About stable-diffusion-2-1 #14
Comments
|
Hi @Cococyh, thanks for your interest! |
|
Hi @AttendAndExcite, thanks for your reply! Traceback (most recent call last): |
|
I think this is because when you have 768-sized image, there is not an attention dimension 16, you need to adjust the attention dimension (to 24 I guess) correspondingly. The forked codes is runnable for SDv2, but it seems like it is not effective. I found that the iterative refinement will always reach the max iter and the loss does not change much. I am trying to investigate what's wrong. |
|
Hi @XavierXiao, and @Cococyh. @XavierXiao, which prompts did you work on? It could be an issue of expressiveness of Stable Diffusion, have you tried the prompts from the paper? |
|
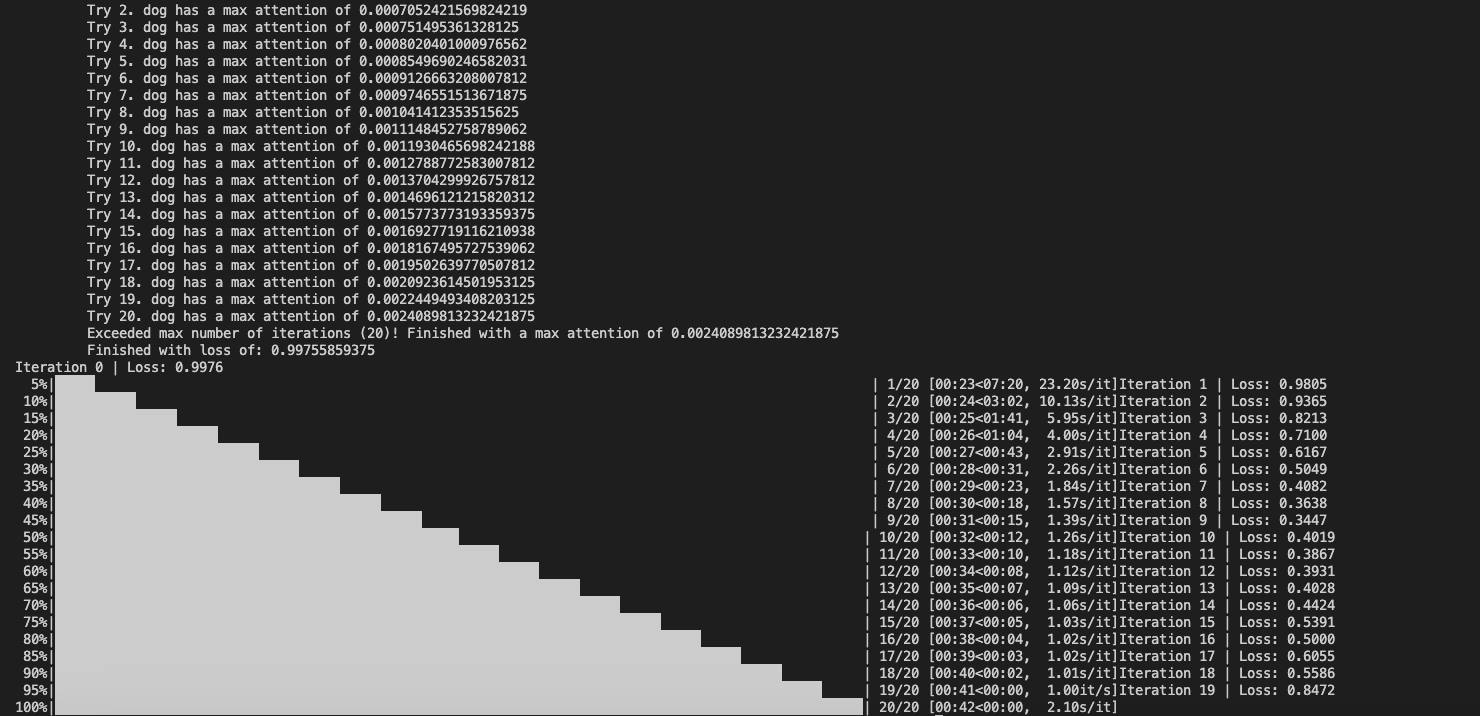
I am on a smaller GPU so I cannot run 768x768 generation. So I try stable diffusion 2-base which is a 512*512 model, with prompt Since it is still a 512 model, I use the default hyper parameters. Here is a screenshot. As you can see, I print out the grad norm and it is small. The loss does not decrease much. |

|
And the samples with (top) and without (bottom) A&E. Maybe some configs need to be changed? You can have a try with the given SD version and prompt.
|


|
Thanks for the additional information, @XavierXiao!
|
|
@AttendAndExcite @XavierXiao, As your say, I set attention dimension to 24 then it looks like I get a nice result, the result picture is 768*768.
And this is the SD version result:
|


|
@Cococyh Can you try a more complicated example like "a frog and a pink bench"? As I say above the loss hardly decrease. |
|
@AttendAndExcite ,when use sd2.1-768, the token word such as frog's max attention is too small, but use sd1.5, the number is close to 1. Then I change the scale_factor to 100, it's not effective.
|


|
@XavierXiao @Cococyh the loss appears to be quite high for the cat and the dog too- this indicates that it may be an issue of the normalization of the probabilities. We will do our best to look into this ASAP :) |
|
I found that by changing this line to |
|
Thanks @XavierXiao, this actually makes a lot of sense, as I mentioned above, since the model uses a different text encoder the attention values may vary. It is entirely possible that the attention value of <eot> is high for SD 2.1 therefore removing it and normalizing without it helps the attention values be closer to 1 and then the optimization is easier. |
|
Hi @Cococyh, and @XavierXiao, thanks for the discussion! Our code now officially supports SD 2.1 via the |
Hi,
I apply your method on stable-diffusion-1.5, it works.
But when I load the pre-trained model stable-diffusion-2-1, I meet this error, it seems like the pipeline is not work.
Seed: 0
0%| | 0/50 [00:01<?, ?it/s]
Traceback (most recent call last):
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/run.py", line 90, in
main()
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/venv/lib/python3.10/site-packages/pyrallis/argparsing.py", line 158, in wrapper_inner
response = fn(cfg, *args, **kwargs)
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/run.py", line 73, in main
image = run_on_prompt(prompt=config.prompt,
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/run.py", line 44, in run_on_prompt
outputs = model(prompt=prompt,
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/pipeline_attend_and_excite.py", line 506, in call
max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/pipeline_attend_and_excite.py", line 224, in _aggregate_and_get_max_attention_per_token
attention_maps = aggregate_attention(
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/utils/ptp_utils.py", line 232, in aggregate_attention
out = torch.cat(out, dim=0)
RuntimeError: torch.cat(): expected a non-empty list of Tensors
The text was updated successfully, but these errors were encountered: