Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning
Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning
Zhiwen Zuo, Lei Zhao, Ailin Li, Zhizhong Wang, Zhanjie Zhang, Jiafu Chen, Wei Xing, and Dongming Lu.
If any part of our paper and code is helpful to your work, please generously cite and star us!
@article{zuo2023generative,
title={Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning},
author={Zuo, Zhiwen and Zhao, Lei and Li, Ailin and Wang, Zhizhong and Zhang, Zhanjie and Chen, Jiafu and Xing, Wei and Lu, Dongming},
journal={arXiv preprint arXiv:2303.13133},
year={2023}
}
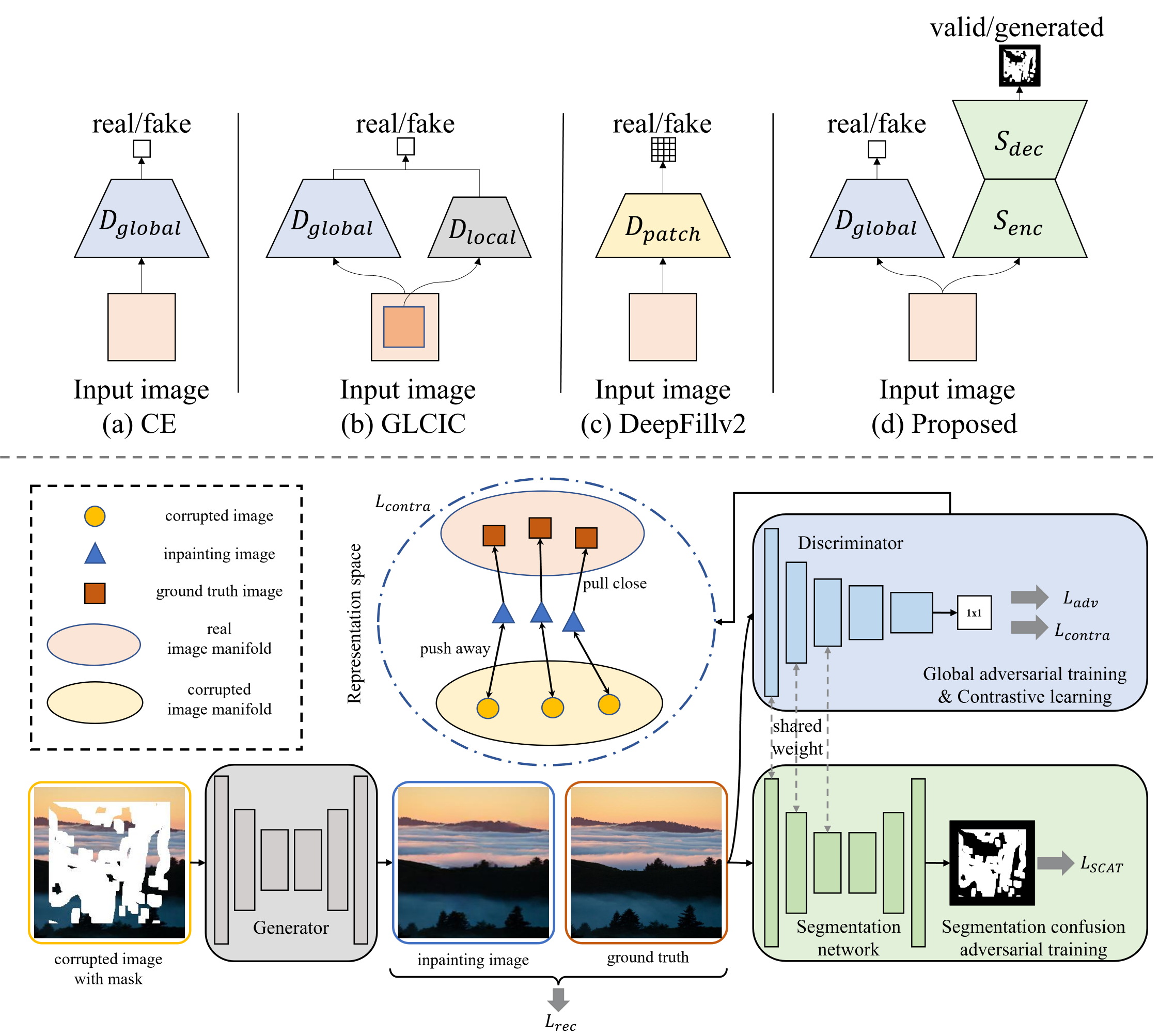
We present a new adversarial training framework for image inpainting with segmentation confusion adversarial training (SCAT) and contrastive learning.
- First, inspired by how humans recognize a low-quality repaired image, we propose SCAT, playing an adversarial game between an inpainting generator and a segmentation network. The segmentation network labels the generated and valid regions in the inpainting image. On the contrary, the inpainting generator tries to deceive the segmentation network by filling the missing regions with more visually plausible and consistent contents, making it more difficult for the segmentation network to label the two regions. SCAT provides pixel-level local training signals for our framework and can flexibly handle images with free-form holes.
- To stabilize and improve training, we further propose contrastive learning losses by exploiting the feature representation space of the discriminator, in which the inpainting images are pulled closer to the ground truth images but pushed farther from the corrupted images. As the training process of image inpainting can be regarded as learning a mapping from the corrupted images to the ground truth images, our proposed contrastive losses can better guide the process with their pull and push forces, bringing more realistic inpainting results.

- python 3.8.8
- pytorch (tested on Release 1.8.1)
Clone this repo.
git clone https://github.com/zzw-zjgsu/Generative-Image-Inpainting
cd Generative-Image-Inpainting/
For the full set of required Python packages, we suggest create a Conda environment from the provided YAML, e.g.
conda env create -f environment.yml
conda activate inpainting
- Download images and masks, note that our models are trained using irregular masks from PConv. For using random masks as in Co-Mod-GAN, you can specify
--mask_type random, which may gain better performance. - Specify the path to training data by
--dir_imageand--dir_mask.
-
Training:
- For training on CelebA dataset, run
cd src python train.py --dir_image [image path] --dir_mask [pconv mask path] --dataset CelebA --iterations 300000 --crop_size 178 --transform centercrop- For training on Places2 dataset, run
cd src python train.py --dir_image [image path] --scan_subdirs --dir_mask [pconv mask path] --dataset Places2 --iterations 1000000 --transform randomcrop -
Resume training:
cd src python train.py --resume -
Testing:
cd src python single_test.py --pre_train [path to pretrained model] --ipath [image path] --mpath [mask path] --outputs [output path] -
Evaluating (calucating PSNR/SSIM/L1):
cd src python test.py --pre_train [path to pretrained model] --dir_image [image path] --dir_mask [mask path] --outputs [output path]
Visualization on TensorBoard for training is supported.
Run tensorboard --logdir [log_folder] --bind_all and open browser to view training progress.
We would like to thank aot-gan and pytorch-msssim.