Single-channel waveforms augmentations for speech recognition models.
- Time Stretch
- Forward Time Shift
- Pitch Shift
- Vocal Tract Length Perturbation
- Colored Noise (white, pink, brown, blue, violet, grey)
- Short Noises
- File Noise
- Zero Samples
- Clipping samples
- Inversion
- Loudness Change
- Normalization
Colab Example You can see examples of all augmentations and listen to resulting audios on this or this page with Colab notebook.
pip install speechaugs
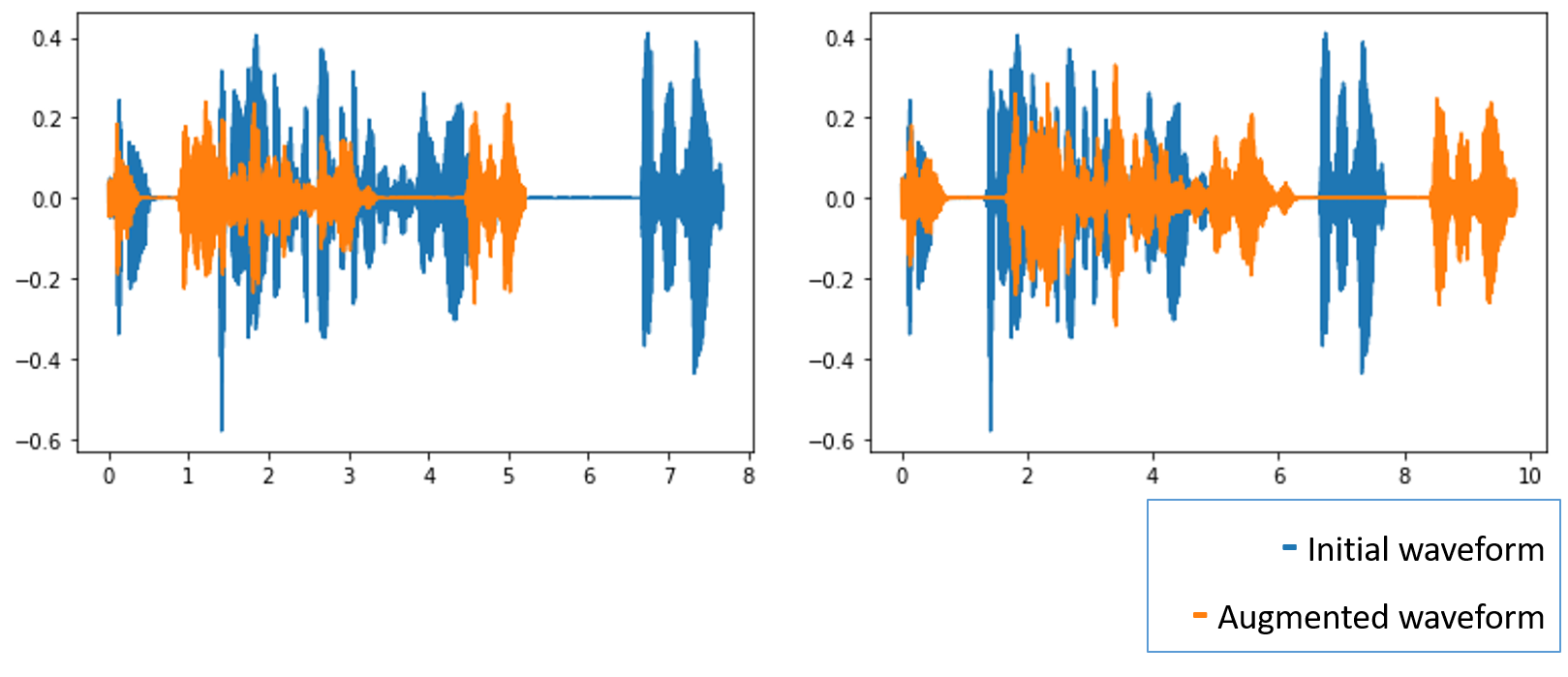
Stretch a wavefom in time with randomly chosen rate. Is implemented using librosa.effects.time_stretch.
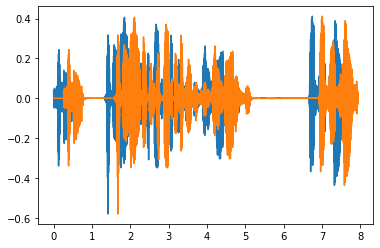
Shift a waveform forwards in time.
Shift a pitch by n_steps semitones. Is implemented using librosa.effects.pitch_shift.
The work of PitchShift can be better illustrated on the MelSpectrograms of waveforms.
Higher pitch (+9 semitones):
")
Lower pitch (-5 semitones)
")
Change vocal tract length. Effect is very similar to Pitch Shift but speech sounds more natural.
Add noise of different color to a waveform. Color of noise depends on the spectral density of the noise. You can go to wiki page for more information.
This class is implemented using colorednoise package. The color of noise is randomly choosen.
White Noise

Brown Noise

Add several short noises (of same color) to different parts of a waveform.

Add noise from randomly chosen file from specified folder. Works with "sox_io" torchaudio backend. To change backend you can run:
torchaudio.set_audio_backend('sox_io')

Set some percentage of samples to zero.
Clip some percentage of samples from a waveform.

Change sign of waveform samples.

Change loudness of intervals of a waveform. For example, in the figure below initial waveform was splitted into 3 intervals and samples from each of them were multiplied by different random factors.

Normalize a waveform with chosen method ("minmax", "max" or "meanstd")
Import:
import speechaugsOther libs:
import torch, torchaudio
import albumentations as AUsage:
ex_waveform, sr = torchaudio.load('audio_filename')
noiseroot = 'path_to_noise_folder'
transforms = A.Compose([
speechaugs.ForwardTimeShift(p=0.5),
A.OneOf([speechaugs.Inversion(p=0.5), speechaugs.LoudnessChange(p=0.5)], p=0.5),
A.OneOf([speechaugs.ZeroSamples(p=0.5), speechaugs.ClippingSamples(p=0.5)], p=0.5),
A.OneOf([speechaugs.TimeStretchLibrosa(p=0.5), speechaugs.PitchShiftLibrosa(p=0.5)], p=0.5),
A.OneOf([speechaugs.ColoredNoise(p=0.3), speechaugs.ShortNoises(p=0.3), speechaugs.FileNoise(noiseroot, p=0.3)], p=0.5),
], p=1.0)
augmented = transforms(waveform=ex_waveform)['waveform']