About inputs to the decoder #223
Comments
|
@zhouhaoyi |
|
@zhouhaoyi Or does the encoder receive (X_i,...,X_{i+27},X_{i+28},...,X_{i+55}) and the decoder receives (X_i,...,X_{i+27},0,...,0) ? |
Hi, your understanding is correct, the input of Encoder is (X_i,...,X_{i+27}) and the input of Decoder can be (X_j,...,X_{i+27},0,...,0}, where i<=j<=i+27). (X_{i+28},...,X_{i+55}) is the groudtruth and we do not use it as input. |
|
Thanks @cookieminions |
|
Thank you for the kind answers. I have another question - when looking at the InformerStack class in |
|
Hi, |
|
@cookieminions So I am guessing that this information corresponds to the section "Appendix B The Uniform Input |
|
@cookieminions So my timestamp is in the format of where x[:,:,0] = 2016, x[:,:,1] = 1, x[:,:,2] = 1, x[:,:,3] = 5 for date 2016-01-01 Friday. here I can encode sunday, monday, tuesday, ... to 0,1,2,... and I will set freq = 'd' when I declare the model. |
|
@cookieminions Now, did I define the model parameters correctly? So the decoder takes in 21 sequences, where each sequence has starter length 28, and prediction length 28 (so we want to predict the next 28 days). And I assume out_len is 56 because it is the sum of the starter sequence + zero padded target tokens? So if the batch size is 32, the dimensions of my inputs are as follows: encoder_input: [32,28,21] But when I do model.forward() I get the following error
I tried running a simple code like this |
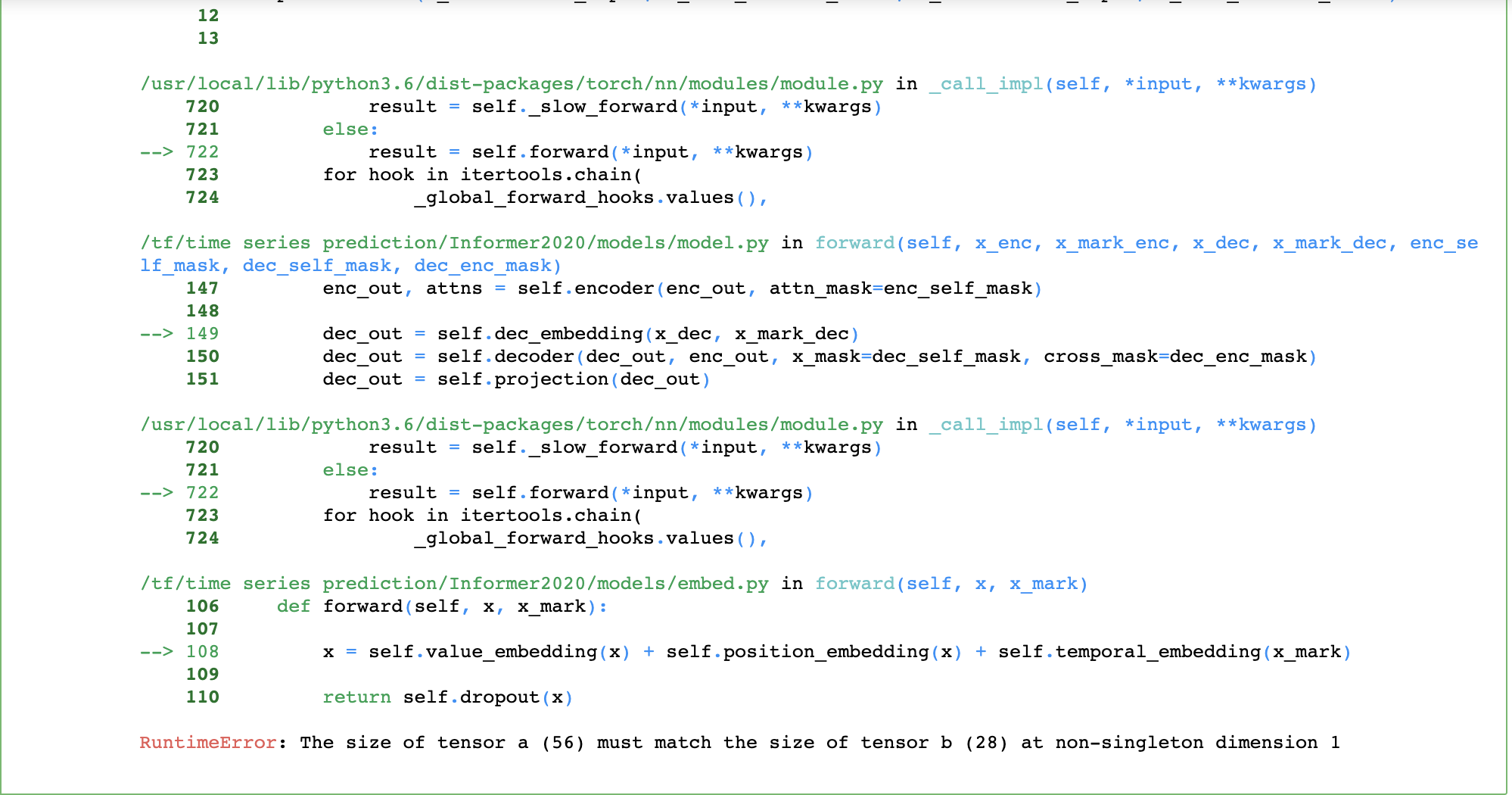
|
Hi, |
|
@cookieminions @zhouhaoyi I have a question though. During inference, although I set the model to eval mode by and the results for outputs is slightly different all the time, even though eval() mode is on and I am using torch.no_grad(). |
|
Oh I guess it was because of the probsparse attention. If I just use the full transformer (setting attn = 'full') I do not have the problem of having inconsistent outputs. By the way, even if the outputs are inconsistent, they are not supposed to deviate that much right? |
|
I think the inconsistency comes from the current implementation of Probsparse, in which the unselected attention may refer to the same leaf node rather than its original one. Please give a brief description of the following architecture, it may help us locate the problem. Thanks! |
|
nice discussion! |
|
Hey guys @zhouhaoyi @cookieminions @puzzlecollector , such a nice discussion to follow. I am working on Informer for a multivariate problem where I am having 94 features and one output target. I have a question about the model inference/prediction. In the My question is why are we concatenating batch_y values as in realtime, we will not be having batch_y values. I trained a model and the results look so promising with the above decoder input but if I don't use the batch_y concatenation part then the results aren't looking good. |
@zhouhaoyi
Suppose I want to input a 28 length sequence, X_i,...,X_{i+27} and want to predict the 28 length sequence X_{i+28},...,X_{i+55}. Then the encoder will take in (X_i,...,X_{i+27}) as input and the decoder will take in (X_i,...,X_{i+27},0,...,0}. Is my understanding correct? Is this what you meant in the paper when you said you concat the start token and the zero placeholder for the target?
The text was updated successfully, but these errors were encountered: