

TE2Rules is a technique to explain Tree Ensemble models (TE) like XGBoost, Random Forest, trained on a binary classification task, using a rule list. The extracted rule list (RL) captures the necessary and sufficient conditions for classification by the Tree Ensemble. The algorithm used by TE2Rules is based on Apriori Rule Mining. For more details on the algorithm, please check out our paper.
TE2Rules provides a ModelExplainer which takes a trained TE model and training data to extract rules. The training data is used for extracting rules with relevant combination of input features. Without data, an explainer would have to extract rules for all possible combinations of input features, including those combinations which are extremely rare in the data.
TE2Rules package is available on PyPI and can be installed with pip:
pip install te2rulesThe official documentation of TE2Rules can be found at te2rules.readthedocs.io.
TE2Rules contains a ModelExplainer class with an explain() method which returns a rule list corresponding to the positive class prediciton of the tree ensemble. While using the rule list, any data instance that does not trigger any of the extracted rules is to be interpreted as belonging to the negative class. The explain() method has tunable parameters to control the interpretability, faithfulness, runtime and coverage of the extracted rules. These are:
-
min_precision:min_precisioncontrols the minimum precision of extracted rules. Setting it to a smaller threshold, allows extracting shorter (more interpretable, but less faithful) rules. By default, the algorithm uses a minimum precision threshold of 0.95. -
num_stages: The algorithm runs in stages starting from stage 1, stage 2 to all the way till stage n where n is the number of trees in the ensemble. Stopping the algorithm at an early stage results in a few short rules (with quicker run time, but less coverage in data). It is recommended to try running 2 or 3 stages. By default, the algorithm explores all stages before terminating. -
jaccard_threshold: This parameter (between 0 and 1) controls how rules from different node combinations are combined. As the algorithm proceeds in stages, combining two similar rules from the previous stage results in yet another similar rule in the next stage. This is not useful in finding new rules that explain the model. Settingjaccard_thresholdto a smaller value, speeds up the algorithm by only combining dissimilar rules from the previous stages. By default, the algorithm uses a jaccard threshold of 0.20.
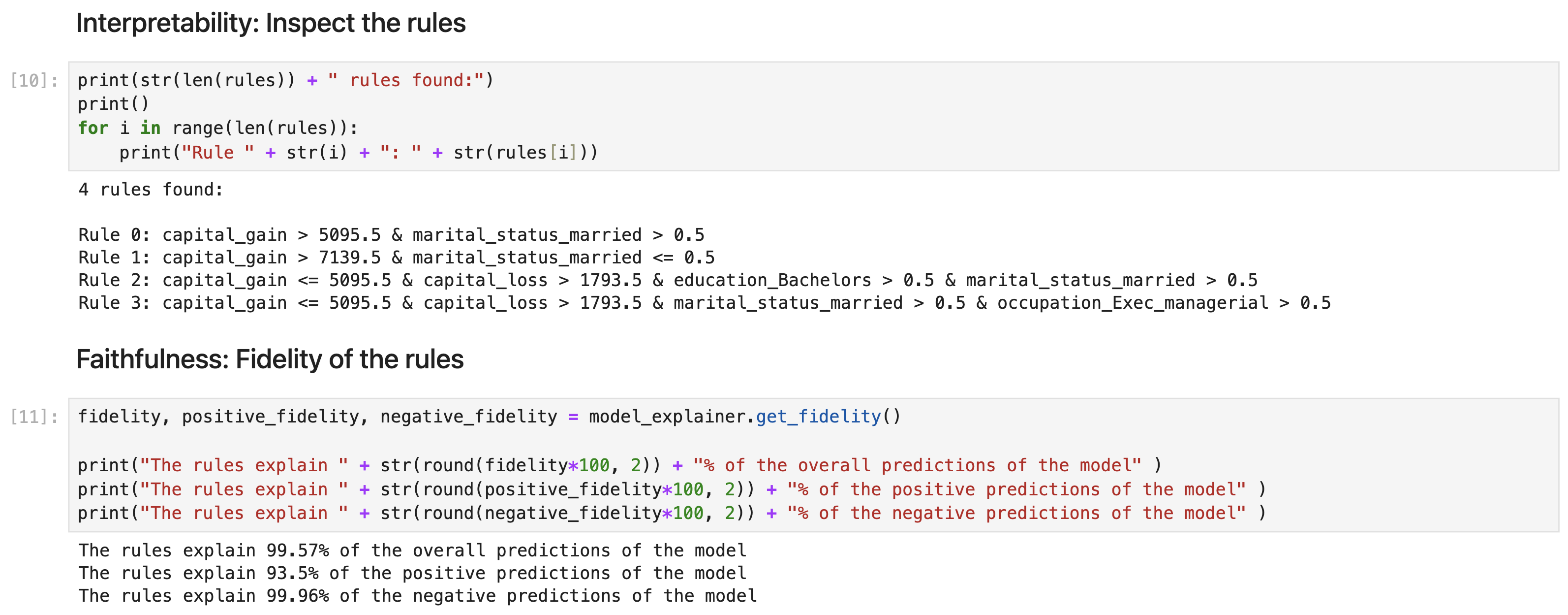
For evaluating the performance of the extracted rule list, the ModelExplainer provides a method get_fidelity() which returns the fractions of data for which the rule list agrees with the tree ensemble. get_fidelity() returns the fidelity on positives, negatives and overall fidelity.
The following notebook shows a typical use case of TE2Rules on Adult Income Data. The notebook can be found here. Let us start with importing te2rules and other relevant libraries

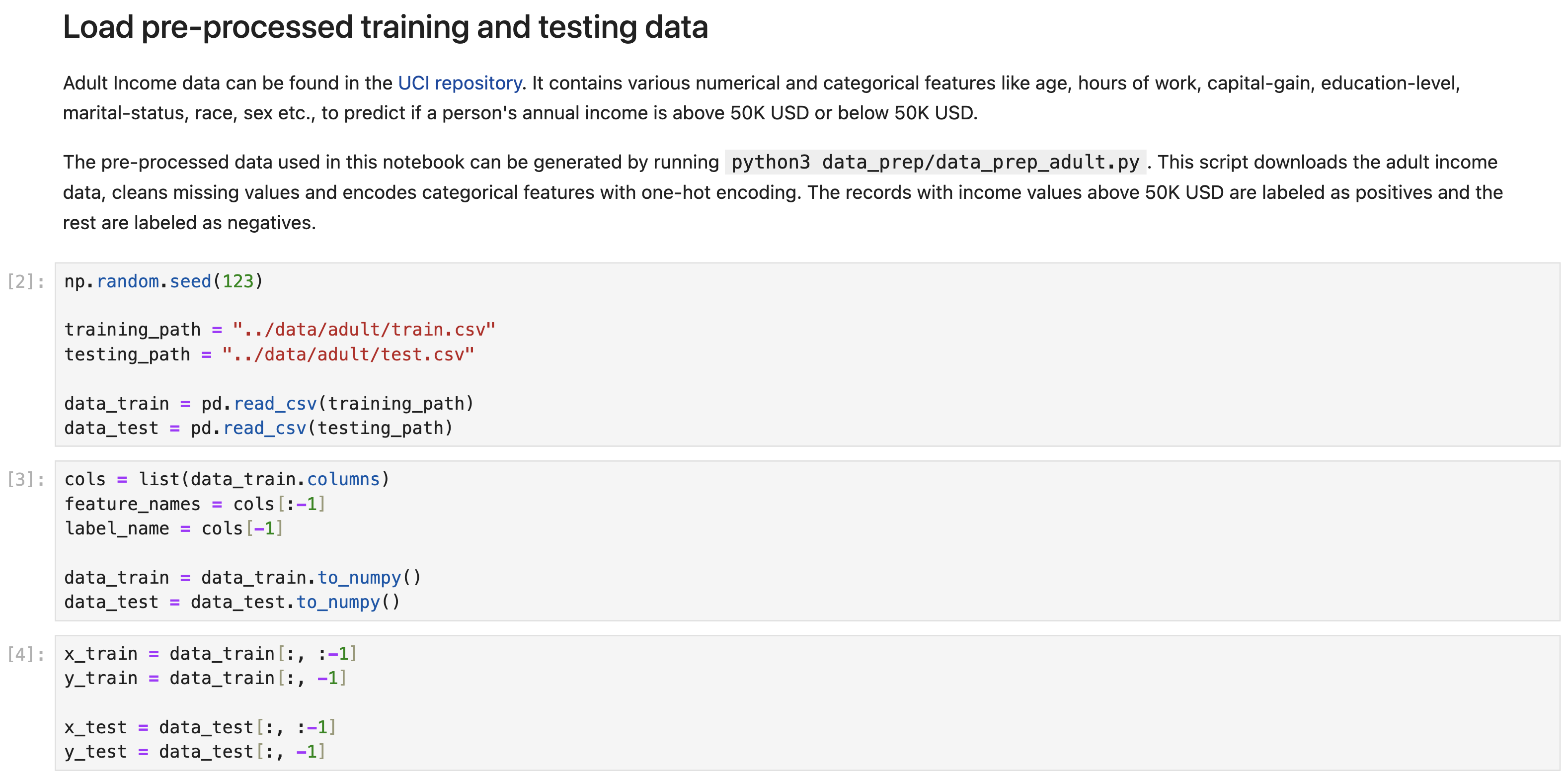
Let us load the training and testing data. All the data used in this notebook are preprocessed already and can be found here. The data can also be generated by running python3 data_prep/data_prep_adult.py.
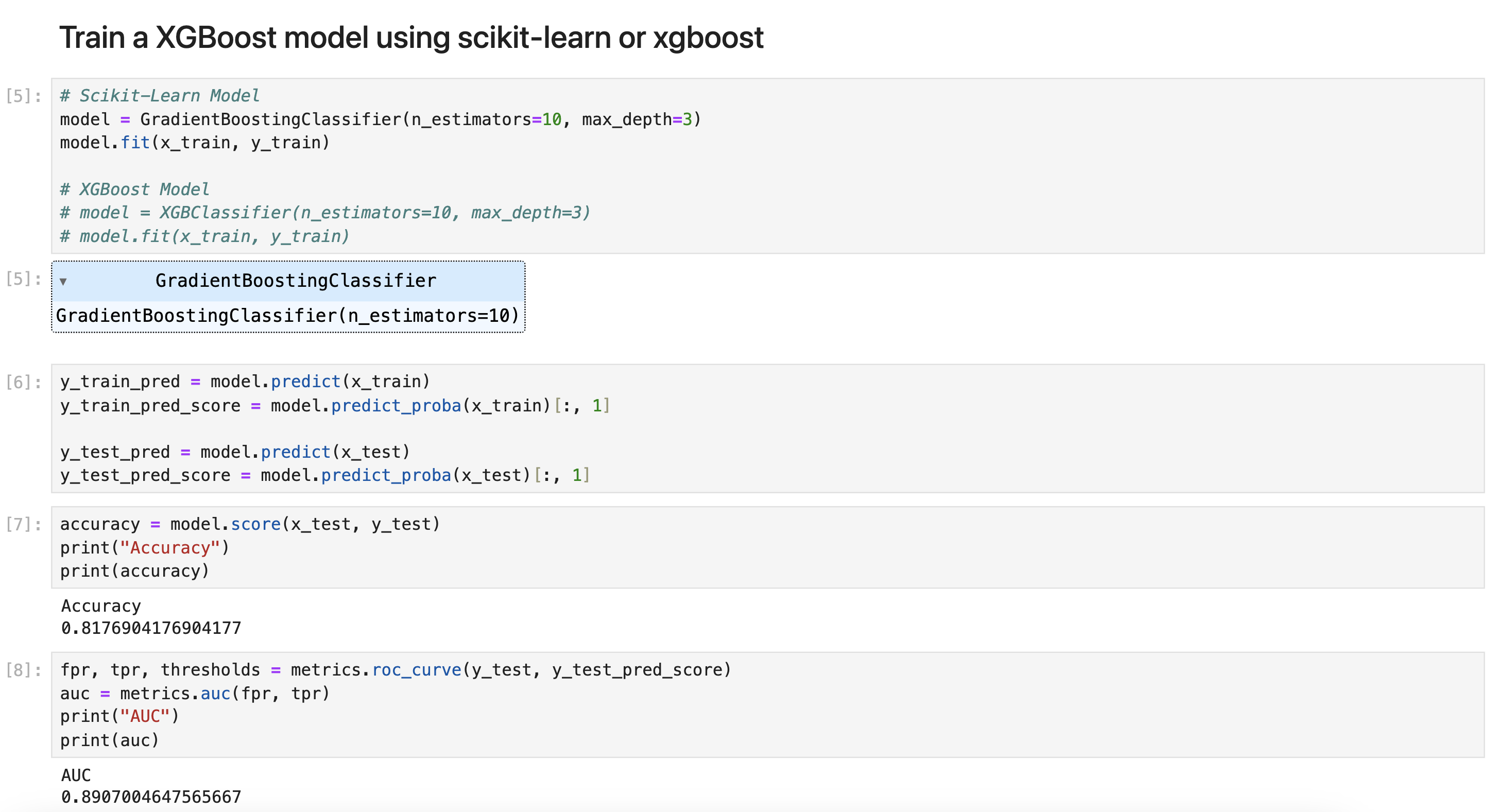
The tree ensemble model used in this notebook is a XGBoost model with 10 trees.
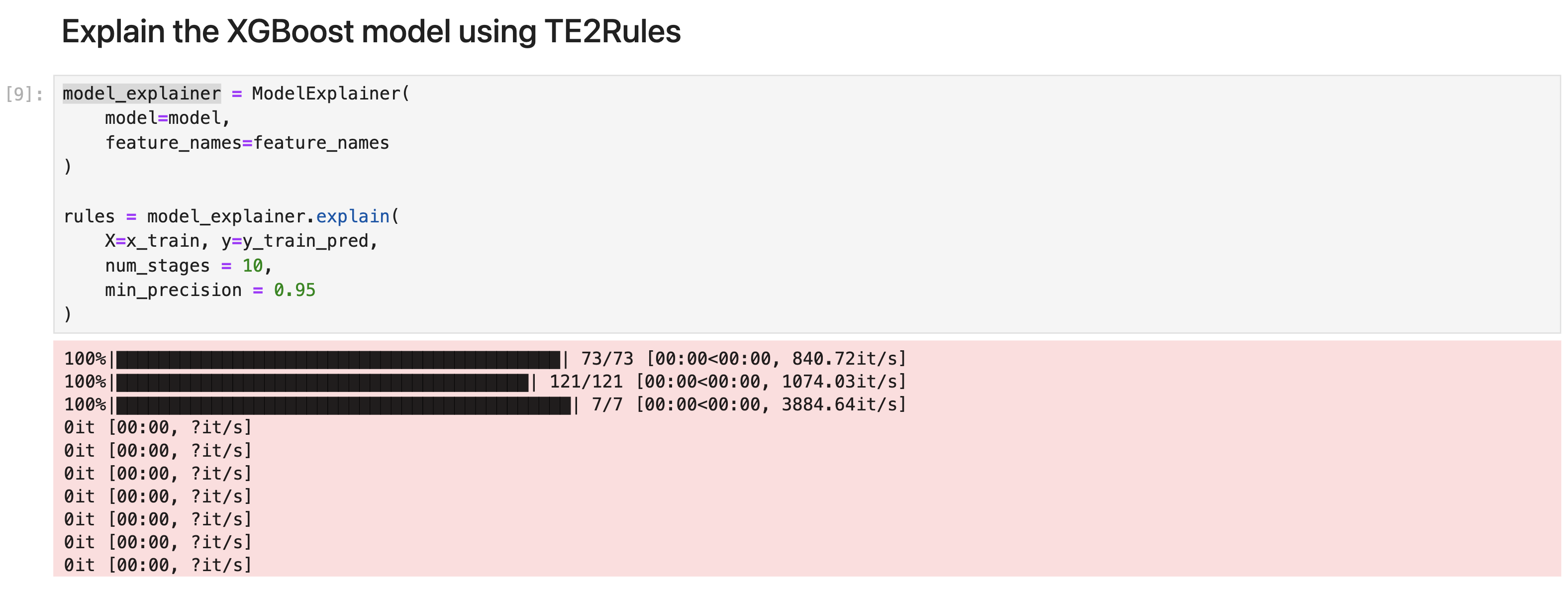
Let us use TE2Rules ModelExplainer to explain the positive class prediciton by the XGBoost model. We observe that TE2Rules extracts 5 rules to explain more than 99% of the positive class prediction by the tree ensemble model. In this usgae, we use the default values of min_precision (0.95) and num_stages (10), since the algorithm runs quickly for a tree ensemble with 10 trees.
These are not the only possible way to explain the model prediction. TE2Rules generates all possible explanations that can be extracted out of the tree ensemble model and then selects a short subset of rules out of all the possible rules such that the selected subset is small while explaining most of the positive class prediction by the model.
However, we need not settle with the subset of rules selected by TE2Rules. To see all the possible explanations, we can use longer_rules as shown below. From this set of rules, a domain expert can go through them and select their own small subset of rules that explains most of the positive model predictions and also aligns with the decision-making process often used in that domain. This way TE2Rules offers the flexibility to choose the explanations that most closely aligns with the human decision making process.

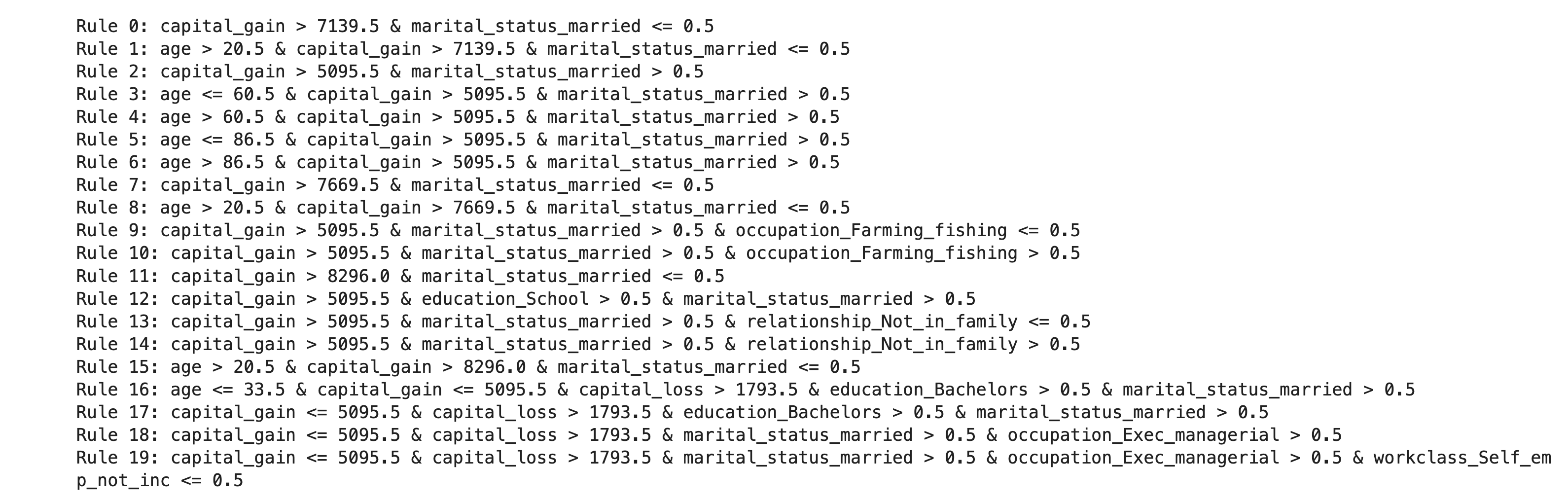
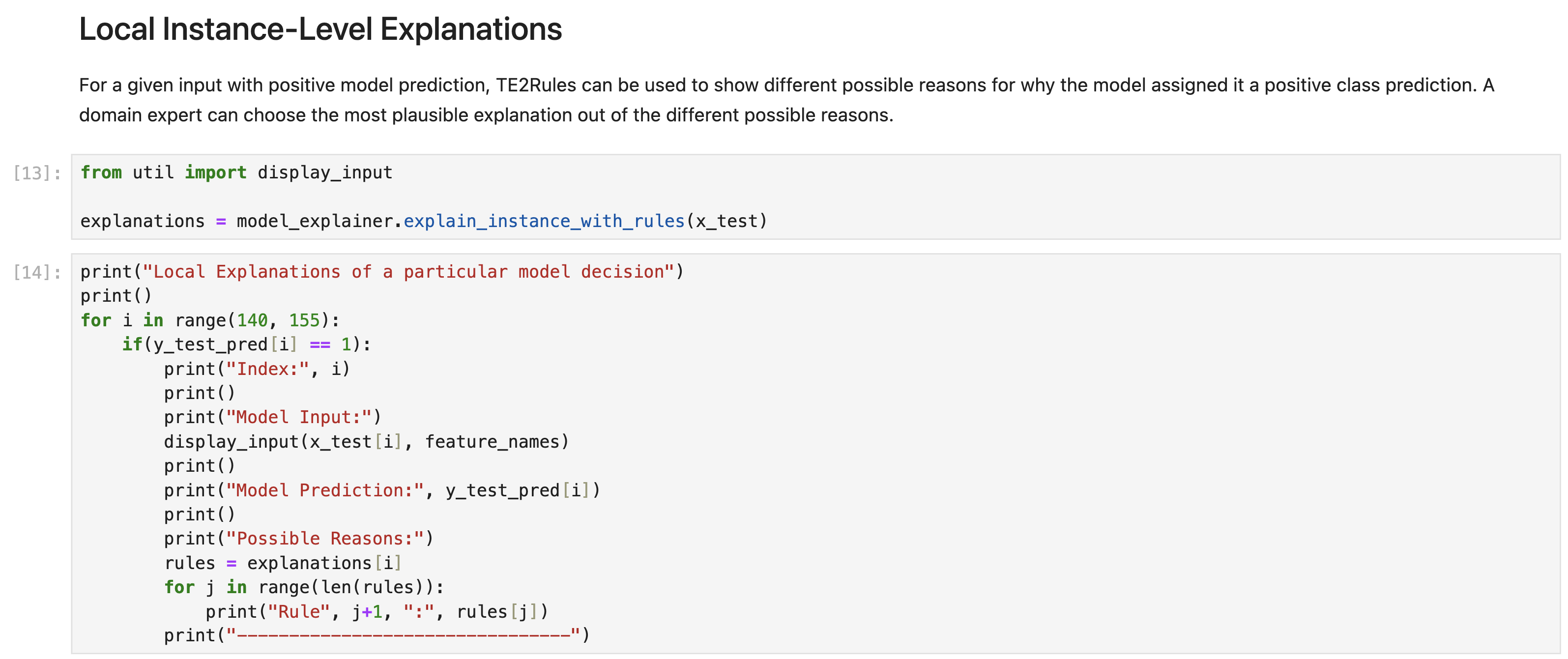
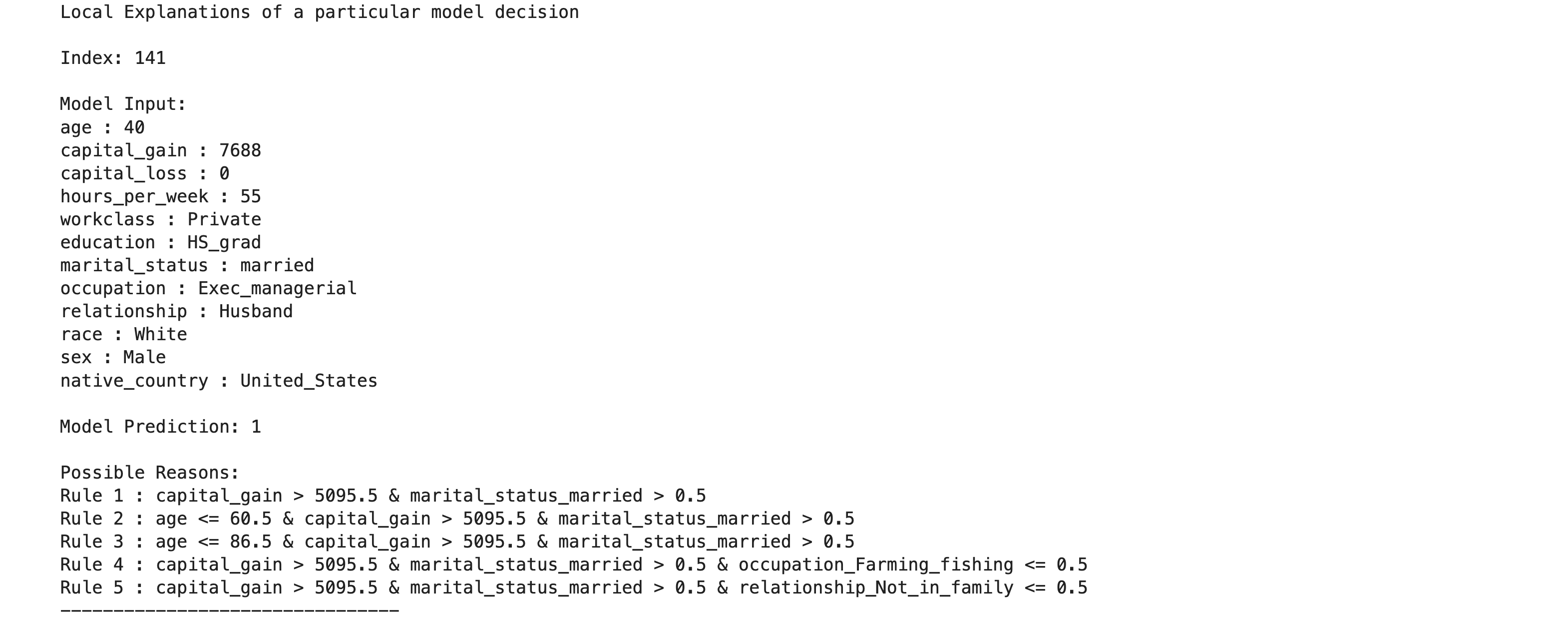
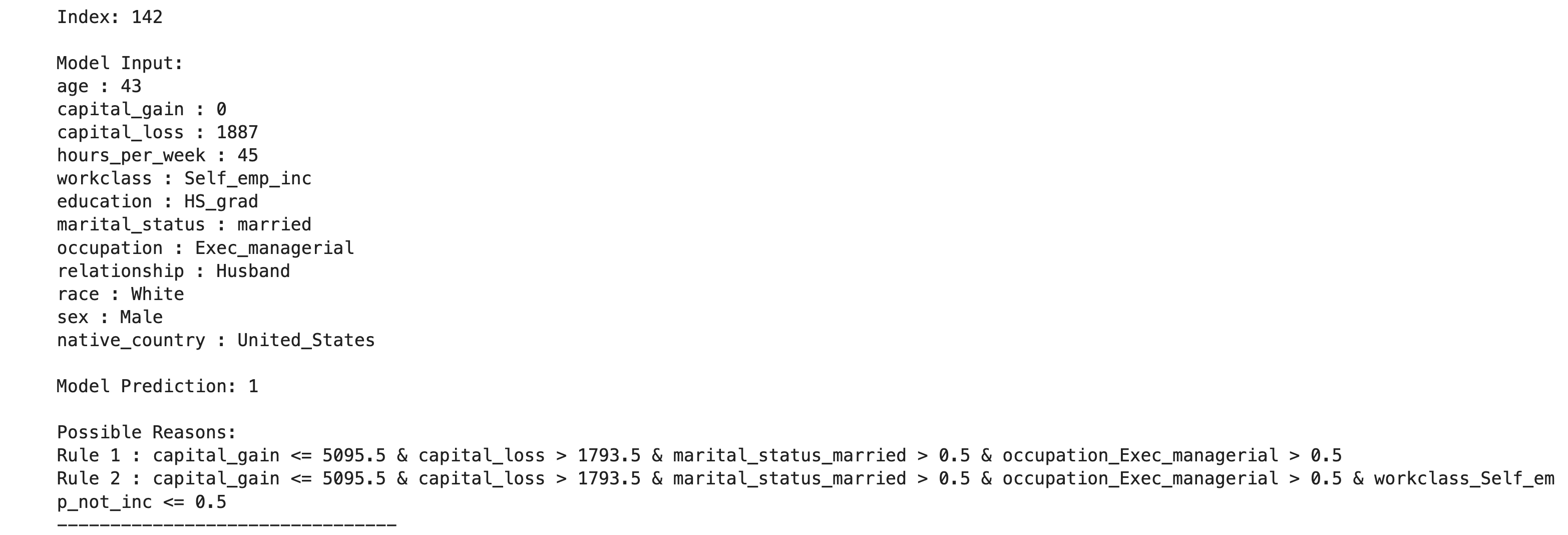
The longer set of all possible explanations would have significant overlap among the rules. For a given input to the model, multiple rules satisfying the input can be used to explain the input. The explain_instance_with_rules method provides one way to show all the possible rules that can explain each input instance. Again, a domain expert can pick the rule that is most suitable to explain that instance.


Here is a list of some applications of TE2Rules in high-stake domains like healthcare, where understanding why a ML model made a particular decision is critical in developing trust on the system.
- An Explainable Artificial Intelligence model in the assessment of Brain MRI Lesions in Multiple Sclerosis using Amplitude Modulation – Frequency Modulation multi-scale feature sets, By Andria Nicolaou, Antonis Kakas et al, In 2023 24th International Conference on Digital Signal Processing (DSP), https://ieeexplore.ieee.org/abstract/document/10167888
- Emergency Department Triage Hospitalization Prediction Based on Machine Learning and Rule Extraction, By Waqar A. Sulaiman, Andria Nicolaou et al, In 2023 IEEE EMBS Special Topic Conference on Data Science and Engineering in Healthcare, Medicine and Biology, https://ieeexplore.ieee.org/abstract/document/10405176
- An Explainable AI model in the assessment of Multiple Sclerosis using clinical data and Brain MRI lesion texture features, By A. Nicolaou, M. Pantzaris et al, In 2023 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), https://ieeexplore.ieee.org/abstract/document/10313379
- A Comparative Study of Explainable AI models in the Assessment of Multiple Sclerosis, By Andria Nicolaou, Nicoletta Prentzas et al, In 2023 Computer Analysis of Images and Patterns (CAIP 2023), https://link.springer.com/chapter/10.1007/978-3-031-44240-7_14
Run the follwing python scripts to generate the results in the paper:
python3 demo/demo/run_te2rules.py
python3 demo/demo/run_defrag.py
python3 demo/demo/run_intrees.py
python3 plot_performance.py
python3 plot_scalability.pyCreative Commons Attribution-NonCommercial 4.0 International Public License, see LICENSE for more details.
Please cite TE2Rules in your publications if it helps your research:
@article{te2rules2022,
title={TE2Rules: Explaining Tree Ensembles using Rules},
author={Lal, G Roshan and Chen, Xiaotong and Mithal, Varun},
journal={arXiv preprint arXiv:2206.14359},
year={2022}
}