Create an XML5 standard #4436
Comments
|
Historically this has had no implementer interest (maybe Servo?), but we can have a tracking issue I suppose. |
What is the use case for this? |
|
The nested <div>
<p>
<p>
<p>
</div>Would result in: <div>
└ <p>
└ <p>
└ <p> |
|
That sounds like an argument against XML5, since it produces weird and un-semantic results. Whereas the OP's framing make it sound like nested p tags are a desired feature. |
|
I think the main case for XML5 is that we've had multiple good ideas for
All of these will likely continue to come up however. Another reason is that if we're going to have to maintain an XML parser forever anyway, we might as well make it do something useful. Now changing parser behavior might become a risk for the XML parser too if its usage actually becomes more widespread due to these (and other) changes. We should somewhat carefully consider how to manage that. (The other question is how likely it is that we'll end up with |
|
Everything mentioned above except "HTML5 style recovery" can be done with normal XML. The question is whether this only additional feature is worth creating syntax slightly different from XML. There were many other attempts to redefine/simplify XML similar to XML5 but none succeeded because there are simply too many existing XML parsers around, many of them not maintained anymore. So as long as this new-XML is not strict subset of XML it will not work everywhere. On the other hand I don't think there is anything that stops browsers from applying some correction steps to XML documents that are not well-formed in order to parse and display them. I can imagine that if XML document is not well-formed that browser will emit message to console and then switch to "XML5 parsing" in order to fix issues like missing end tags, quotes around attributes etc. So better then creating another markup language standard I think it would be much better to just define recovery parsing algorithm for non well-formed XML documents that browsers will invoke when parsing non well-formed XML. Also I think that such lenient parser parser should be used only for pages not for content loaded through XHR. It would be too risky to automatically correct broken XML received from some API. |
That’s kind‑of what I expect from XML5. Maybe use that HTML5 style recovery supporting algorithm from the get‑go. |
|
I’ve found this: https://ygg01.github.io/xml5_draft/ |
|
The only reason i would want an XML5 standard is that we will be able to parse web page by using an xml parser and xml tools XPath and other, because for now in HTML5 it is recommend (why ???!?!?) that void element doesn't have a auto-close tag, like <br /> is not considered valid, it should be <br> but doing so break the use of a XML parser, and now we need and HTML parser engine that support all the HTML exception. In the early 2000 year, the XHTML standard was recommended by multiple tutorial to use because of the more strict nature of the XML that encouraged to write better HTML code. https://crisp.tweakblogs.net/blog/321/html5-why-not-use-xml-syntax.html
this is non-sense for me, just put the endtag... is not difficult and it is more coherent and readable |
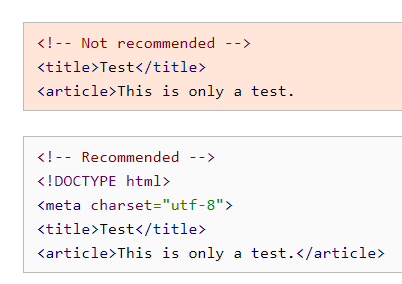

All of these is already possible in the XML syntax, which gets enabled by serving the documents with the proper Content-type HTTP header (e.g.
That's not true. Both |
As has been mentioned in WICG/webcomponents#752 (comment), XML5 would give us the features of XML with the error recovery of the HTML5 parser.
Expected features:
<script src="…"></script>, it can now be<script src="…"/>), this also future‑proofs us for whenever new void tags are added.<![CDATA[…]]>sections<p>tags (a side effect of not having hard‑coded auto-closing behaviour in the parser)This would give us the best of both worlds.
The text was updated successfully, but these errors were encountered: