这是一个关于读书的练习记录,这本书的名字是《Golang高级编程》
作者的地址:https://github.com/chai2010/advanced-go-programming-book
- 调试汇编的命令
go tool compile -S pkg-data.go
- 将调试的命令放到s文件中
go tool compile -S pkg-data.go >> pkg-data.s
Go汇编中提供了DATA命令用于初始化包变量,下面是DATA的语法:
DATA symbol+offset(SB)/width, val
其中symbol为变量在汇编中对应的标示符,offset是符号的开始地址的偏移量,width是初始化内存的宽度大小,value是要初始化的值。其中当前包里中GO语言定义的symbol,在汇编代码中对应.symbol,其中“.”中点符号为一个特殊的unicode符号。
下面例子是个简单的例子:
DATA ·Id+0(SB)/1,$0x37
DATA ·Id+1(SB)/1,$0x25
给ID变量初始化了进制的0x2537,对应十进制的9527(需要以美元符号$开头表示)
汇编语⾔是直⾯计算机的编程语⾔,因此理解计算机结构是掌握汇编语⾔的前提。当前流⾏的计算机 基本采⽤的是冯·诺伊曼计算机体系结构(在某些特殊领域还有哈佛体系架构)。冯·诺依曼结构也称为 普林斯顿结构,采⽤的是⼀种将程序指令和数据存储在⼀起的存储结构。冯·诺伊曼计算机中的指令和 数据存储器其实指的是计算机中的内存,然后在配合CPU处理器就组成了⼀个最简单的计算机了。
X86其实是是80X86的简称(后⾯三个字⺟),包括Intel 8086、80286、80386以及80486等指令集 合,因此其架构被称为x86架构。x86-64是AMD公司于1999年设计的x86架构的64位拓展,向后兼容 于16位及32位的x86架构。X86-64⽬前正式名称为AMD64,也就是Go语⾔中GOARCH环境变量指定 的AMD64。
什么是寄存器?
寄存器(Register),是中央处理器内的其中组成部分。寄存器是有限存贮容量的高速存贮部件,它 们可用来暂存指令、数据和地址。在中央处理器的控制部件中,包含的寄存器有指令寄存器(IR)和程 序计数器。在中央处理器的算术及逻辑部件中,包含的寄存器有累加器。
在计算机体系结构里,处理器中的寄存器是少量且速度快的计算机存储器,借由提供快速共同地访问数 值来加速计算机程序的运行:典型地说就是在已知时间点所作的之计算中间的数值。
寄存器是存储器层次结构中的最顶端,也是系统操作数据的最快速途径。寄存器通常都是以他们可以保 存的比特数量来估量,举例来说,一个8位寄存器或32位寄存器。寄存器现在都以寄存器数组的方式来 实现,但是他们也可能使用单独的触发器、高速的核心存储器、薄膜存储器 以及在数种机器上的其他方式来实现出来。
GO汇编为了简化汇编代码的编写,引入PC,FP,SP,SB四个伪寄存器。四个伪寄存器加其它的通 ⽤寄存器就是Go汇编语⾔对CPU的重新抽象,该抽象的结构也适⽤于其它⾮X86类型的体系结构。
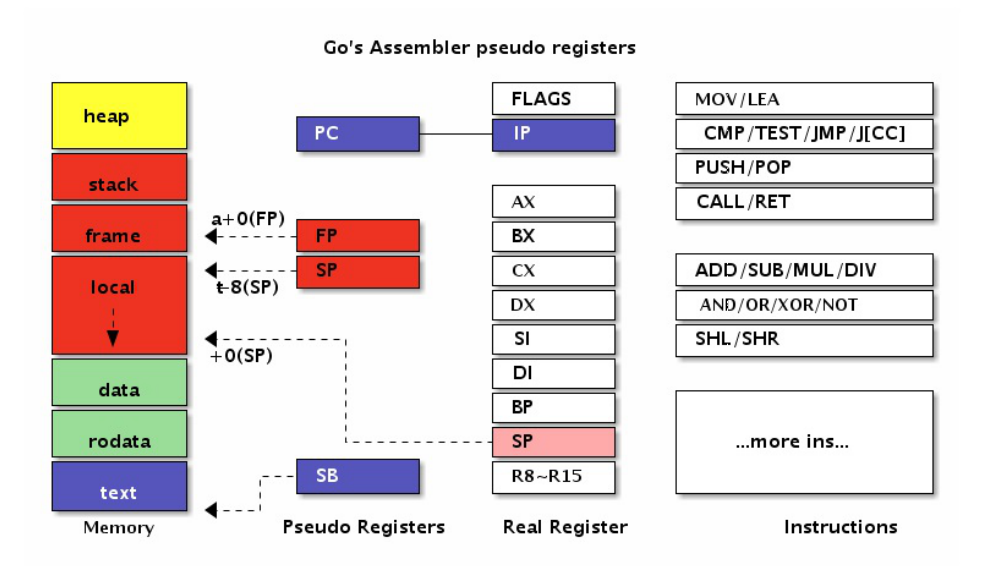
在AMD64环境中,伪PC寄存器其实是IP指令计数器寄存器的别名。伪FP寄存器对应的是函数的帧指针, 一般用来访问函数的参数和返回值。伪SP栈指针对应的是当前函数栈帧的底部(不包括参数和返 回值部分),⼀般⽤于定位局部变量。伪SP是⼀个⽐较特殊的寄存器,因为还存在⼀个同名的SP真寄 存器。真SP寄存器对应的是栈的顶部,⼀般⽤于定位调⽤其它函数的参数和返回值。
当需要区分位伪寄存器和真寄存器的时候只要记住一点:伪寄存器⼀般需要⼀个标识符和偏移量为前 缀,如果没有标识符前缀则是真寄存器。⽐如 (SP) 、 +8(SP) 没有标识符前缀为真SP寄存器, ⽽ a(SP) 、 b+8(SP) 有标识符为前缀表示伪寄存器。
通用的计算机指令可以分为数据传输指令,算术运算和逻辑运算指令,控制流指令和其他指令等几类。
几个基本的指令
| 名称 | 解释 |
|---|---|
| ADD | 加法 |
| SUB | 减法 |
| MUL | 乘法 |
| DIV | 除法 |
| AND | 逻辑与 |
| OR | 逻辑或 |
| NOT | 逻辑去反 |
控制流指令有CMP、JMP-if-x、JMP、CALL、RET等指令。CMP指令⽤于两个操作数做减法,根据⽐ 较结果设置状态寄存器的符号位和零位,可以⽤于有条件跳转的跳转条件。JMP-if-x是⼀组有条件跳转 指令,常⽤的有JL、JLZ、JE、JNE、JG、JGE等指令,对应⼩于、⼩于等于、等于、不等于、⼤于 和⼤于等于等条件时跳转。JMP指令则对应⽆条件跳转,将要跳转的地址设置到IP指令寄存器就实现 了跳转。⽽CALL和RET指令分别为调⽤函数和函数返回指令。
| 名称 | 解释 |
|---|---|
| JMP | 无条件跳转 |
| JMP-if-x | 有条件跳转,JL、JLZ、JE、JNE、JG、JGE |
| CALL | 调用函数 |
| RET | 函数返回 |
其它⽐较重要的指令有LEA、PUSH、POP等⼏个。其中LEA指令将标准参数格式中的内存地址加载到 寄存器(⽽不是加载内存位置的内容)。PUSH和POP分别是压栈和出栈指令,通⽤寄存器中的SP为 栈指针,栈是向低地址⽅向增⻓的。
| 名称 | 解释 |
|---|---|
| LEA | 取地址 |
| PUSH | 压栈 |
| POP | 出栈 |
标准库的RPC默认采⽤Go语⾔特有的gob编码,因此从其它语⾔调⽤Go语⾔实现的RPC服务将⽐较困 难。在互联⽹的微服务时代,每个RPC以及服务的使⽤者都可能采⽤不同的编程语⾔,因此跨语⾔是 互联⽹时代RPC的⼀个⾸要条件。得益于RPC的框架设计,Go语⾔的RPC其实也是很容易实现跨语⾔ ⽀持的。
Protobuf最基本的数据单元是message,是类似go语言中结构体的存在。
官方对于ProtoBuf的定义
protocol buffers 是一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。
Protocol Buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。
你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。
中型的互联⽹公司往往有着以百万计的⽤户,⽽⼤型互联⽹公司的系统则可能要服务千万级甚⾄亿级 的⽤户需求。⼤型系统的请求流⼊往往是源源不断的,任何⻛吹草动,都⼀定会有最终⽤户感受得 到。例如你的系统在上线途中会拒绝⼀些上游过来的请求,⽽这时候依赖你的系统没有做任何容错, 那么这个错误就会⼀直向上抛出,直到触达最终⽤户。形成⼀次对⽤户切切实实的伤害。这种伤害可 能是在⽤户的APP上弹出⼀个让⽤户摸不着头脑的诡异字符串,⽤户只要刷新⼀下⻚⾯就可以忘记这 件事。但也可能会让正在⼼急如焚地和⼏万竞争对⼿同时抢夺秒杀商品的⽤户,因为代码上的⼩问 题,丧失掉了先发优势,与⾃⼰蹲了⼏个⽉的⼼仪产品失之交臂。对⽤户的伤害有多⼤,取决于你的 系统对于你的⽤户来说有多重要。
不管怎么说,在⼤型系统中容错是重要的,能够让系统按百分⽐,分批次到达最终⽤户,也是很重要 的。虽然当今的互联⽹公司系统,名义上会说⾃⼰上线前都经过了充分慎重严格的测试,但就算它们 真得做到了,代码的bug总是在所难免的。即使代码没有bug,分布式服务之间的协作也是可能出现“逻 辑”上的⾮技术问题的。
这时候,灰度发布就显得⾮常重要了,灰度发布也称为⾦丝雀发布,传说17世纪的英国矿井⼯⼈发现 ⾦丝雀对瓦斯⽓体⾮常敏感,瓦斯达到⼀定浓度时,⾦丝雀即会死亡,但⾦丝雀的致死量瓦斯对⼈并 不致死,因此⾦丝雀被⽤来当成他们的瓦斯检测⼯具。互联⽹系统的灰度发布⼀般通过两种⽅式实 现:
1 通过分批次部署实现灰度发布 2 通过业务规则进行灰度发布
对旧的系统进行升级迭代时,第一种用的比较多。新功能上线时,第二种用的比较多。当然,对比较重要的 老功能进行较大幅度的修改时,一般也会选择按业务规则进行发布,因为直接全量开放给所有的用户风险太大。
例如部署在15个实例上,可以把实例分成四组,按照顺序,分别1-2-4-8,保证每次扩展时,大概都是二倍的关系。
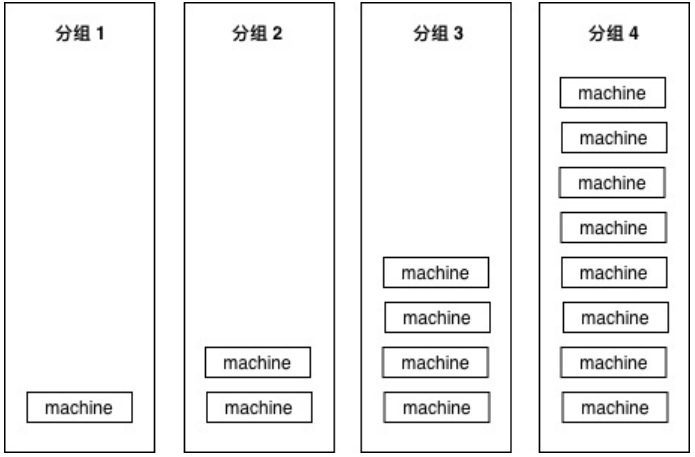
为什么是2倍呢?这样保证不管有多少台机器,都不会把组划分的太多。例如1024台机器,实 际上也就只需要1-2-4-8-16-32-64-128-256-512部署⼗次就可以全部部署完毕。
这样我们上线最开始影响到的⽤户在整体⽤户中占的⽐例也不⼤,⽐如1000台机器的服务,我们上线 后如果出现问题,也只影响1/1000的⽤户。如果10组完全平均分,那⼀上线⽴刻就会影响1/10的⽤ 户,1/10的业务出问题,那可能对于公司来说就已经是⼀场不可挽回的事故了。
上线的时候检测日志的变化,如果有明显的逻辑错误,一般错误的日志都会有明显的肉眼可见的增加。 我们通过监控这些曲线就能判断是否有异常发生。
常见的灰度发布策略很多,较为简单的需求,例如我们的策略是要按照千分比来划分,那么我们可以使用用户的ID ⼿机号、⽤户设备信息,等等,来⽣成⼀个简单的哈希值,然后再求模,⽤伪代码表示⼀下:
// pass 3/1000
func passed() bool {
key := hashFunctions(userID) % 1000
if key <= 2 {
return true
}
return false
}
常见的灰度发布系统会有下列的规则提供选择:
- 按城市发布
- 按概率发布
- 按百分⽐发布
- 按⽩名单发布
- 按业务线发布
- 按UA发布(APP、Web、PC)
- 按分发渠道发布
因为和公司的业务相关,所以城市、业务线、UA、分发渠道这些都可能会被直接编码在系统⾥,不过 功能其实⼤同⼩异。
按白名单发布比较简单,功能上线时,我们希望只有公司内部的员工和测试人员可以访问到新的功能, 会直接把账号,邮箱写入到白名单,拒绝其他任何账号的访问。
按概率发布则是指实现一个简单的函数:
func isTrue() bool {
return true/false according to the rate provided by user
}
其可以按照⽤户指定的概率返回 true 或者 false ,当然, true 的概率加 false 的概率应该是 100%。这个函数不需要任何输⼊。
func isTrue(phone string) bool {
if hash of phone matches {
return true
}
return false
}
这种情况可以按照指定的百分⽐,返回对应的 true 和 false ,和上⾯的单纯按照概率的区别是这⾥ 我们需要调⽤⽅提供给我们⼀个输⼊参数,我们以该输⼊参数作为源来计算哈希,并以哈希后的结果 来求模,并返回结果。这样可以保证同⼀个⽤户的返回结果多次调⽤是⼀致的,在下⾯这种场景下, 必须使⽤这种结果可预期的灰度算法。
如果使用随机的会出现下面的情况
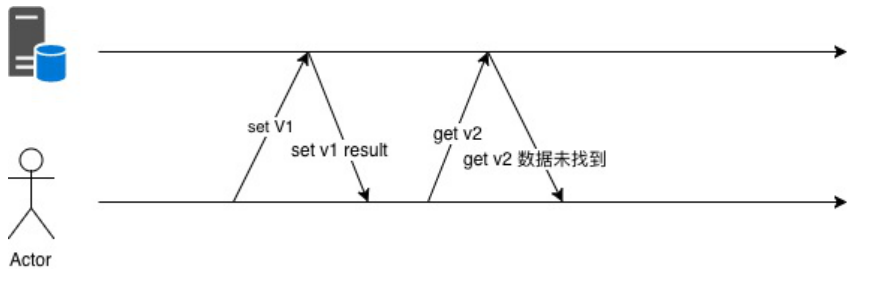
举个具体的例⼦,⽹站的注册环节,可能有两套API,按照⽤户ID进⾏灰度,分别是不同的存取逻辑。 如果存储时使⽤了V1版本的API⽽获取时使⽤V2版本的API,那么就可能出现⽤户注册成功后反⽽返回 注册失败消息的诡异问题。
公司内⼀般都会有公共的城市名字和id的映射关系,如果业务只涉及中国国内,那么城市数量不会特别 多,且id可能都在10000范围以内。那么我们只要开辟⼀个⼀万⼤⼩左右的bool数组,就可以满⾜需求 了:
var cityID2Open = [12000]bool{}
func init() {
readConfig()
for i:=0;i<len(cityID2Open);i++ {
if city i is opened in configs {
cityID2Open[i] = true
}
}
}
func isPassed(cityID int) bool {
return cityID2Open[cityID]
}
如果公司给cityID赋的值⽐较⼤,那么我们可以考虑⽤map来存储映射关系,map的查询⽐数组稍慢, 但扩展会灵活⼀些:
var cityID2Open = map[int]struct{}{}
func init() {
readConfig()
for _, city := range openCities {
cityID2Open[city] = struct{}{}
}
}
func isPassed(cityID int) bool {
if _, ok := cityID2Open[cityID]; ok {
return true
}
return false
}
按⽩名单、按业务线、按UA、按分发渠道发布,本质上和按城市发布是⼀样的,这⾥就不再赘述了按概率发布稍微特殊⼀些,不过不考虑输⼊实现起来也很简
func init() {
rand.Seed(time.Now().UnixNano())
}
// rate 为 0~100
func isPassed(rate int) bool {
if rate >= 100 {
return true
}
if rate > 0 && rand.Int(100) > rate {
return true
}
return false
}
package main
import (
"crypto/md5"
"crypto/sha1"
"github.com/spaolacci/murmur3"
)
var str = "hello world"
func md5Hash() [16]byte {
return md5.Sum([]byte(str))
}
func sha1Hash() [20]byte {
return sha1.Sum([]byte(str))
}
func murmur32() uint32 {
return murmur3.Sum32([]byte(str))
}
func murmur64() uint64 {
return murmur3.Sum64([]byte(str))
}
对于一些数据插入数据库之前,我们希望首先给这些信息打上一个ID,然后插入到我们的数据库 。对于这个ID的要求,我们希望带一些时间信息,这样即使我们做了分库分表,也能够以时间顺序 对这些消息进行排序。

首先,我们确定我们的数值是64位,被划分四部分,不含开头的第一个bit,因为这个bit是符号位。 ⽤41位来表示收到请求时的时间戳,单位为毫秒,然后五位来表示数据中⼼的id,然后再五位来 表示机器的实例id,最后是12位的循环⾃增id(到达1111,1111,1111后会归0)。
这样的机制可以⽀持我们在同⼀台机器上,同⼀毫秒内产⽣ 2 ^ 12 = 4096 条消息。⼀秒共409.6万条 消息。从值域上来讲完全够⽤了。 数据中⼼加上实例id共有10位,可以⽀持我们每数据中⼼部署32台机器,所有数据中⼼共1024台实 例。
表示 timestamp 的41位,可以⽀持我们使⽤69年。当然,我们的时间毫秒计数不会真的从1970年开始 记,那样我们的系统跑到 2039/9/7 23:47:35 就不能⽤了,所以这⾥的 timestamp 实际上只是相对于 某个时间的增量,⽐如我们的系统上线是2018-08-01,那么我们可以把这个timestamp当作是从 2018- 08-01 00:00:00.000 的偏移量。
timestamp , datacenter_id , worker_id 和 sequence_id 这四个字段 中, timestamp 和 sequence_id 是由程序在运⾏期⽣成的。但 datacenter_id 和 worker_id 需要我们 在部署阶段就能够获取得到,并且⼀旦程序启动之后,就是不可更改的了(想想,如果可以随意更 改,可能被不慎修改,造成最终⽣成的id有冲突)。
⼀般不同数据中⼼的机器,会提供对应的获取数据中⼼id的API,所以 datacenter_id 我们可以在部署 阶段轻松地获取到。⽽worker_id是我们逻辑上给机器分配的⼀个id,这个要怎么办呢?⽐较简单的想 法是由能够提供这种⾃增id功能的⼯具来⽀持,⽐如MySQL:
mysql> insert into a (ip) values("10.1.2.101");
Query OK, 1 row affected (0.00 sec)
mysql> select last_insert_id();
+------------------+
| last_insert_id() |
+------------------+
| 2 |
+------------------+
1 row in set (0.00 sec)
从MySQL中获取到 worker_id 之后,就把这个 worker_id 直接持久化到本地,以避免每次上线时都需 要获取新的 worker_id 。让单实例的 worker_id 可以始终保持不变。
当然,使⽤MySQL相当于给我们简单的id⽣成服务增加了⼀个外部依赖。依赖越多,我们的服务的可 运维性就越差。
考虑到集群中即使有单个id⽣成服务的实例挂了,也就是损失⼀段时间的⼀部分id,所以我们也可以更 简单暴⼒⼀些,把 worker_id 直接写在worker的配置中,上线时,由部署脚本完成 worker_id 字段替 换。
github.com/bwmarrin/snowflake 是⼀个相当轻量化的snowflake的Go实现。

并发的程序的运行,难免涉及对同一个变量的操作。这时候就需要加锁处理。