Wave defense is a gym-like RL environment inspired from wave defense games 🌊🌊
Please ⭐ star ⭐ the repository if you like it!
| Random policy | Deep Q-Learning (DQN) | Proximal Policy Optimization (PPO) |
|---|---|---|
 |
 |
 |
The agent (cannon) shoots bullets (red squares) to enemies (blue squares) that move towards the agent. The game is solved if the agent survives for 15k steps (a random agent survives for 500 steps on average).
To reproduce the baseline agents please see the baselines repository
Watch this video to see some results on the environment.
| Episode returns (DQN) | Episode Lengths (DQN) |
|---|---|
 |
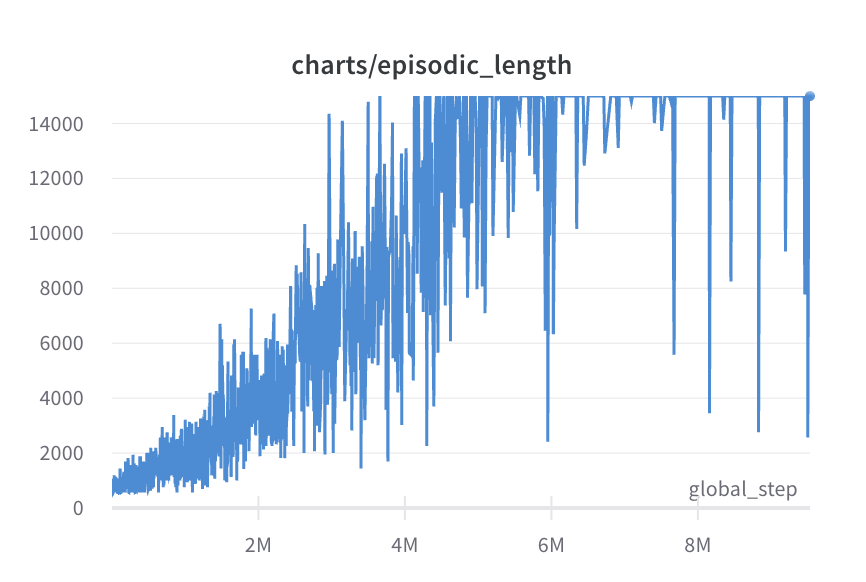 |
| Episode returns (PPO) | Episode Lengths (PPO) |
|---|---|
 |
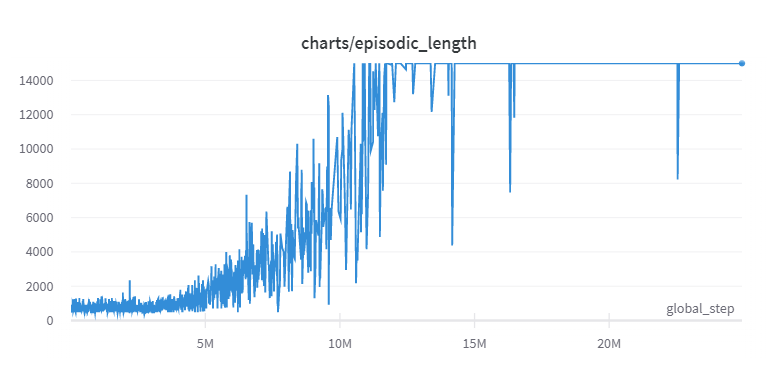 |
(Optional) Create a new conda environment
conda create -n wave_defense python=3.6
Install the package from pypi (https://pypi.org/project/WaveDefense/1.9/)
pip install WaveDefense==1.9
There exist 2 versions of the environment which can be instantiated as:
env1 = gym.make("WaveDefense-v0")
env2 = gym.make("WaveDefense-v1")
WaveDefense-v0 is for training RL agents from pixels, so it returns RGB observations of shape (256, 256, 3).
WaveDefense-v1 is for training RL agents from a tabular representation of the states, so it returns observations as vectors of length 35. The information in these vectors consists of the player's current angle, current health points, enemy distances and enemy angles.
Watching a random agent playing the game can be done as follows:
import gym
env = gym.make("WaveDefense-v0")
env.reset()
env.render()
done = False
while done is False:
obs, rew, done, info = env.step(env.action_space.sample()) # take a random action
env.render()
env.close()
The agent is rewarded depending on the number of enemies on screen (the lower the better) and the distance to these (the closer the worse). The reward distribution is the same for all the versions of the environment.
At each frame the agent choses wether to rotate left, rotate right, shoot, or do nothing.
For running in machines with no display (e.g. compute cluster) use:
os.environ["SDL_VIDEODRIVER"] = "dummy"