We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
时间:2016-12-12 17:51:30 作者: zhongxia
这里主要写的是理论,具体实践的比较少,后期写一个实践教程,内容基本都是从参考文章里面抄过来的【看完文章,顺便写做下笔记,加深理解。】
浏览器缓存,也就是客户端缓存,既是网页性能优化里面静态资源相关优化的一大利器,也是无数web开发人员在工作过程不可避免的一大问题,所以在产品开发的时候我们总是想办法避免缓存产生,而在产品发布之时又在想策略管理缓存提升网页的访问速度。
了解浏览器的缓存命中原理,是开发web应用的基础,本文着眼于此,学习浏览器缓存的相关知识,总结缓存避免和缓存管理的方法,结合具体的场景说明缓存的相关问题。希望能对有需要的人有所帮助。
浏览器在加载资源的时,先根据 http header 判断它是否命中强缓存.
命中强缓存:浏览器直接从自己缓存中读取资源,不发送请求到服务器
不命中强缓存:浏览器发送一个请求到服务器,服务器根据资源的另外一些 http header 验证 该资源 是否命中 协商缓存
命中协商缓存:将请求返回,但不是返回该资源的数据,而是告诉浏览器可以直接从缓存中加载这个资源。
不命中协商缓存:服务器返回该资源数据
共同点:命中,都是从浏览器缓存中加载资源 不同点:强缓存不发送请求到服务器,协商缓存会发送请求。
必须开启强缓存,协商缓存才会起作用
什么是协商缓存? 如图,返回http状态为200,size为 form cache 的就是强缓存
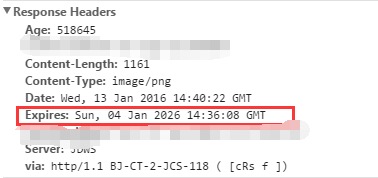
HTTP1.0 时代,Expires 【表示资源过期时间】【缓存过期的下一个时间 必须GMT 格式】
可能存在问题:服务器时间和客户端时间不一致,因此 HTTP1.1 出了一些 Cache-control
如图:
HTTP1.1 时代,Cache-control: 过期时间【缓存多少毫秒】 如图:
例子:
浏览器第一次请求资源,服务器在返回的同时,会在 response 的 header 上加上 Expires
浏览器收到资源后,把资源和 Expires 一起缓存下来
第二次请求资源时,拿出Expires和当前请求时间比较下,如果还未过期,则直接从缓存中读取出来,【这个就叫命中缓存】
没有命中的话,去服务端请求,走协商缓存道路,最后返回时,会返回一个新的 Expires , 浏览器在缓存下来。
和 Expires一样,只是 过期时间=当前时间+Cache-control 的 Max-age 缓存毫秒数
通过代码的形式,在web服务器的返回响应 header 中添加 Expies, Cache-control
java.util.Date date = new java.util.Date(); response.setDateHeader("Expires",date.getTime()+20000); //Expires:过时期限值 response.setHeader("Cache-Control", "public"); //Cache-Control来控制页面的缓存与否,public:浏览器和缓存服务器都可以缓存页面信息; response.setHeader("Pragma", "Pragma"); //Pragma:设置页面是否缓存,为Pragma则缓存,no-cache则不缓存
设置不缓存
response.setHeader( "Pragma", "no-cache" ); response.setDateHeader("Expires", 0); response.addHeader( "Cache-Control", "no-cache" );//浏览器和缓存服务器都不应该缓存页面信息
让web服务器在响应资源的时候统一添加Expires和Cache-Control Header
nginx和apache作为专业的web服务器,都有专门的配置文件,可以配置expires和cache-control,这方面的知识,如果你对运维感兴趣的话,可以在百度上搜索“nginx 设置 expires cache-control”或“apache 设置 expires cache-control”都能找到不少相关的文章。
强缓存是前端性能优化最有力的工具,没有之一。
大量的静态资源网站,一定要利用强缓存,提高响应速度
例子,京东页面,强缓存到2026年。【这个强缓存可以有】
使用强缓存后,如何更新网站呢?
给文件加上 hash 值。
知乎上的完美解决方案 https://www.zhihu.com/question/20790576
强缓存还有一点需要注意的是,通常都是针对静态资源使用,动态资源需要慎用,除了服务端页面可以看作动态资源外,那些引用静态资源的html也可以看作是动态资源,如果这种html也被缓存,当这些html更新之后,可能就没有机制能够通知浏览器这些html有更新,尤其是前后端分离的应用里,页面都是纯html页面,每个访问地址可能都是直接访问html页面,这些页面通常不加强缓存,以保证浏览器访问这些页面时始终请求服务器最新的资源
如图:返回http状态304,Not Modified
说白了就是浏览器自己不确定,没有办法决定,因此要找 服务器商量下。 服务器说可以,那浏览器就直接从自己缓存里面找出资源, 服务器说你这个不行啊,过期了。 我给你个新的,浏览器就拿新的咯。
协商缓存要发请求,所有header都是 response 和 request 一人一个。
协商缓存是利用的是【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】这两对Header来管理的。
Response Header : Last-Modified, ETag Request Header : If-Modified-Since , If-None-Match
第一次跟web服务器请求资源时,在 response 的 header 加上 Last-Modified【文件最后修改时间】
浏览器收到资源的时候,把资源文件和 Last-Modified 缓存起来
再次请求的时候, 在 Request Header 加上 If-Modified-Since 的 header, 这个值,就是 第一次web服务器返回的 Last-Modified。
web服务器收到之后,判断 Last-Modified-Since 和 Last-Modified 是否一致,一致则返回 304 Not Modified. 让浏览器去加载缓存里面的。
不一致的话,返回资源,并返回一个新的 Last-Modified
浏览器继续缓存下来, 然后继续上面的步骤。
【Last-Modified,If-Modified-Since】都是根据服务器时间返回的header,一般来说,在没有调整服务器时间和篡改客户端缓存的情况下,这两个header配合起来管理协商缓存是非常可靠的,但是有时候也会服务器上资源其实有变化,但是最后修改时间却没有变化的情况,而这种问题又很不容易被定位出来,而当这种情况出现的时候,就会影响协商缓存的可靠性。所以就有了另外一对header来管理协商缓存,这对header就是【ETag、If-None-Match】。
所有的步骤都是差不多的
发送请求,返回资源的时候,也返回了一个 ETag【文件的Hash值】
浏览器缓存资源,并缓存下 ETag
再次请求的时候,Request Header If-None-Match 把上次传过来的 ETag 传过去
web服务器,在生成一个资源文件的 ETag, 然后跟传过来的比较
一样,返回 304 Not-Modified,浏览器从缓存拿
不一样, web服务器返回资源,并返回一个新的 ETag, 然后重复上面操作。
强缓存 和 协商缓存的 缓存管理都是一样的步骤哈。
在分布式部署的时候,多台机器的 Last-Modified 必须保持一致,否则协商缓存会出问题。
分布式部署,不同的机器生成的 ETag 都会不一样。 然后协商缓存就会出问题。【因此如果没有搞定ETag 一致,就先关闭掉。】
协商缓存 需要 配合 强缓存使用 【不启动强缓存,协商缓存也就不起作用】 response header 包含了强缓存的管理 header
如果资源已经被浏览器缓存下来,在缓存失效之前,再次请求时,默认会先检查是否命中强缓存,如果强缓存命中则直接读取缓存,如果强缓存没有命中则发请求到服务器检查是否命中协商缓存,如果协商缓存命中,则告诉浏览器还是可以从缓存读取,否则才从服务器返回最新的资源。这是默认的处理方式,这个方式可能被浏览器的行为改变:
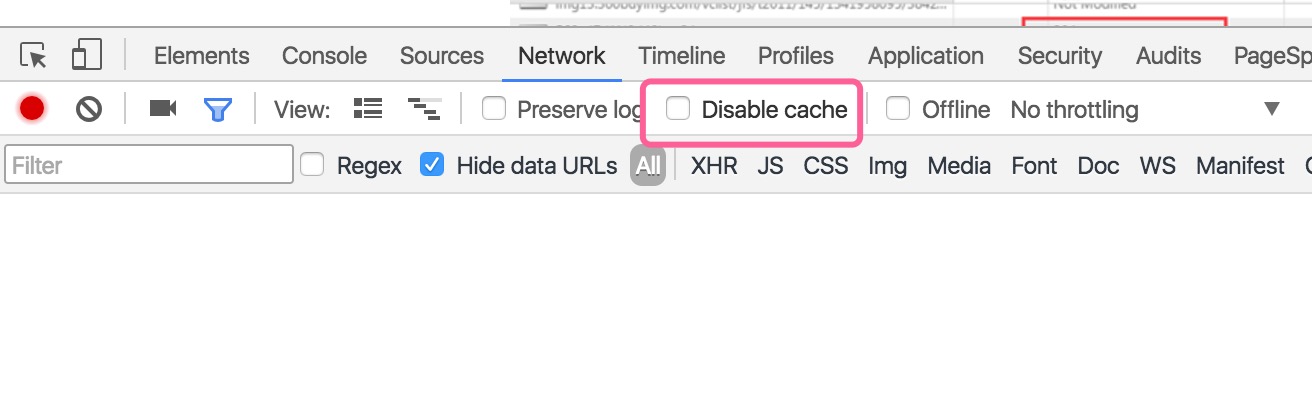
勾选这个 disable cache 缓存, 则不会使用缓存
The text was updated successfully, but these errors were encountered:
No branches or pull requests
零、前言
浏览器缓存,也就是客户端缓存,既是网页性能优化里面静态资源相关优化的一大利器,也是无数web开发人员在工作过程不可避免的一大问题,所以在产品开发的时候我们总是想办法避免缓存产生,而在产品发布之时又在想策略管理缓存提升网页的访问速度。
了解浏览器的缓存命中原理,是开发web应用的基础,本文着眼于此,学习浏览器缓存的相关知识,总结缓存避免和缓存管理的方法,结合具体的场景说明缓存的相关问题。希望能对有需要的人有所帮助。
一、浏览器缓存基本认识
1. 强缓存 和 协商缓存
浏览器在加载资源的时,先根据 http header 判断它是否命中强缓存.
命中强缓存:浏览器直接从自己缓存中读取资源,不发送请求到服务器
不命中强缓存:浏览器发送一个请求到服务器,服务器根据资源的另外一些 http header 验证 该资源 是否命中 协商缓存
命中协商缓存:将请求返回,但不是返回该资源的数据,而是告诉浏览器可以直接从缓存中加载这个资源。
不命中协商缓存:服务器返回该资源数据
2. 异同点 和 关系
共同点:命中,都是从浏览器缓存中加载资源
不同点:强缓存不发送请求到服务器,协商缓存会发送请求。
必须开启强缓存,协商缓存才会起作用
二、强缓存原理
什么是协商缓存?
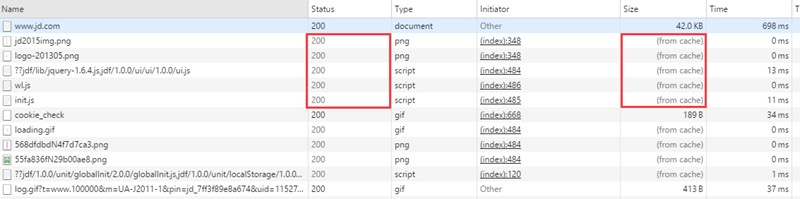
如图,返回http状态为200,size为 form cache 的就是强缓存
1. HTTP Response Header 看强缓存
Expires
HTTP1.0 时代,Expires 【表示资源过期时间】【缓存过期的下一个时间 必须GMT 格式】
如图:
Cache-control
HTTP1.1 时代,Cache-control: 过期时间【缓存多少毫秒】
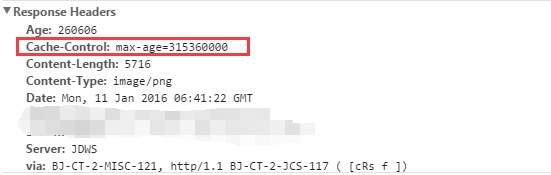
如图:
例子:
Expires步骤
浏览器第一次请求资源,服务器在返回的同时,会在 response 的 header 上加上 Expires
浏览器收到资源后,把资源和 Expires 一起缓存下来
第二次请求资源时,拿出Expires和当前请求时间比较下,如果还未过期,则直接从缓存中读取出来,【这个就叫命中缓存】
没有命中的话,去服务端请求,走协商缓存道路,最后返回时,会返回一个新的 Expires , 浏览器在缓存下来。
Cache-control 步骤
和 Expires一样,只是 过期时间=当前时间+Cache-control 的 Max-age 缓存毫秒数
Cache-control 和 Expires
如何设置强缓存?
