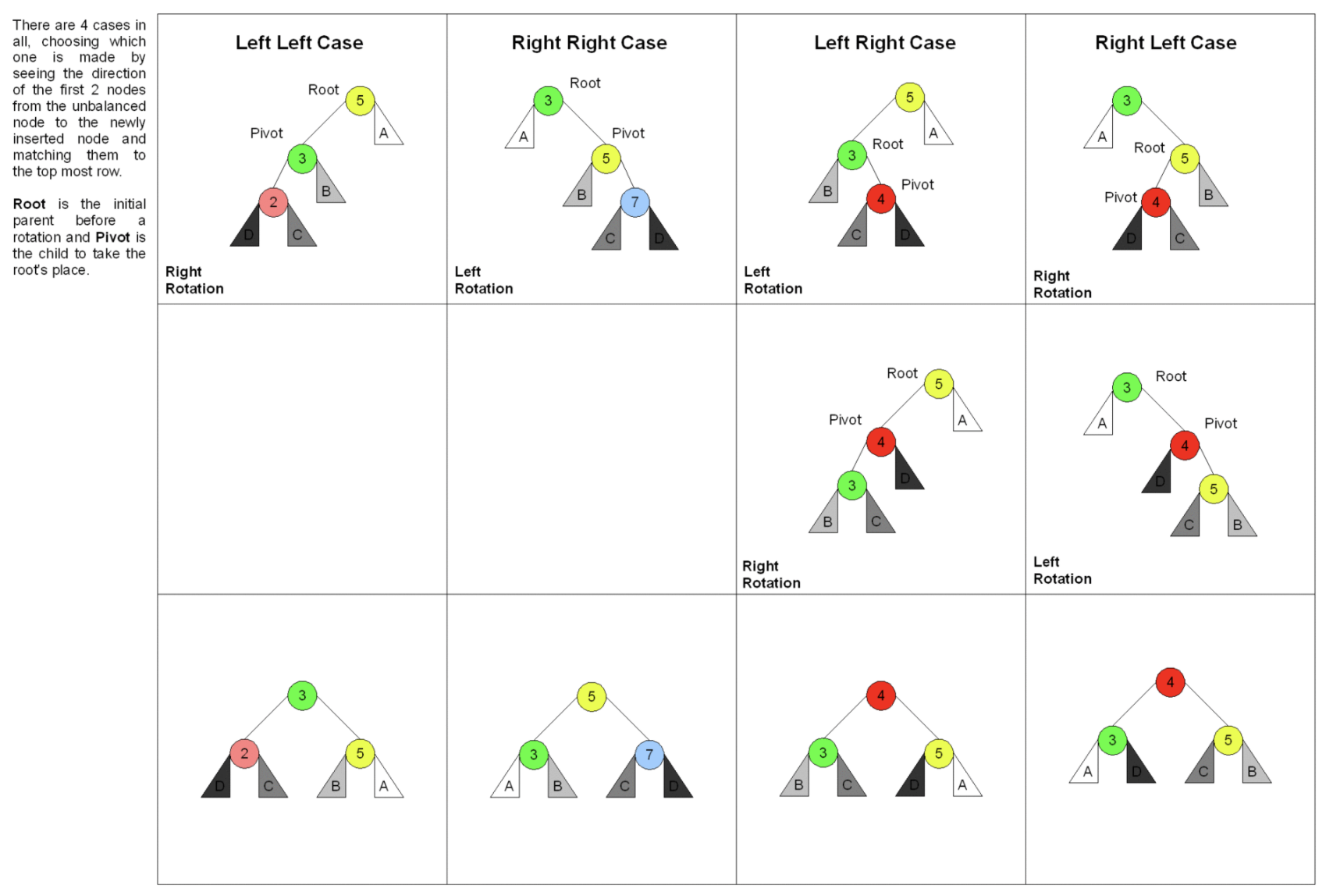
- 平衡二叉搜索树
- 每个节点存balance factor = {-1, 0, 1}
- 四种旋转操作
- 不足: 节点需要存储额外的信息、且调整次数频繁
- 场景:
- 组团、配对问题
- Group or not?
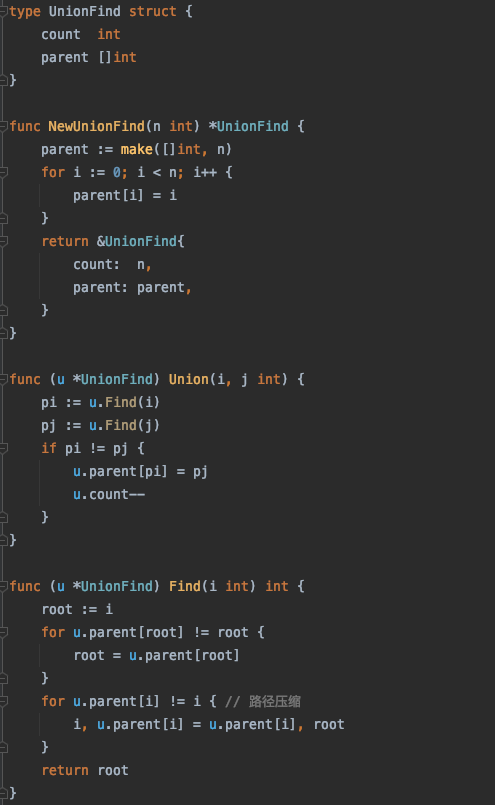
- 基本操作
- 初始化:
- 查询、合并:
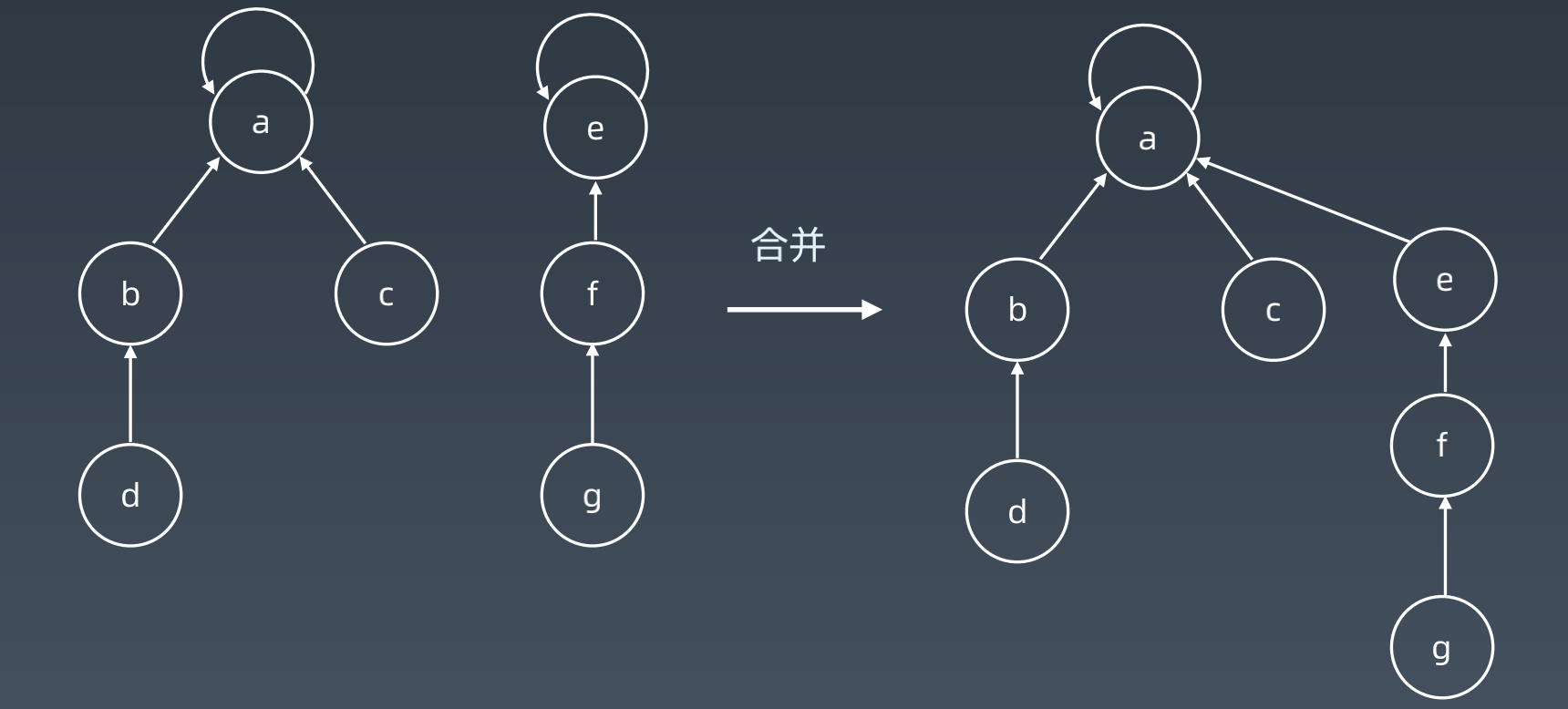
- 路径压缩:
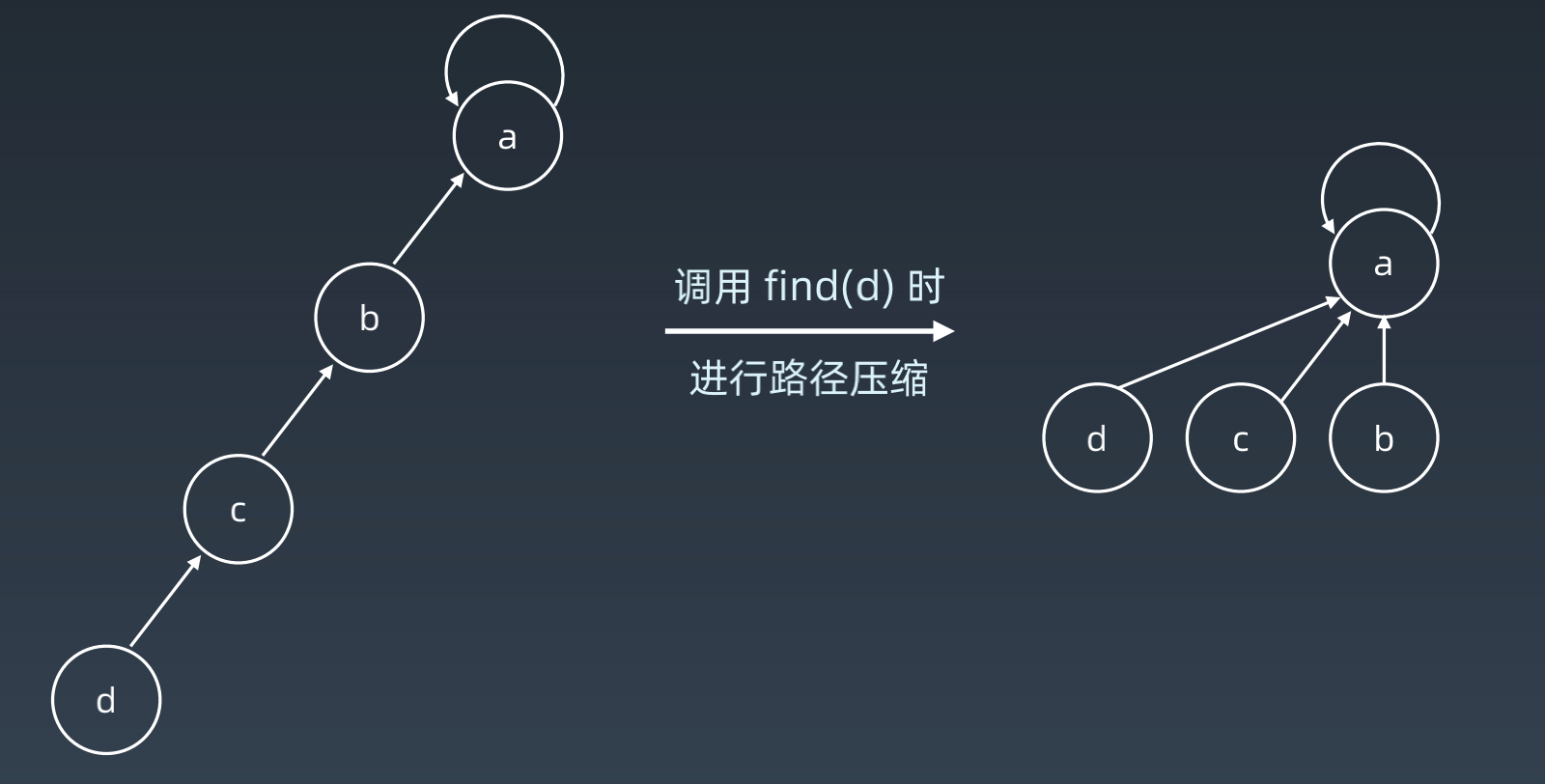
- 初始化:
- 代码示例:
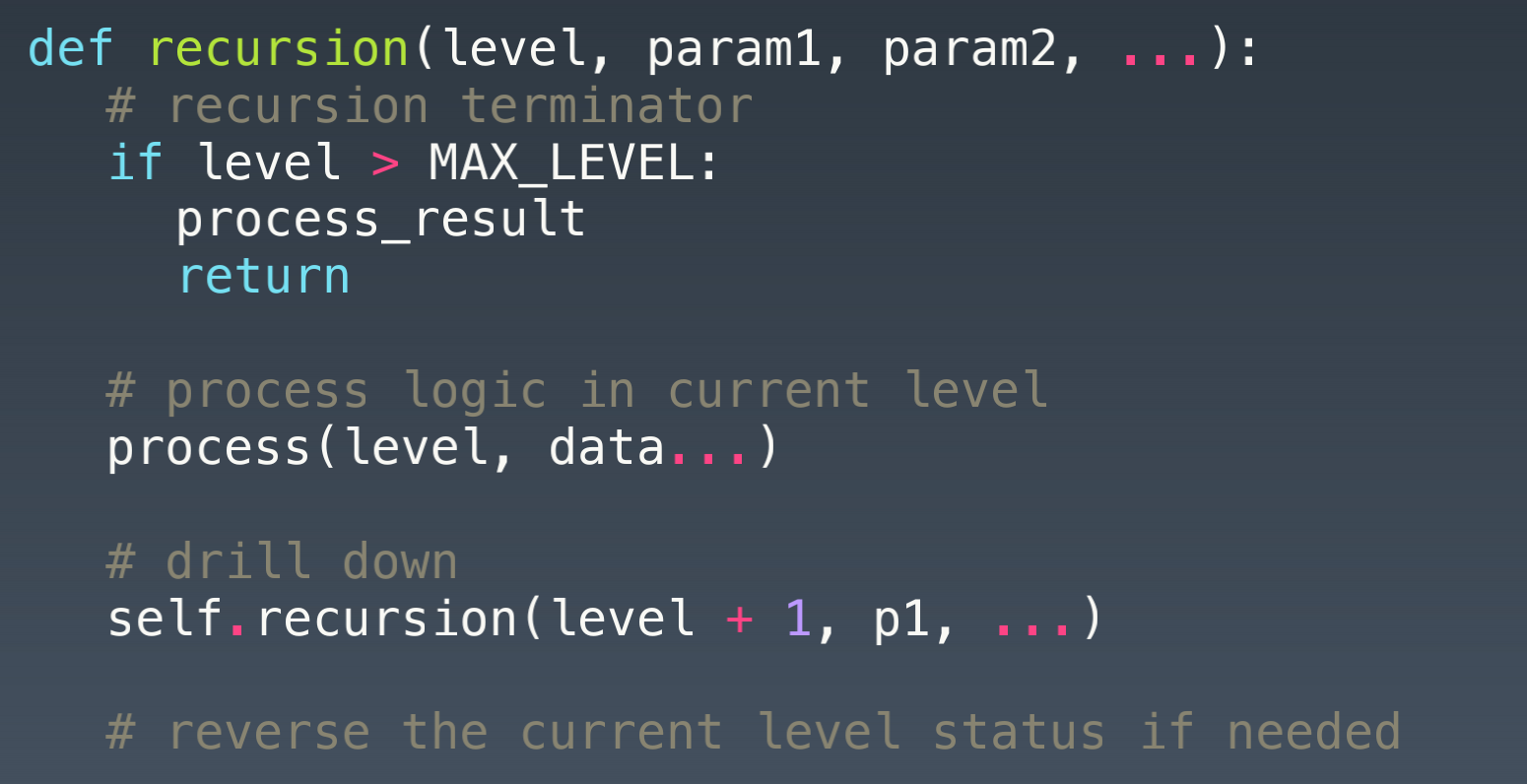
递归-循环
通过函数体来进行的循环
- 代码模板
- 思维要点
- 不要人肉进行递归(最大误区)
- 找到最近最简方法,将其拆解成可重复解决的问题(重复子问题)
- 数学归纳法思维
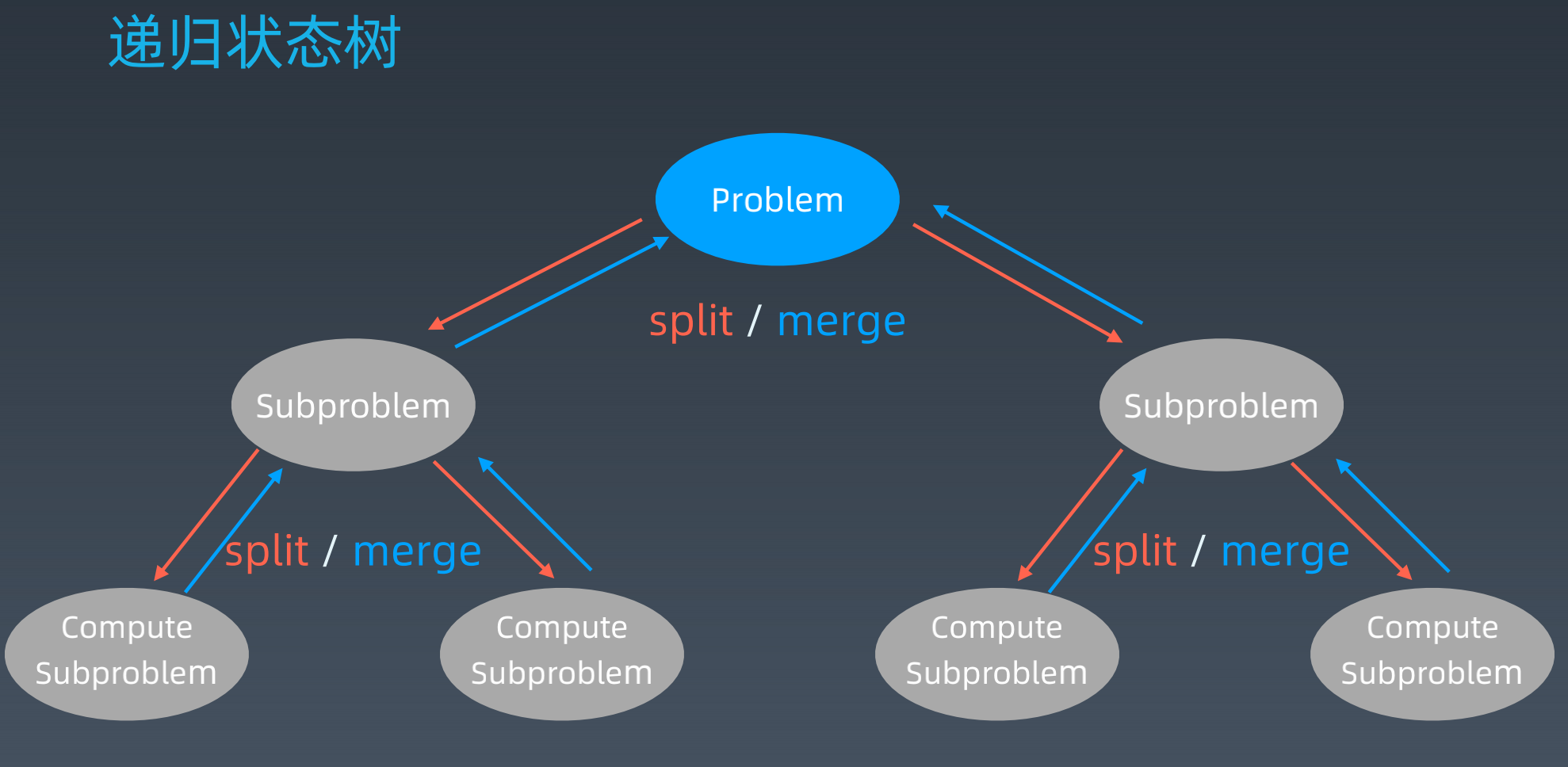
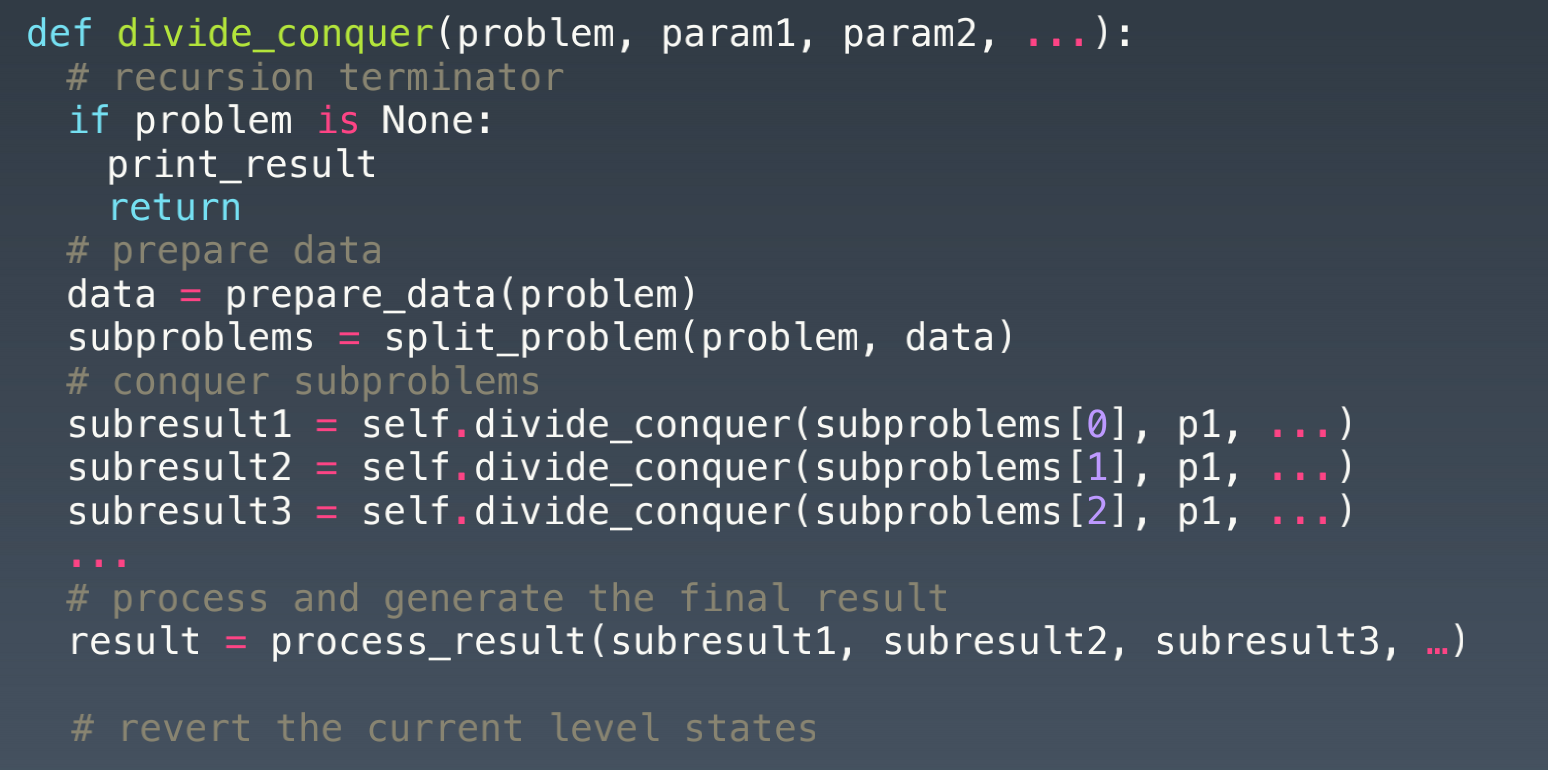
分治将大问题拆成多个子问题,最后再merge
递归状态树:
分治代码模板:
描述:回溯法采用试错的思想,它尝试分步的去解决一个问题。在分步解决的过程中,当它通过尝试发现现有的分步答案不能得到有效的正确的解答 的时候,它将取消上一步甚至是上几步的计算,再通过其它的可能的分步解答再次尝试寻找问题的答案。
在重复上述步骤后可能出现两种情况:
- 找到一个可能存在的正确的答案
- 在尝试了所有可能的分步方法后宣告该问题没有答案。
在最坏的情况下,回溯法会导致一次复杂度为指数时间的计算。
回溯模板:

- 每个节点都要访问一次
- 每个节点仅仅要访问一次
- 对于节点的访问顺序不同
- 深度优先:depth first search
- 广度优先:breadth first search
- 深度优先dfs
遍历顺序: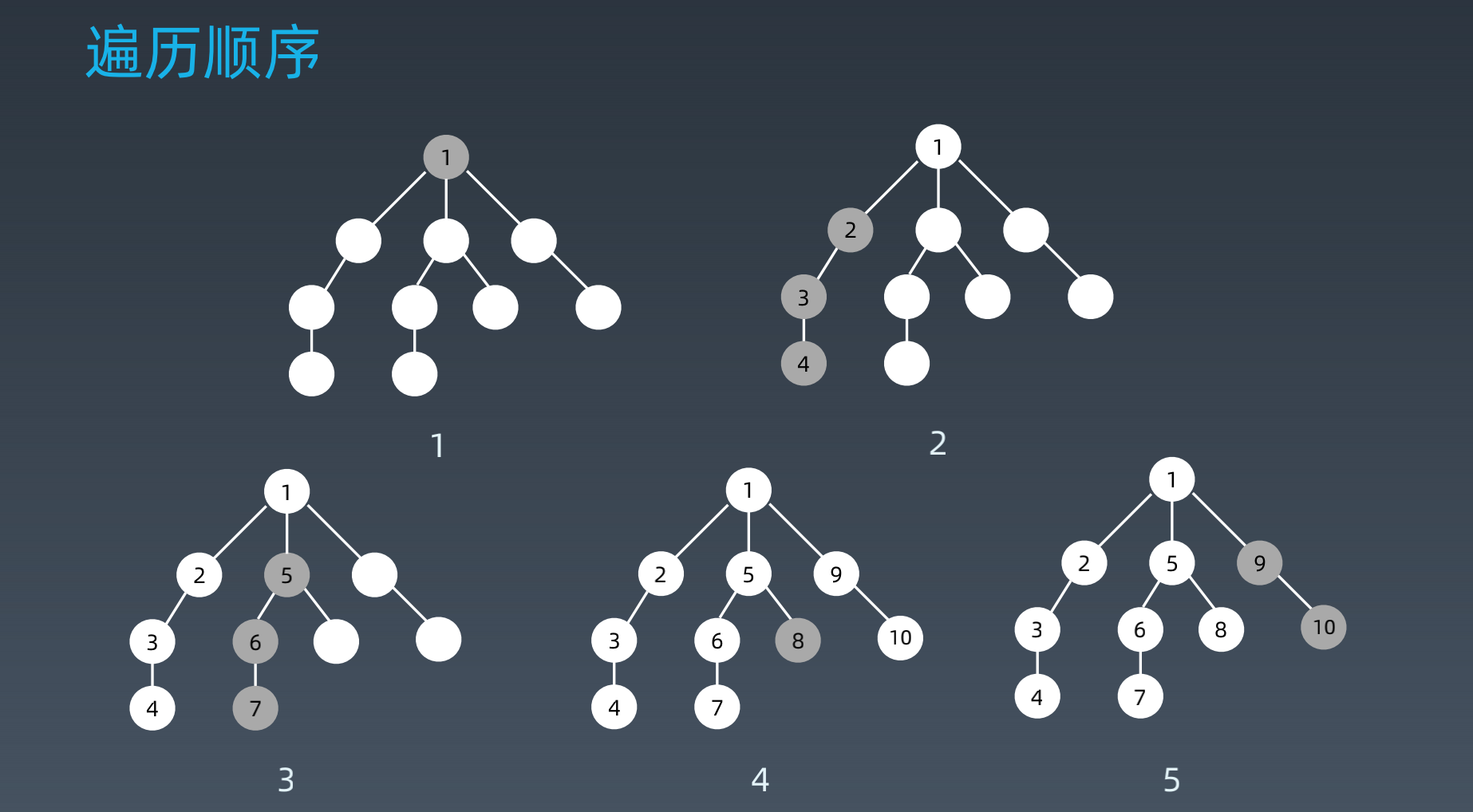
- 递归写法
- 非递归写法:使用stack
- 广度优先bfs
遍历循序: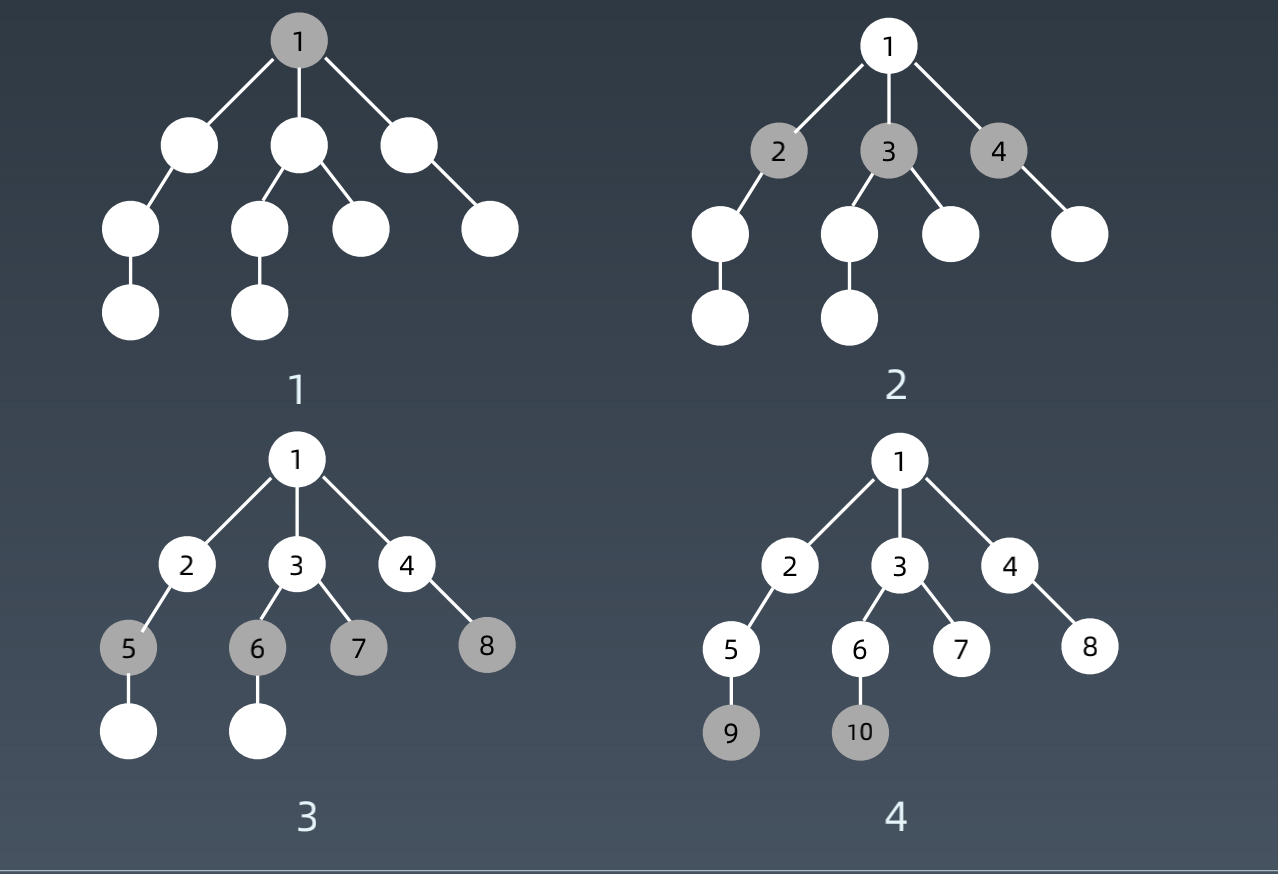
示例代码: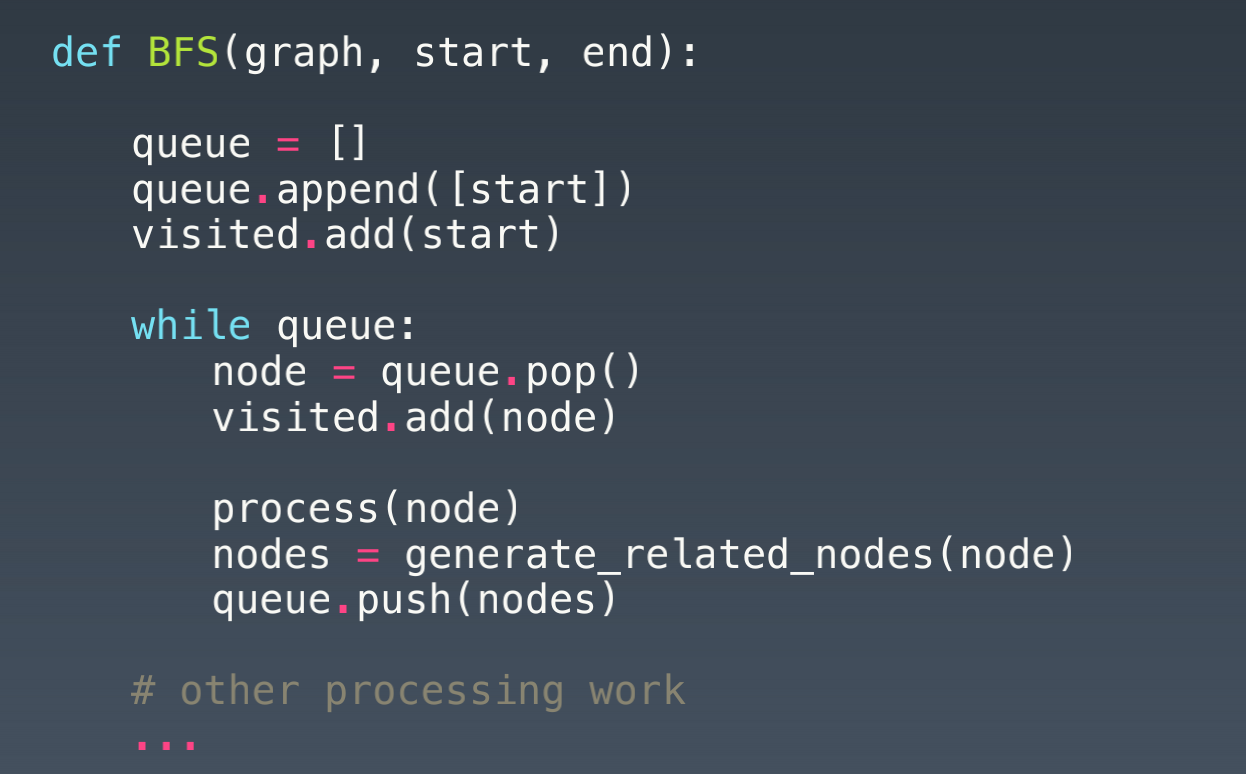
贪心算法是一种在每一步选择中都采取在当前状态下最好或最优的选择,从而希望导致结果是全局最好或最优的算法。
贪心算法与动态规划的不同在于它对每个子问题的解决方案都做出选择,不能回退。动态规划则会保存以前的运算结果, 并根据以前的结果对当前进行选择,有回退功能
注意:一旦一个问题可以通过贪心法来解决,那么贪心法一般是解决这个问题的最好办法。
场景:问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。这种子问题最优解称为最优子结构。
- 前提:
- 目标函数单调性(单调递增或者递减)
- 存在上下界(bound)
- 能够通过索引访问(index accessible)
- 代码模板:

- 描述
- Wiki:https://en.wikipedia.org/wiki/Dynamic_programming
- "Simplifying a complicated problem by breaking it down into simpler sub-problems"(in a recusive manner)
- Divide & Conquer + Optimal substructure(分治+最优子结构)
- 关键点
- 动态规划和递归或者分治没有根本上区别(关键看有无最优子结构)
- 共性:找到重复子问题
- 差异性:最优子结构、中途可以淘汰次优解
- 实战
- 最优子结构 opt[n]=best_of(opt[n-1],opt[n-2],...)
- 存储中间状态:opt[i]
- 递推公式(状态转义方程 或者 DP方程),Fib:opt[i]=opt[i-1]+opt[i-2]
- 剪枝
- 如果一个分支不满足条件,那就砍掉此分支。
- 双向BFS
- 分别从前后双向开始搜索
- 启发式搜索(A*)
- 根据估价函数不断找优先级高的分支,循环往复。
- 估价函数:h(n),它用来评价哪些结点最有希望是一个我们要找的节点,h(n)会返回一个非负实数,也可以认为是从节点n到目标节点路径的估计成本。
- 估价函数是一种告知搜索方向的方法。它提供了一种明智的方法来猜测哪个邻居节点会导向一个目标。
- 大O表示法:
- 复杂度分析: