Neighborhood Graph and Tree for Indexing High-dimensional Data
Home / Installation / Command / License / Publications / About Us / 日本語
NGT provides commands and a library for performing high-speed approximate nearest neighbor searches against a large volume of data in high dimensional vector data space (several ten to several thousand dimensions).
- 04/10/2024 Inner product (or dot product) is now available. (v2.1.0)
- 08/10/2022 QBG (Quantized Blob Graph) and QG (renewed NGTQG) are now available. The command-line interface ngtq and ngtqg are now obsolete by replacing qbg. (v2.0.0)
- 02/04/2022 FP16 (half-precision floating point) is now available. (v1.14.0)
- 03/12/2021 The results for the quantized graph are added to this README.
- 01/15/2021 NGT v1.13.0 to provide the quantized graph (NGTQG) is released.
- 11/04/2019 NGT tutorial has been released.
- 06/26/2019 Jaccard distance is available. (v1.7.6)
- 06/10/2019 PyPI NGT package v1.7.5 is now available.
- 01/17/2019 Python NGT can be installed via pip from PyPI. (v1.5.1)
- 12/14/2018 NGTQ (NGT with Quantization) is now available. (v1.5.0)
- 08/08/2018 ONNG is now available. (v1.4.0)
This repository provides the following methods.
- NGT: Graph and tree-based method
- QG: Quantized graph-based method
- QBG: Quantized blob graph-based method
Note: Since QG and QBG require BLAS and LAPACK libraries, if you use only NGT (Graph and tree-based method) without the additional libraries like V1, you can disable QB and QBG with this option.
$ unzip NGT-x.x.x.zip
$ cd NGT-x.x.x
$ mkdir build
$ cd build
$ cmake -DNGT_QBG_DISABLED=ON ..
$ make
$ make install
$ ldconfig /usr/local/lib
$ yum install blas-devel lapack-devel
$ unzip NGT-x.x.x.zip
$ cd NGT-x.x.x
$ mkdir build
$ cd build
$ cmake ..
$ make
$ make install
$ ldconfig /usr/local/lib
$ apt install libblas-dev liblapack-dev
$ unzip NGT-x.x.x.zip
$ cd NGT-x.x.x
$ mkdir build
$ cd build
$ cmake ..
$ make
$ make install
$ ldconfig /usr/local/lib
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
$ brew install cmake
$ brew install libomp
$ unzip NGT-x.x.x.zip
$ cd NGT-x.x.x
$ mkdir build
$ cd build
$ cmake ..
$ make
$ make install
$ brew install ngt
- Supported operating systems: Linux and macOS
- Object additional registration and removal are available.
- Objects beyond the memory size can be handled using the shared memory (memory mapped file) option.
- Supported distance functions: L1, L2, Cosine similarity, Angular, Hamming, Jaccard, Poincare, and Lorentz
- Data Types: 4 byte floating point number and 1 byte unsigned integer
- Supported languages: Python, Ruby, PHP, Rust, Go, C, and C++
- Distributed servers: ngtd and vald
- Python
- Ruby (Thanks Andrew!)
- PHP (Thanks Andrew!)
- Rust (Thanks Romain!)
- JavaScript/NodeJS : ngt-tool and spatial-db-ngt (Thanks stonkpunk!)
- Go
- C
- C++(sample code)
The following build parameters are available
The index can be placed in shared memory with memory mapped files. Using shared memory can reduce the amount of memory needed when multiple processes are using the same index. In addition, it can not only handle an index with a large number of objects that cannot be loaded into memory, but also reduce time to open it. Since changes become necessary at build time, please add the following parameter when executing "cmake" in order to use shared memory.
$ cmake -DNGT_SHARED_MEMORY_ALLOCATOR=ON ..
Note: Since there is no lock function, the index should be used only for reference when multiple processes are using the same index.
When you insert more than about 5 million objects for the graph-based method, please add the following parameter to improve the search time.
$ cmake -DNGT_LARGE_DATASET=ON ..
QG and QBG require BLAS and LAPACK libraries. If you would not like to install these libraries and do not use QG and QBG, you can disable QG and QBG.
$ cmake -DNGT_QBG_DISABLED=ON ..
- Higher performance than the graph and tree-based method
- Supported operating systems: Linux and macOS
- Supported distance functions: L2 and Cosine similarity
- Command : qbg
- C++
- C
- Python only for search
For QG, it is recommended to disable rotation of the vector space and residual vectors to improve performance as follows.
$ cmake -DNGTQG_NO_ROTATION=ON -DNGTQG_ZERO_GLOBAL=ON ..
- QBG can handle billions of objects.
- Supported operating systems: Linux and macOS
- Supported distance functions: L2
- Command : qbg
- C++
- C
- Python only for search
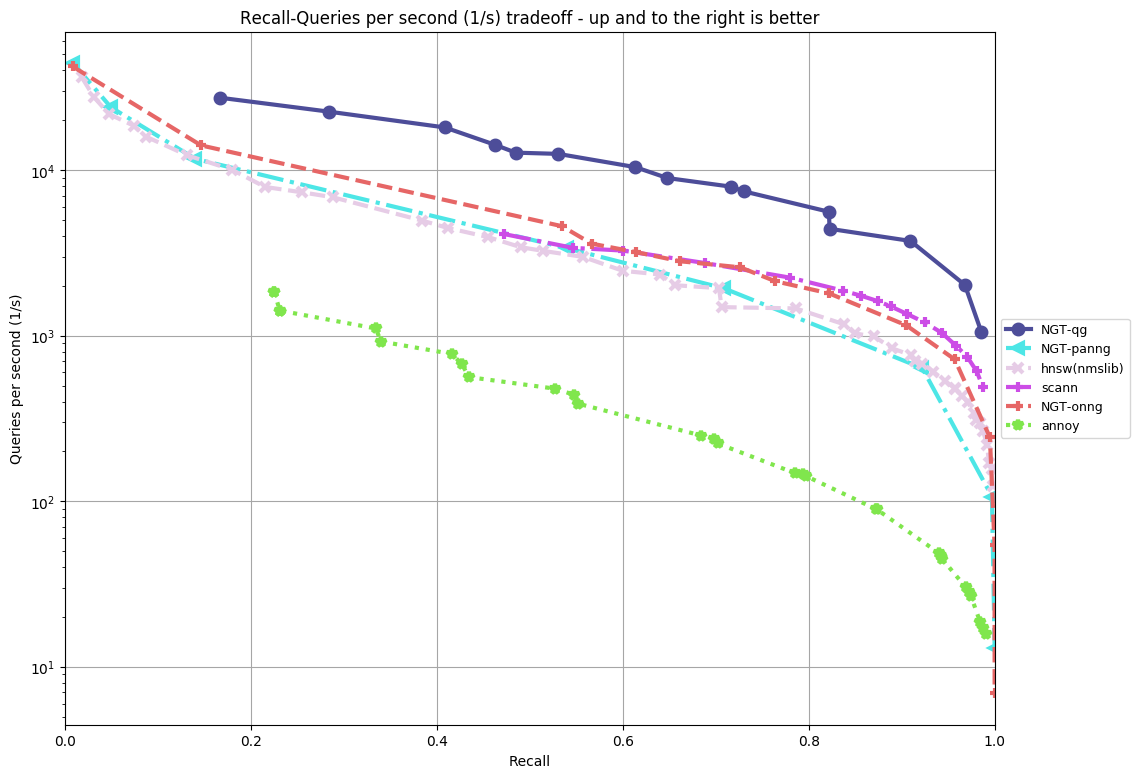
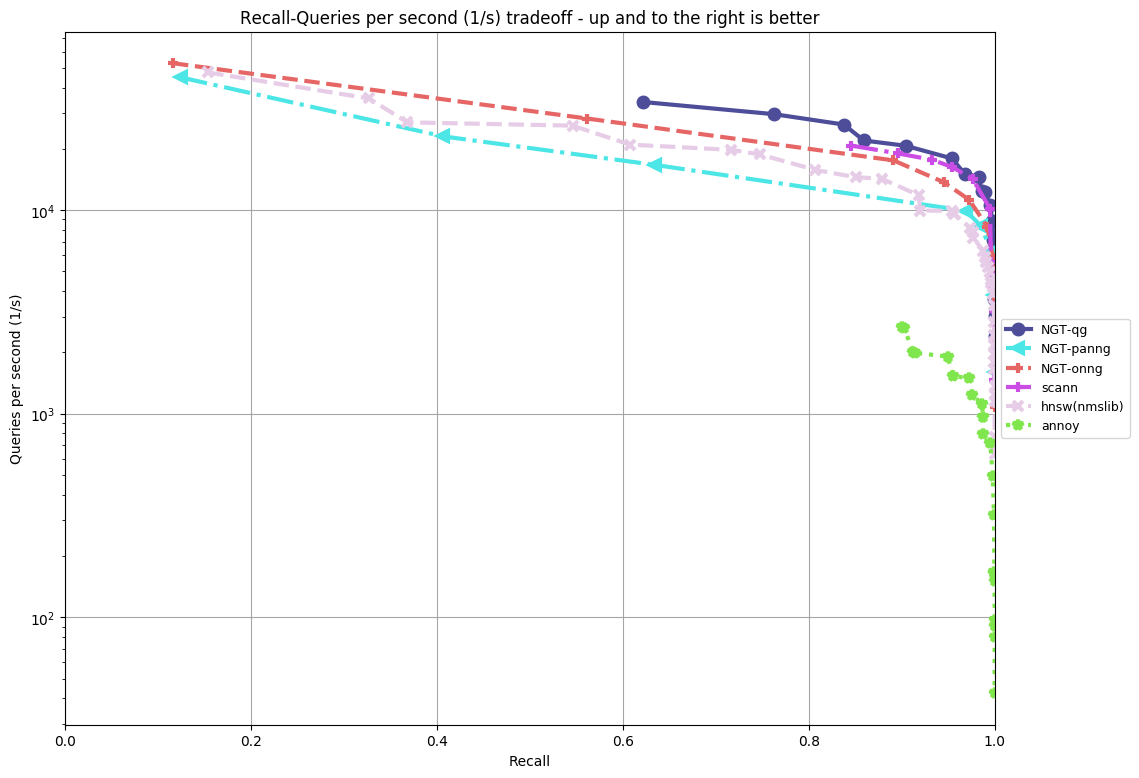
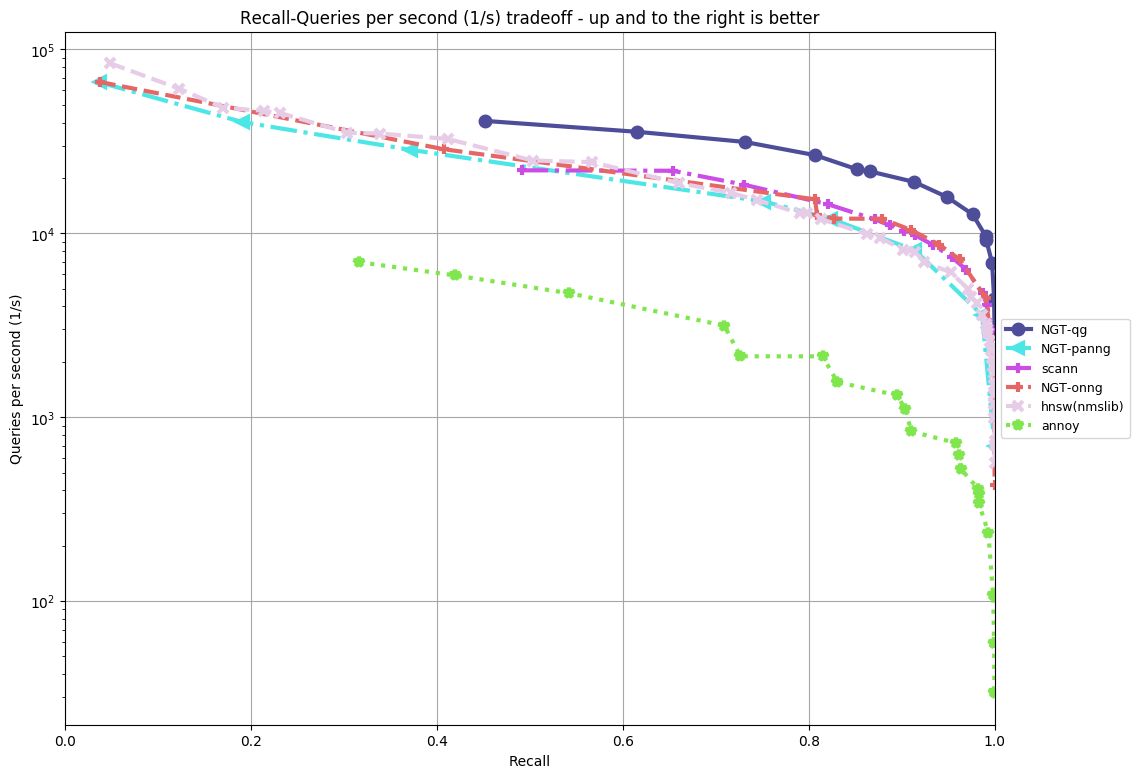
The followings are the results of ann benchmarks for NGT v2.0.0 where the timeout is 5 hours on an AWS c5.4xlarge instance.


Copyright (C) 2015 Yahoo Japan Corporation
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
This project requires contributors to accept the terms in the Contributor License Agreement (CLA).
Please note that contributors to the NGT repository on GitHub (https://github.com/yahoojapan/NGT) shall be deemed to have accepted the CLA without individual written agreements.
- Iwasaki, M., Miyazaki, D.: Optimization of Indexing Based on k-Nearest Neighbor Graph for Proximity. arXiv:1810.07355 [cs] (2018). (pdf)
- Iwasaki, M.: Pruned Bi-directed K-nearest Neighbor Graph for Proximity Search. Proc. of SISAP2016 (2016) 20-33. (pdf)
- Sugawara, K., Kobayashi, H. and Iwasaki, M.: On Approximately Searching for Similar Word Embeddings. Proc. of ACL2016 (2016) 2265-2275. (pdf)
- Iwasaki, M.: Applying a Graph-Structured Index to Product Image Search (in Japanese). IIEEJ Journal 42(5) (2013) 633-641. (pdf)
- Iwasaki, M.: Proximity search using approximate k nearest neighbor graph with a tree structured index (in Japanese). IPSJ Journal 52(2) (2011) 817-828. (pdf)
- Iwasaki, M.: Proximity search in metric spaces using approximate k nearest neighbor graph (in Japanese). IPSJ Trans. on Database 3(1) (2010) 18-28. (pdf)