List 인터페이스의 구현체는 뭐가 있을까요? Stack, Vector, ArrayList, LinkedList가 있습니다. 이 중에서도 대표적인 클래스인 ArrayList, LinkedList 차이에 대해 정리해보겠습니다.
ArrayList는 중복을 허용하고 순서를 유지하며 인덱스로 원소들을 관리한다는 점에서 배열과 상당히 유사합니다. 배열은 크기가 지정되면 고정되지만 ArrayList는 클래스이기 때문에 배열을 추가, 삭제 할 수 있는 메소드들도 존재합니다.
하지만 추가했을 때 배열이 동적으로 늘어나는 것이 아니라 용량이 꽉 찼을 경우 더 큰 용량의 배열을 만들어 옮기는 작업을 하게 됩니다.
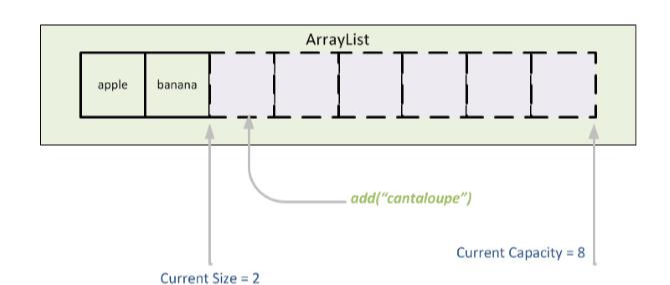
내부 코드를 보면서 ArrayList에 대해 자세히 이해해보겠습니다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData; // non-private to simplify nested class access
private int size;
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
}ArrayList는 위와 같이 3개의 생성자가 존재합니다.
아무 것도 매개변수로 받지 않는 생성자초기 용량을 매개변수로 받는 생성자Collection 타입을 매개변수로 받는 생성자
여기서 첫 번째, 두 번째 생성자에 대해서 알아보겠습니다.
List<Integer> list = new ArrayList<>();
보통 ArrayList의 객체를 만들 때 위와 같이 만들게 됩니다. 위와 같이 만들면 아래와 같은 매개변수가 존재하지 않는 생성자가 만들어집니다.
private static final int DEFAULT_CAPACITY = 10;
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
위의 생성자를 이용해서 ArrayList를 만들게 되면 DEFAULT_CAPACITY = 10으로 정의되어 있습니다. 한마디로 배열의 크기가 10으로 지정된 것과 같다고 생각하면 됩니다.
위에서 배열과 ArrayList의 차이는 동적으로 요소를 추가, 삭제할 수 있고 용량이 초과하면 더 큰 용량의 배열에다 옮기는 과정이 일어난다고 했습니다.
먼저 용량이 초과했을 때 내부 코드는 어떻게 실행이 되는지 한번 알아보겠습니다.
public class ArrayList<E> {
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
}ArrayList 안에는 배열에 값을 추가할 수 있는 add()메소드가 존재합니다. 여기에 보면 ensureCapacityInternal()이 보이는데 여기서 배열 용량을 늘리는 작업이 일어날 것 같습니다.
public class ArrayList<E> {
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}ArrayList 내부의 메소드인데 코드는 위와 같이 되어 있습니다. 복잡해 보이지만 중요한 부분은 grow() 메소드 내부에서 Arrays.copyOf(elementData, newCapacity);를 통해서 더 큰 배열에다 기존 배열의 원소들을 복사한다는 것입니다.
Arrays.copyOf()의 내부 코드를 보면 알 수 있지만 실제 A 배열을 B 배열로 옮기는 과정은 원소의 수가 얼마 안되면 괜찮겠지만 많다면 상당히 많은 시간이 소요되고 효율적이지 못합니다.
위와 같이 초기 용량을 설정하지 않으면 DEFAULT_CAPACITY = 10 입니다. 많은 원소가 추가, 삭제가 되는 상황이라면 빈번하게 배열의 복사가 일어날 것입니다. (위에서 보았듯이 10만개의 배열을 다른 배열로 복사한다고 생각하면 비효율적일 것 같습니다. 요즘엔 워낙 빨라서 괜찮다면 더 많은 개수로 예시를..)
물론 초기 용량을 미리 예상하기는 쉽지가 않지만 대략적으로 초기 용량을 생각하고, 그 예상하는 것보다 살짝 더 여유있는 값으로 초기 용량을 설정해주는 것이 좋습니다.
ArrayList의 용량이 꽉찬다면 그 다음엔 얼마나 용량을 늘려줄까요?
int newCapacity = oldCapacity + (oldCapacity >> 1);
용량을 늘리는 코드의 위와 같은 코드가 있습니다. 해석해보면 oldCapacity + oldCapacity / 2로 늘리고 있습니다. oldCapacity가 8이라면 8 + 4 = 12로 늘어나는 것입니다.
-
- 배열 마지막에 원소를 추가하는 것이기 때문에 빠르게 추가할 수 있습니다.
-
- 배열에 마지막이 아닌 처음, 중간에 데이터를 넣어야 한다면 어떻게 될까요? 0
5번 인덱스까지 들어있는 배열에 2번 인덱스에 원소를 추가한 상황이라면 25번 원소들을 뒤로 한칸씩 미뤄야 할 것입니다. 이 과정에서 시간이 많이 걸리게 됩니다.
- 배열에 마지막이 아닌 처음, 중간에 데이터를 넣어야 한다면 어떻게 될까요? 0
-
- 마지막 원소를 삭제한다면 쉽게 삭제할 수 있지만 중간이나 처음의 원소를 삭제하게 되면 빈공간을 다시 채워야 하는 과정이 필요하기 때문에 비효율적입니다.
-
- 배열은 인덱스에 해당하는 원소를 O(1)에 찾아올 수 있기 때문에 탐색에는 매우 유리합니다.
간단하게 정리하면 ArrayList는 탐색은 빠르게 할 수 있지만, 중간에서 추가, 삭제가 빈번하게 일어나면 비효율적인 특징을 가지고 있습니다.

LinkedList는 내부적으로 양방향의 연결 리스트로 구성되어 있어서 참조하려는 원소에 따라 처음부터 순방향으로 또는 역순으로 순회할 수 있습니다. (배열의 단점을 보완하기 위해서 링크드 리스트(Linked list)라는 자료구조가 고안되었습니다.)
배열의 단점은 아래와 같습니다.
-
- 크기를 변경할 수 없으므로 새로운 배열을 생성해서 복사해야 합니다.
- 실행속도를 향상시키기 위해서는 충분히 큰 용량을 미리 정해놔야 하는데 이것이 메모리 낭비가 될 수 있습니다.
-
- 차례대로 데이터를 추가하고 마지막에서부터 데이터를 삭제하는 것은 빠릅니다.
- 배열의 중간에 데이터를 추가하거나, 삭제하면 빈공간을 만들기 위해 데이터 이동이 필요하고, 빈공간을 채우기 위해 데이터 이동이 빈번할 것입니다.
LinkedList는 바로 API를 보면서 알아보겠습니다.
-
- LinkedList도 마찬가지로 add 메소드가 존재합니다. 그런데 LinkedList는 배열처럼 인덱스를 가지고 있지 않습니다. 따라서 원소를 추가하기 위해서는 Head에서 부터 마지막까지 찾아가야 하기 때문에 시간이 많이 걸립니다.
-
- 인덱스를 지정해서 추가하는 것도 마찬가지로 해당 위치로 가려면 Head 부터 탐색해서 가야하기 때문에 시간이 걸리게 됩니다.
-
- 원소를 삭제하려면 배열의 경우는 삭제하면 빈 공간을 다시 채워주는 작업이 필요하지만, LinkedList는 삭제하려는 원소 앞 or 뒤로 가서 가르키는 값을 null로 바꿔주면 됩니다.
-
- LinkedList는 ArrayList와 다르게 인덱스를 통해서 검색을 하는 것이 아니라 Head에서 부터 해당 원소 까지 검색해야 하기 때문에 O(n)에 찾을 수 있습니다.
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class ArrayListLinkedListTest {
public static void main(String[] args) {
ArrayList al = new ArrayList(2000000);
LinkedList ll = new LinkedList();
System.out.println("= 순차적으로 추가하기 =");
System.out.println("ArrayList : " + addl(al));
System.out.println("LinkedList : " + addl(ll));
System.out.println();
System.out.println("= 중간에 추가하기 =");
System.out.println("ArrayList : " + add2(al));
System.out.println("LinkedList : " + add2(ll));
System.out.println();
System.out.println("= 중간에서 삭제하기 =");
System.out.println("ArrayList : " + remove2(al));
System.out.println("LinkedList : " + remove2(ll));
System.out.println();
System.out.println("= 순차적으로 삭제하기 =");
System.out.println("ArrayList : " + remove1(al));
System.out.println("LinkedList : " + remove1(ll));
}
public static long addl(List list) {
long start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
list.add(i+"");
}
long end = System.currentTimeMillis();
return end - start;
}
public static long add2(List list) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
list.add(500, "X");
}
long end = System.currentTimeMillis();
return end - start;
}
public static long remove1(List list) {
long start = System.currentTimeMillis();
for (int i = list.size() - 1; i >= 0; i--) {
list.remove(i);
}
long end = System.currentTimeMillis();
return end - start;
}
public static long remove2(List list) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
list.remove(i);
}
long end = System.currentTimeMillis();
return end - start;
}
}= 순차적으로 추가하기 =
ArrayList : 126
LinkedList : 171
= 중간에 추가하기 =
ArrayList : 1695
LinkedList : 10
= 중간에서 삭제하기 =
ArrayList : 1303
LinkedList : 122
= 순차적으로 삭제하기 =
ArrayList : 8
LinkedList : 23
-
순차적으로 추가하기- ArrayList: 순차적으로 추가하면 배열 원소들의 이동이 없이 추가만 하면 되기 때문에 쉽게 할 수 있습니다.
- LinkedList: LinkedList는 순차적으로 추가하면 그 추가하고자 하는 곳으로 계속 탐색해서 가야 합니다. 하지만 내부적으로
양방향으로 되어 있기 때문에 ArrayList와 큰 차이가 나지는 않습니다.
-
중간에 추가하기- ArrayList: 중간에 추가하게 되면 빈 공간을 만들어야 하기 때문에 원소들의 이동이 필요하기 때문에 상당히 비효율적입니다.
- LinkedList: 중간에 추가할 때는 추가하고자 하는 원소 앞 or 노드로 가서 가리키고 있는 주소만 추가해주면 되기 때문에 금방 할 수 있습니다.
-
중간에서 삭제하기- ArrayList: 중간에서 삭제하는 것도 마찬가지로 중간에 빈 공간이 생기기 때문에 채우기 위해서 원소들의 이동이 일어나므로 시간이 오래 걸립니다.
- LinkedList: 중간에서 삭제하는 것도 추가하는 것과 마찬가지의 과정입니다.
-
순차적으로 삭제하기- ArrayList: 순차적으로 마지막 원소를 삭제할 때는 원소들의 이동이 필요 없기 때문에 시간이 오래 걸리지 않습니다.
- LinkedList: LinkedList는 내부적으로
양방향 연결리스트로 되어 있기 때문에 ArrayList와 큰 차이가 없는 것을 볼 수 있습니다.
-
- 단순히 저장하는 시간만을 비교할수록 하기 위해서 ArrayList에서 배열 재배치가 일어나는 상황은 제외하였습니다. 그렇다면 순차적으로 삭제한다는 것은 마지막 데이터부터 삭제할 경우 각 요소들의 재배치가 필요하지 않기 때문에 상당히 빠릅니다.
-
- 중간 요소를 추가 또는 삭제하는 경우, LinkedList는 각 요소간의 연결만 변경해주면 되기 때문에 처리속도가 상당히 빠릅니다. 반면에 ArrayList는 각 요소들을 재배치하여 추가할 공간을 확보하거나 빈 공간을 채워야하기 때문에 처리속도가 느립니다.
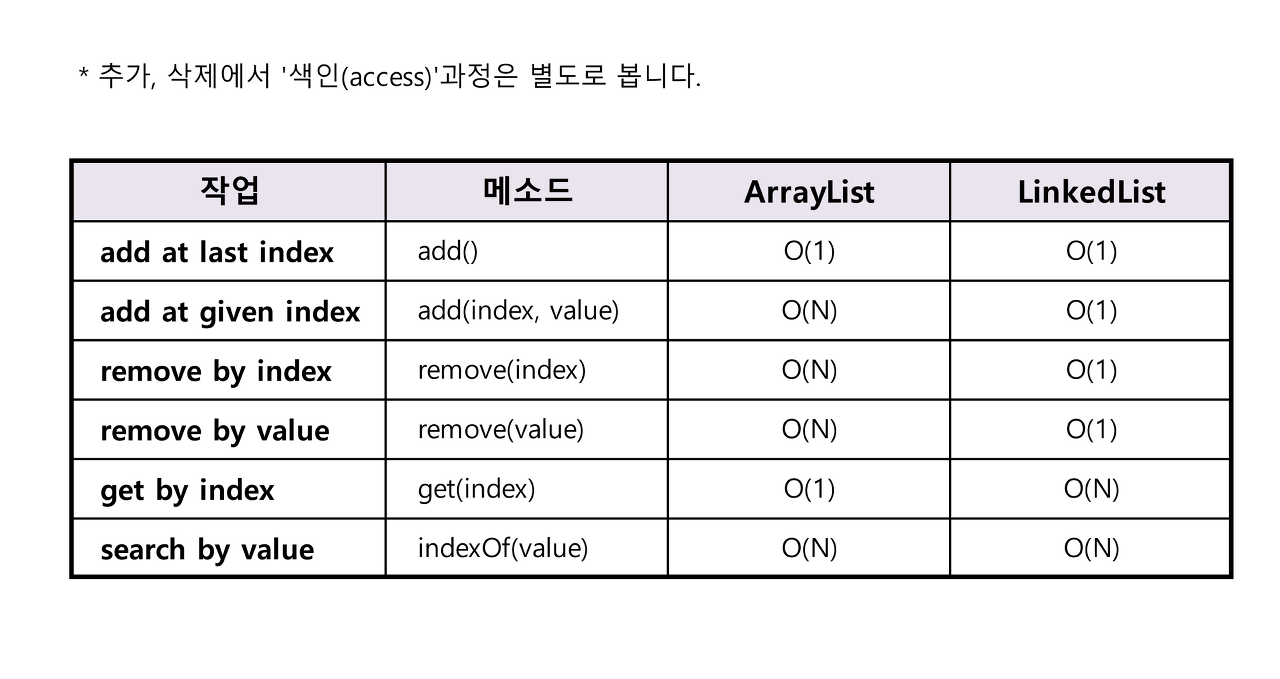
| 컬렉션 | 읽기(접근시간) | 추가/삭제 | 비 고 |
|---|---|---|---|
| ArrayList | 빠르다 | 느리다 | 순차적인 추가삭제는 더 빠름. 비효율적인 메모리 사용 |
| LinkedList | 느리다 | 빠르다 | 데이터가 많을 수록 접근성이 떨어짐 |
다르고자 하는 데이터의 개수가 변하지 않는 경우라면, ArrayList가 최상의 선택이겠지만, 데이터 개수의 변경이 잦다면 LinkedList를 사용하는 것이 더 나은 선택이 될 것입니다.
- 배열의 경우는 연속적으로 메모리상에 존재하고, 참조변수 하나당 4byte이기 때문에
시작배열 주소 + n * 데이터 타입의 크기를 통해서 원하는 인덱스에 쉽게 접근할 수 있습니다. - 하지만 LinkedList는 불연속적으로 위치한 각 요소들이 서로 연결된 것이라 처음부터 n번째 데이터까지 차례대로 따라가야만 원하는 값을 얻을 수 있습니다. 즉, LinkedList는 저장해야하는 데이터의 개수가 많아질수록 데이터를 읽어 오는 시간,
접근 시간(access time)이 길어진다는 단점이 있습니다.