{kind=link}
It's inspired by the following articles.
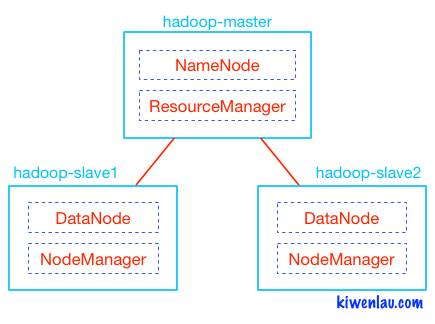
The purpose is to run the latest hadoop (currently at 3.0.0.beta1) in a mini-cluster on local machine. By default the cluster contains 1 master node + 2 slave nodes.
git clone https://github.com/yuanbing/hadoop-cluster-docker.git
cd hadoop-cluster-docker
./build-image.sh
docker network create --driver=bridge hadoop
cd hadoop-cluster-docker
./start-container.sh
output:
start hadoop-master container...
start hadoop-slave1 container...
start hadoop-slave2 container...
root@hadoop-master:~#
- start 3 containers with 1 master and 2 slaves
- you will get into the /root directory of hadoop-master container
./start-hadoop.sh
./run-wordcount.sh
output
input file1.txt:
Hello Hadoop
input file2.txt:
Hello Docker
wordcount output:
Docker 1
Hadoop 1
Hello 2
sudo ./resize-cluster.sh 5
- specify parameter > 1: 2, 3..
- this script just rebuild hadoop image with different slaves file, which pecifies the name of all slave nodes
sudo ./start-container.sh 5
- use the same parameter as the step 2
do 5~6 like section A