1. 代码形式
设置不缓存
2. web服务器配置
nginx和apache作为专业的web服务器,都有专门的配置文件,可以配置expires和cache-control,这方面的知识,如果你对运维感兴趣的话,可以在百度上搜索“nginx 设置 expires cache-control”或“apache 设置 expires cache-control”都能找到不少相关的文章。
3. 强缓存的应用
强缓存是前端性能优化最有力的工具,没有之一。
大量的静态资源网站,一定要利用强缓存,提高响应速度
例子,京东页面,强缓存到2026年。【这个强缓存可以有】
使用强缓存后,如何更新网站呢?
知乎上的完美解决方案
https://www.zhihu.com/question/20790576
三、协商缓存
1. 什么是协商缓存?
如图:返回http状态304,Not Modified

说白了就是浏览器自己不确定,没有办法决定,因此要找 服务器商量下。 服务器说可以,那浏览器就直接从自己缓存里面找出资源, 服务器说你这个不行啊,过期了。 我给你个新的,浏览器就拿新的咯。
协商缓存要发请求,所有header都是 response 和 request 一人一个。
2. 协商缓存如何控制?
协商缓存是利用的是【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】这两对Header来管理的。
Response Header : Last-Modified, ETag
Request Header : If-Modified-Since , If-None-Match
3. 【Last-Modified,If-Modified-Since】缓存管理方式
第一次跟web服务器请求资源时,在 response 的 header 加上 Last-Modified【文件最后修改时间】
浏览器收到资源的时候,把资源文件和 Last-Modified 缓存起来
再次请求的时候, 在 Request Header 加上 If-Modified-Since 的 header, 这个值,就是 第一次web服务器返回的 Last-Modified。
web服务器收到之后,判断 Last-Modified-Since 和 Last-Modified 是否一致,一致则返回 304 Not Modified. 让浏览器去加载缓存里面的。
不一致的话,返回资源,并返回一个新的 Last-Modified
浏览器继续缓存下来, 然后继续上面的步骤。
4.【ETag、If-None-Match】的缓存管理的方式是
发送请求,返回资源的时候,也返回了一个 ETag【文件的Hash值】
浏览器缓存资源,并缓存下 ETag
再次请求的时候,Request Header If-None-Match 把上次传过来的 ETag 传过去
web服务器,在生成一个资源文件的 ETag, 然后跟传过来的比较
一样,返回 304 Not-Modified,浏览器从缓存拿
不一样, web服务器返回资源,并返回一个新的 ETag, 然后重复上面操作。
5. 注意ETag的使用
在分布式部署的时候,多台机器的 Last-Modified 必须保持一致,否则协商缓存会出问题。
分布式部署,不同的机器生成的 ETag 都会不一样。 然后协商缓存就会出问题。【因此如果没有搞定ETag 一致,就先关闭掉。】
协商缓存 需要 配合 强缓存使用 【不启动强缓存,协商缓存也就不起作用】

response header 包含了强缓存的管理 header
四、浏览器行为对缓存的影响
五、注意点
勾选这个 disable cache 缓存, 则不会使用缓存
参考文章
The text was updated successfully, but these errors were encountered: