✏️ ⛳️👍 ✔️
KNN定义
✔️ K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一, 通俗理解它,就是近朱者赤,近墨者黑。
KNN原理
✔️ 为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
形象理解
如下图所示,是一个二分类问题,现在需要确认红星的类别。
- k=3, 存在两个蓝色,一个绿色,则红星属于蓝色类别;
- k=5, 存在三个绿色,2个蓝色,则红星属于绿色类别;
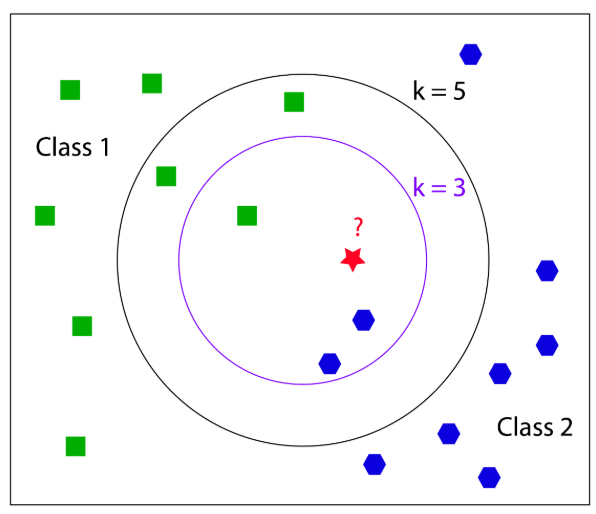
k 的取值很关键,K值选的太大易引起欠拟合,太小容易过拟合,需交叉验证确定K值。
算法的描述
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
优点
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2.适合对稀有事件进行分类;
3.特别适合于多分类问题, kNN比SVM的表现要好。
缺点
1> 当训练数据集很大时,需要大量的存储空间,而且需要计算待测样本和训练数据集中所有样本的距离,所以非常耗时;
2> KNN对于样本不均衡,以及随机分布的数据效果不好。
1)创建 cv2.ml.KNearest_create();
2)训练 knn.train(train, cv.ml.ROW_SAMPLE, train_labels);
3)预测 ret,result,neighbours,dist = nn.findNearest(sample,k=5)
- sample 是待预测的数据样本;
- k 表示选择最近邻的数目;
- result 表示预测结果;
- neighbours 表示每个样本的前k个邻居;
- dist表示每个样本前k的邻居的距离;
Opencv官方Sample中有一张包含5000个手写数据集的图片,我们使用这张图结合KNN,实现手写数字的识别:

{kind=link}
代码
import numpy as np
import cv2 as cv
# 读取数据
img = cv.imread('digits.png')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
cells = [np.hsplit(row,100) for row in np.vsplit(gray,50)]
x = np.array(cells)
# 创建训练与测试数据
train = x[:,:50].reshape(-1,400).astype(np.float32) # Size = (2500,400)
test = x[:,50:100].reshape(-1,400).astype(np.float32) # Size = (2500,400)
k = np.arange(10)
train_labels = np.repeat(k,250)[:,np.newaxis]
test_labels = train_labels.copy()
# 初始化KNN,并训练
knn = cv.ml.KNearest_create()
knn.train(train, cv.ml.ROW_SAMPLE, train_labels)
ret,result,neighbours,dist = knn.findNearest(test,k=5)
# 计算准确率
matches = result==test_labels
correct = np.count_nonzero(matches)
accuracy = correct*100.0/result.size
print('acc = ', accuracy)输出
acc = 91.76
进一步提高准确率的方法是增加训练数据,特别是错误的数据.每次训练时最好是保存训练数据,以便下次使用。
# 保存训练数据
np.savez('knn_data.npz',train=train, train_labels=train_labels)
# 加载训练数据
with np.load('knn_data.npz') as data:
print( data.files )
train = data['train']
train_labels = data['train_labels']