不区分大小写
- null 值是一个null值
- integer 值是一个带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中
- real 浮点值,存储为 8 字节的 IEEE 浮点数字
- text 文本字符串,使用数据库编码(UTF-8、UTF-16BE 或 UTF-16LE)存储
- blob blob数据,完全根据它的输入存储
SQLiteOpenHelper第一次调用getReadableDatabase()时如果数据库不存在就会创建
CREATE TABLE COMPANY(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);drop table语句删除表定义及其所有相关数据、索引、触发器、约束和该表的权限规范
DROP TABLE COMPANY;
向数据库的某个表中添加新的数据行
#指定列
INSERT INTO TABLE_NAME [(column1, column2, column3,...columnN)]
VALUES (value1, value2, value3,...valueN);
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 );
#全部
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);获取数据,以结果表的形式返回数据
#指定列
SELECT column1, column2, columnN FROM table_name;
# 全部
SELECT * FROM table_name;
SELECT sql FROM sqlite_master WHERE type = 'table' AND tbl_name = 'COMPANY';SELECT * FROM COMPANY WHERE SALARY > 50000;
SELECT * FROM COMPANY WHERE SALARY != 20000;逻辑运算符:
- and 允许在一个 SQL 语句的 WHERE 子句中的多个条件的存在
- between 用于在给定最小值和最大值范围内的一系列值中搜索值
- exists 用于在满足一定条件的指定表中搜索行的存在
- in 用于把某个值与一系列指定列表的值进行比较
- not in IN 运算符的对立面,用于把某个值与不在一系列指定列表的值进行比较
- like 把某个值与使用通配符运算符的相似值进行比较
- glob 运算符用于把某个值与使用通配符运算符的相似值进行比较。GLOB 与 LIKE 不同之处在于,它是大小写敏感的
- not 是所用的逻辑运算符的对立面。比如 NOT EXISTS、NOT BETWEEN、NOT IN,等等。它是否定运算符。
- or 用于结合一个 SQL 语句的 WHERE 子句中的多个条件
- is null 用于把某个值与 NULL 值进行比较
- is 与 = 相似
- is not 与 != 相似
- || 连接两个不同的字符串,得到一个新的字符串
- UNIQUE 搜索指定表中的每一行,确保唯一性(无重复)
SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;SELECT COUNT(*) AS "RECORDS" FROM COMPANY;指定从一个表或多个表中获取数据的条件
UPDATE COMPANY SET ADDRESS = 'Texas' WHERE ID = 6;
# 更新所有行的ADDRESS和SALARY
UPDATE COMPANY SET ADDRESS = 'Texas', SALARY = 20000.00;#基本语法
DELETE FROM table_name WHERE [condition];
DELETE FROM COMPANY WHERE ID = 7;
#删除所有
DELETE FROM COMPANY;%:0个、1个或多个数字或字符_: 代表单一的数字或字符
SELECT column_list
FROM table_name
WHERE column LIKE 'XXXX%'
or
SELECT column_list
FROM table_name
WHERE column LIKE '%XXXX%'
or
SELECT column_list
FROM table_name
WHERE column LIKE 'XXXX_'
or
SELECT column_list
FROM table_name
WHERE column LIKE '_XXXX'
or
SELECT column_list
FROM table_name
WHERE column LIKE '_XXXX_'
#COMPANY 表中 AGE 以 2 开头的所有记录
SELECT * FROM COMPANY WHERE AGE LIKE '2%';
#COMPANY 表中 ADDRESS 文本里包含一个连字符(-)的所有记录
SELECT * FROM COMPANY WHERE ADDRESS LIKE '%-%';与like类似,但大小写敏感
*: 0个、1个或多个数字或字符?: 代表一个单一的数字或字符
SELECT * FROM COMPANY WHERE AGE GLOB '2*';限制由select语句返回的数据数量
SELECT column1, column2, columnN FROM table_name LIMIT [no of rows]
SELECT column1, column2, columnN FROM table_name LIMIT [no of rows] OFFSET [row num]
SELECT * FROM COMPANY LIMIT 6;
#从第三位开始提取 3 个记录
SELECT * FROM COMPANY LIMIT 3 OFFSET 2;
基于一个或多个列按升序或降序顺序排列数据
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
SELECT * FROM COMPANY ORDER BY SALARY ASC;
SELECT * FROM COMPANY ORDER BY NAME, SALARY ASC;
对相同的数据进行分组
#语法
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME;指定条件来过滤将出现在最终结果中的分组结果
#下面是 HAVING 子句在 SELECT 查询中的位置:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
#语法
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
# 名称计数小于 2 的所有记录
SELECT * FROM COMPANY GROUP BY name HAVING count(name) < 2;
与select语句一起使用,消除所有重复的记录,并只获取唯一一次记录
# 语法
SELECT DISTINCT column1, column2,.....columnN
FROM table_name
WHERE [condition]
# 案例
SELECT DISTINCT name FROM COMPANY;约束是在表的数据列上强制执行的规则,比如不能为null。常见约束:
- not null: 确保某列不能有null值
- default: 没有指定值时,提供默认值
- unique:确保某列中所有值是不同的
- primary key:唯一标识数据库表中的各行/记录
- check:确保某列中所有值满足一定条件
CREATE TABLE COMPANY(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL UNIQUE,
ADDRESS CHAR(50),
SALARY REAL DEFAULT 50000.00 check(SALARY>0)
);alter table 可以重命名表,或向现有表中添加一个新的列。但不能 重命名列、删除一列、添加约束、删除约束。
结合2个或多个数据库中表的记录。
- 交叉连接 cross join: 把第一个表中的每一行与第二个表中的每一行进行匹配。如果2个输入表分别有x行和y行,则结果有
x*y行。这可能会产生一个非常大的表,使用需谨慎。
SELECT EMP_ID, NAME, DEPT FROM COMPANY CROSS JOIN DEPARTMENT;- 内连接 inner join: 满足条件的记录才会出现在结果集中。
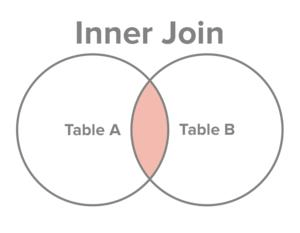
SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;- 左外连接 left outer join: 左表全部出现在结果集中,若右表无对应记录,则相应字段为null
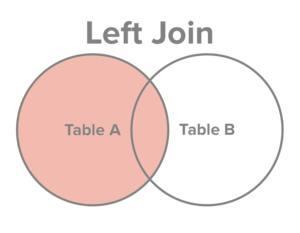
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMEN ON COMPANY.ID = DEPARTMENT.EMP_ID;union用于合并2个或多个select语句的结果,不返回任何重复的行。使用union时,每个select返回的列数必须是相同的,相同的列表达式,相同的数据类型,并确保它们相同的顺序。
SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID
UNION
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;union all用于结合2个select语句的结果,包括重复行。
SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID
UNION ALL
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;表示一个缺失值的项。
可以暂时把表或列重命名为另一个名字,这就是别名。
#表 别名的基本语法如下:
SELECT column1, column2....
FROM table_name AS alias_name
WHERE [condition];
#示例
SELECT C.ID, C.NAME, C.AGE, D.DEPT
FROM COMPANY AS C, DEPARTMENT AS D
WHERE C.ID = D.EMP_ID;
#列 别名的基本语法如下:
SELECT column_name AS alias_name
FROM table_name
WHERE [condition];
# 示例
SELECT C.ID AS COMPANY_ID, C.NAME AS COMPANY_NAME, C.AGE, D.DEPT
FROM COMPANY AS C, DEPARTMENT AS D
WHERE C.ID = D.EMP_ID;触发器是数据库的回调函数,指定的数据库事件发生时自动执行。
#语法
CREATE TRIGGER trigger_name [BEFORE|AFTER] event_name
ON table_name
BEGIN
-- 触发器逻辑....
END;
# demo 在 COMPANY 表中插入记录,这将导致在 AUDIT 表中创建一个审计日志记录。
CREATE TRIGGER audit_log AFTER INSERT
ON COMPANY
BEGIN
INSERT INTO AUDIT(EMP_ID, ENTRY_DATE) VALUES (new.ID, datetime('now'));
END;
# 列出触发器
SELECT name FROM sqlite_master WHERE type = 'trigger';
# 删除触发器
DROP TRIGGER trigger_name;- 索引是一种特殊的查找表,数据库搜索引擎用来加快数据检索。索引是指向表中数据的指针。
- 索引会加快select查询和where子句,但它会减慢使用update和insert语句时的数据输入。
- 索引可以创建和删除,不会影响数据。
- 使用create index语句创建索引,运行命名索引,可以指定表及要索引的一列或多列,并指示索引是升序排列还是降序排列。
#语法
CREATE INDEX index_name ON table_name;
# demo 在 COMPANY 表的 salary 列上创建一个索引
CREATE INDEX salary_index ON COMPANY (salary);
#删除索引
DROP INDEX salary_index;以下情况避免使用索引:
- 较小的表上
- 频繁的大批量更新或插入操作的表上
- 列中含有大量的null值
- 频繁操作的列上
执行sql语句时强制使用某个索引,虽然这个命令看起来非常有用,但现在不推荐,因为数据库的 SQL 分析引擎已经足够智能,它会自己判定用不用索引和使用哪个索引。
#语法
SELECT|DELETE|UPDATE column1, column2...
INDEXED BY (index_name)
table_name
WHERE (CONDITION);
#demo
SELECT * FROM COMPANY INDEXED BY salary_index WHERE salary > 5000;SQLite中的alter只支持下面2种:
- 重命名表
- 添加额外的列
不支持现有列的重命名,删除和修改。
#重命名表 语法
ALTER TABLE [database_name.]table_name RENAME TO new_table_name;
#demo
ALTER TABLE tbl_employee RENAME TO tbl_employee_old;
#添加一列 语法
ALTER TABLE [database_name.]table_name ADD COLUMN column_def...;
#demo
ALTER TABLE tbl_employee_old ADD COLUMN SEX char(1);truncate table用于清空表中的数据,然后将自增值重新设置为1。但SQLite中并没有truncate table。可以使用delete删除全部数据,想要恢复自增值为1,就需要先drop table删除整个表,然后再重新创建一遍。
#删除全部数据
DELETE FROM table_name;
#删表
DROP TABLE table_name;视图就是一条select语句执行后返回的结果集。原表中数据变了,这里的结果集也会变。视图是虚表。
作用:
- 方便操作,减少复杂的sql语句,增强可读性
- 更加安全,限制数据访问,用户只能看到有限的数据
- 汇总各种表中的数据,用于生成报告
视图是只读的,无法在视图上更新数据。可以在视图上创建触发器,当在表中执行delete、insert、update更新数据时可以出发视图更新操作。
# 下面是一个从 COMPANY 表创建视图的实例。视图只从 COMPANY 表中选取几列
CREATE VIEW COMPANY_VIEW AS
SELECT ID, NAME, AGE
FROM COMPANY;
# 删除视图
DROP VIEW view_name;事务是指在某个块中执行的一系列操作,要么全部执行,要么全部不执行。可以用来维护数据库的完整性,保证成批的sql语句要么全部执行,要么全部不执行。事务必须满足4个条件(ACID)。
- 原子性(Atomicity):一组事务,要么成功,要么失败回滚当作什么事都没发生
- 稳定性(Consistency):有非法数据(外键约束之类),事务撤回
- 隔离性(Isolation):事务独立运行。
- 可靠性(Durability):软、硬件崩溃后,SQLite数据表会利用日志文件重构修改
默认情况下,SQLite事务是自动提交的,即执行sql语句后立马就会执行Commit操作。
- BEGIN TRANSACTION 开始事务处理
- COMMIT 或者 END TRANSACTION 保存更改
- ROLLBACK 回滚所做的更改
BEGIN;
DELETE FROM COMPANY WHERE AGE = 25;
END TRANSACTION;子查询(内部查询或嵌套查询):where子句中嵌入另一个sql查询语句。
# 先查询出 salary 大于 50000 的职工的 id 作为条件,筛选出这些人的所有信息
SELECT * FROM tbl_employee WHERE id IN (
SELECT id FROM tbl_employee WHERE salary > 50000
);
# 上面语句 仅作举例 其实可以更简单的查询
SELECT * FROM tbl_employee WHERE id > 50000;
# 筛选出 tbl_employee 中的年龄在 tbl_age 中大于 27 岁的那些记录
SELECT * FROM tbl_employee WHERE age IN
(SELECT age FROM tbl_age WHERE age > 27 );
# 用于旧表 tbl_employee 中的数据导入到新表 tbl_employee_new 当中
INSERT INTO tbl_employee_new SELECT * FROM tbl_employee;
insert into company_bkp select * from company where id in (select id from company where salary > 4000);
UPDATE tbl_employee SET salary = salary * 1.2 WHERE age IN (SELECT age FROM tbl_age WHERE age > 27 );
DELETE FROM tbl_employee WHERE age IN (SELECT age FROM tbl_age WHERE age > 27 );设置字段值自动递增,只能用于整型(integer),默认从1开始。
CREATE TABLE tbl_employee (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
name CHAR(64) NOT NULL,
age INTEGER NOT NULL,
city CHAR(64),
salary REAL
);用户输入的数据直接插入表中,可能有安全问题,可能会被sql注入,然后引发数据丢失之类的问题。
防止sql注入:
- 必须校验用户的输入,可以通过正则表达式、限制长度、单引号和双“-”进行转换等
- 不要使用动态拼装sql,可以使用sql预处理语句
- 机密信息加密之后再存放,或者hash掉密码和敏感的信息
- 尽量不使用管理员权限的数据库连接,使用那种权限有限的数据库连接
- 应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装
- sql注入的检测方法一般采用辅助软件或网站平台来检测
| 函数 | 描述 |
|---|---|
| count() | 计算一个数据库表中的行数 |
| max() | 选择某列的最大值 |
| min() | 选择某列的最小值 |
| avg() | 计算某列的平均值 |
| sum() | 为一个数值列求和 |
| random() | 返回一个介于 -9223372036854775808 和 +9223372036854775807 之间的伪随机整数 |
| abs() | 返回数值参数的绝对值 |
| upper() | 把字符串转换为大写字母 |
| lower() | 把字符串转换为小写字母 |
| length() | 返回字符串的长度 |
| sqlite_version() | 返回sqlite库的版本 |