
You can also find all 50 answers here 👉 Devinterview.io - NLP
Natural Language Processing (NLP) encompasses the interaction between computers and human languages, enabling machines to understand, interpret, and produce human text and speech.
From basic tasks such as text parsing to more advanced ones like sentiment analysis and translation, NLP is integral to various applications, including virtual assistants, content classification, and information retrieval systems.
-
Phonetics and Phonology: Concerned with the sounds and pronunciation of words and their combinations.
-
Morphology: Pertains to the structure of words, including their roots, prefixes, and suffixes.
-
Syntax: Covers sentence and phrase structure in a language, involving grammar rules and word order.
-
Semantics: Focuses on the meaning of words and sentences in a particular context.
-
Discourse Analysis: Examines larger units of language such as conversations or full documents.
-
Tokenization and Segmentation: Dividing text into its elementary units, such as words or sentences.
-
POS Tagging (Part-of-Speech Tagging): Assigning grammatical categories to words, like nouns, verbs, or adjectives.
-
Named Entity Recognition (NER): Identifying proper nouns or specific names in text.
-
Lemmatization and Stemming: Reducing words to their root form or a common base.
-
Word Sense Disambiguation: Determining the correct meaning of a word with multiple interpretations based on the context.
-
Parsing: Structurally analyzing sentences and establishing dependencies between words.
-
Sentiment Analysis: Assessing emotions or opinions expressed in text.
-
Ambiguity: Language is inherently ambiguous with words or phrases having multiple interpretations.
-
Context Sensitivity: The meaning of a word may vary depending on the context in which it's used.
-
Variability: Linguistic variations, including dialects or slang, pose challenges for NLP models.
-
Complex Sentences: Understanding intricate sentence structures, especially in literature or legal documents, can be demanding.
-
Negation and Irony: Recognizing negated statements or sarcasm is still a hurdle for many NLP models.
- 1950s: Alan Turing introduces the Turing Test.
- 1957: Noam Chomsky lays the foundation for formal language theory.
- 1966: ELIZA, the first chatbot, demonstrates NLP capabilities.
- 1978: SHRDLU, an early NLP system, interprets natural language commands in a block world environment.
- 1983: Chomsky's theories are integrated into practical models with the development of HPSG (Head-driven Phrase Structure Grammar).
- 1990s: Probabilistic models gain prominence in NLP.
- Early 2000s: Machine learning, especially neural networks, becomes increasingly influential in NLP.
- 2010s: The deep learning revolution significantly advances NLP.
-
BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT understands context and meaning in both directions, significantly improving performance in various NLP tasks.
-
GPT-3 (Generative Pre-trained Transformer 3): Notable for its massive scale of 175 billion parameters, GPT-3 is an autoregressive language model that outperforms its predecessors in tasks like text generation and understanding.
-
T5 (Text-to-Text Transfer Transformer): Google's T5 model demonstrates the effectiveness of a unified text-to-text framework across diverse NLP tasks.
-
XLNet (eXtreme multiLabel neural network): Further advancing on the Transformer architecture, XLNet incorporates permutations to better understand dependencies in sequences.
-
RoBERTa (A Robustly Optimized BERT Pretraining Approach): An optimized version of BERT from Facebook Research, RoBERTa adopts improved training and data strategies for better performance.
-
Text Classification: Automates tasks like email sorting and news categorization.
-
Sentiment Analysis: Tracks public opinion on social media and product reviews.
-
Machine Translation: Powers platforms like Google Translate.
-
Chatbots and Virtual Assistants: Enables automated text or voice interactions.
-
Voice Recognition: Facilitates speech-to-text and smart speakers.
-
Search and Recommendation Systems: Enhances user experience on websites and apps.
-
Privacy: NLP applications must handle user information responsibly.
-
Bias and Fairness: Developers must ensure NLP models are fair and unbiased across various demographics.
-
Transparency: Understandable systems are crucial for both technical and legal compliance.
-
Security: NLP tools that enable fraud detection or misinformation control must be robust.
-
Internationalization: Effective NLP models should be multilingual, considering the diversity of global users.
In Natural Language Processing (NLP), a corpus, tokenization, and stopwords are fundamental concepts.
-
What is it?
A corpus (plural: corpora) is a structured collection of text, often serving as the foundation for building a language model. Corpora can be domain-specific, say, for legal or medical texts, or general, covering a range of topics. -
Role in NLP
It acts as a textual dataset for tasks like language model training, sentiment analysis, and more.
-
What is it?
Tokenization is the process of breaking longer text into discrete units, or tokens, which could be words, n-grams, or characters. -
Common Strategies
Common tokenization strategies include splitting by whitespace, punctuation, or specific vocabularies. -
Key Role
Tokenization is a foundational step for various text processing tasks and is crucial for tasks like neural network for NLP.
-
What are They?
Stopwords are words that are often removed from texts during processing as they carry little meaning on their own (e.g., 'is', 'the', 'and') in bag-of-words models. -
Rationale for Removal
By eliminating stopwords, we can focus on content-carrying words and reduce data dimensionality, thus enhancing computational efficiency and, in some applications, improving the accuracy of text classification or clustering.
Morphology deals with the structure and formation of words, syntax its their arrangement in sentences.
-
Scope of Analysis: Morphology looks at individual words. Syntax considers sentences and the relationships between words.
-
Linguistic Elements Investigated:
- Morphology: Words, prefixes, suffixes, root forms, infixes, and more.
- Syntax: The syntactic structures and relationships between words. For example, the subject, verb, and object in a sentence or the noun phrases and verb phrases within it.
-
Units of Analysis:
- Morphology: The smallest grammatical units within the word (e.g., morphemes like "un-" and "happi-" in "unhappy").
- Syntax: The combination of words within a sentence to form meaningful structures or phrases.
-
Applications in NLP:
- Morphology is key for tasks such as stemming (reducing inflected words to their base or root form) and lemmatization (reducing words to a common base or lemma).
- Syntax is essential for grammar checking, part-of-speech tagging, and more sophisticated tasks such as natural language understanding and generation.
Morphological analysis helps with tasks such as:
- Stemming and Lemmatization: Reducing words to their basic form improves computational efficiency and information retrieval accuracy.
- Morphological Generation: Constructing words and their variations is useful in text generation and inflected language processing.
- Morphological Tagging: Identifying morphological properties of words contributes to accurate part-of-speech tagging, which in turn supports tasks like information extraction and machine translation.
Syntactic analysis is crucial for tasks such as:
- Parsing: Uncovering grammatical structures in sentences supports semantic interpretation and knowledge extraction.
- Sentence Boundary Detection: Identifies sentence boundaries, aiding in various processing tasks, such as summarization and text segmentation.
- Gross Syntactic Tasks: Such as identifying subjects and objects, verb clustering, and maintaining grammatical accuracy in tasks like language generation and style transfer.
Consider the sentence:
- "Riders are riding the horses riding wildly."
- Tokenized Version: ['Riders', 'are', 'riding', 'the', 'horses', 'riding', 'wildly']
- Stemmed Version: ['Rider', 'ar', 'ride', 'the', 'hors', 'ride', 'wild']
- Tokenized Version: ['Riders', 'are', 'riding', 'the', 'horses', 'riding', 'wildly']
- Lemmatized Version: ['Rider', 'be', 'ride', 'the', 'horse', 'ride', 'wildly']
Part-of-Speech (POS) Tagging plays a fundamental role in natural language processing by identifying the grammatical components of text, such as words and phrases, and labeling them with their corresponding parts of speech.
POS tagging is often the initial step in more advanced syntactic parsing tasks, such as chunking or full parsing, that help uncover the broader grammatical structure of a sentence.
This provides the semantic context necessary for understanding the subtle nuances and deeper meanings within the text.
POS tags are used to extract and identify key pieces of information from a body of text. This function is essential for tools that aim to summarize or extract structured information, such as named-entity recognition and relation extraction.
In some cases, the grammatical form of a word, as captured by its POS tag, can be the clue needed to discern its semantic meaning. For instance, the same word might function as a noun or verb, with vastly different interpretations: consider the word "sink."
POS tagging aids in identifying the base or root form of a word. This is an essential task for a variety of NLP applications, like search engines or systems monitoring sentiment, as analyzing a word's structure can reveal more about its context and significance in a given text.
Furthermore, POS tagging and related tasks are part of the foundation for a wide range of essential NLP tasks such as speech recognition, machine translation, text-to-speech systems, and much more.
In the domain of customer service, businesses can use POS tagging to understand the intention behind customer queries. This capability can drive automation strategies like chatbots, where customer requests can be tagged with important grammatical information to inform proper responses.
In media monitoring and sentiment analysis, POS tagging is used to identify the key components of sentences, phrases, or paragraphs, which in turn can help determine sentiment or extract useful data.
- Ambiguity: Many words can serve as different parts of speech, depending on their use or context.
- Multiple Tags: Some words can have more than one POS, such as the word "well" which can be an adverb, adjective, or noun.
Recognizing these complexities and navigating resolutions is crucial for developing a deeper and more accurate analysis of natural language data.
Both lemmatization and stemming are methods for reducing inflected words to their root forms.
- Definition: Stemming uses an algorithmic, rule-based approach to cut off word endings, producing the stem. This process can sometimes result in non-real words, known as "raw" stems.
- Example: The stem of "running" is "run."
- Code Example (Using NLTK):
from nltk.stem import PorterStemmer stemmer = PorterStemmer() stem = stemmer.stem("running")
- Definition: Lemmatization, on the other hand, uses a linguistic approach that considers the word's context. It maps inflected forms to their base or dictionary form (lemma).
- Example: The lemma of "running" is "run".
- Code Example (Using NLTK):
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() lemma = lemmatizer.lemmatize("running", pos="v") # Need to specify part of speech (pos)
- Stemming: Useful for tasks like text classification when speed is a priority. The technique is simpler and quicker than lemmatization, but it may sacrifice precision and produce non-real words.
- Lemmatization: Ideal when semantic accuracy is crucial, such as in question-answering systems or topic modeling. It ensures that the root form retains its existing meaning in the text, potentially leading to better results in tasks that require understanding and interpretation of the text.
In general, if you require interpretability (the capability to interpret the outcome of an ML model, for example) or have a need for precise language understanding, lemmatization is often the better choice. However, if your task is purely computational, derives more complex models or intended to process a large volume of text in a relatively short time, you might opt for stemming instead.
In Natural Language Processing, a named entity (NE) refers to real-world objects, such as persons, dates, or locations, that are assigned proper names.
Named Entity Recognition (NER) utilizes machine learning techniques, such as sequence labeling and deep learning, to identify and categorize named entities within larger bodies of text.
NER recognizes entities like:
- Person Names: E.g., "John Doe"
- Locations: E.g., "New York"
- Organizations: E.g., "Google"
- Dates: E.g., "January 1, 2022"
- Numeric References: E.g., "$10,000"
- Product Names: E.g., "iPhone"
- Time Notations: E.g., "4 PM"
-
Information Retrieval and Summarization: Identifying entities aids in summarizing content and retrieving specific information.
-
Question Answering Systems: Helps to understand what or who a question is about.
-
Relation Extraction: Can provide insight into relationships between recognizable entities.
-
Sentiment and Opinion Analysis: Understanding the context in which named entities appear can guide sentiment analysis.
-
Geotagging: Identifying place names facilitates geographically tagging content.
-
Recommendation Systems: Identifying products, organizations, or other named entities enhances the power of recommendation systems.
-
Competitive Intelligence: Identifying and categorizing company names and other organizations can provide valuable insights for businesses.
-
Legal and Regulatory Compliance Monitoring: For tasks like contract analysis, identifying named entities can be crucial.
Here is the Python code:
import spacy
# Load the English NER model
nlp = spacy.load('en_core_web_sm')
# Sample text
text = "Apple is looking at buying U.K. startup for $1 billion."
# Process the text
doc = nlp(text)
# Extract and display entity labels
for ent in doc.ents:
print(ent.text, ent.label_)- The output would be
"Apple" ORG,"U.K." GPE, and"$1 billion" MONEY.
Sentiment analysis (SA), also known as opinion mining, is the computational study of people's emotions, attitudes, and opinions from text data. Its core goal is determining whether a piece of writing is positive, negative, or neutral.
Applications of sentiment analysis are diverse, spanning diverse domains including:
-
Business: SA can streamline customer feedback analysis, brand management, and product development.
-
Marketing: Identifying trends and insights from social and digital media, understanding customer desires and pain points, developing targeted advertising campaigns.
-
Customer Service: Quick and automated identification of customer needs and moods, routing priority or potentially negative feedback to relevant support channels.
-
Politics and Social Sciences: Tracking public opinion, election forecasting, and analyzing the impact of policies and events on public sentiment.
-
Healthcare: Monitoring mental health trends and identifying potential outbreaks of diseases by processing texts from online forums, review platforms, and social media.
-
News and Media: Understand reader/viewer views, opinions, and feedback, and track trends in public sentiment related to news topics.
-
Legal and Regulatory Compliance: Analyzing large volumes of text data to identify compliance issues, legal risks, and reputation-related risks.
-
Market Research: Gather and analyze consumer comments, reviews, and feedback to inform product/service development, branding decisions, and more.
-
Education: Assessing student engagement and learning by analyzing their online posts about course materials or studying experiences.
-
Customer Feedback Surveys: Automating the analysis of feedback from surveys, focus groups, or comment sections. For example, hotel reviews on travel websites help travelers make informed decisions.
-
Voice of the Customer (VOC): Interpreting and identifying customer feelings and insights across multiple communication channels: calls, chat, emails, and social media.
-
Text-Based Searches: Ranking results based on sentiment with some search engines or social platforms.
-
Automated Content Moderation: Identifying and flagging inappropriate or harmful content on online platforms, including hate speech, bullying, or adult content.
-
Financial Services: Assessing investor sentiments, measuring market reactions to financial news, and gauging public opinions on specific companies through social or news media.
While related, emotion recognition focuses on identifying specific emotions in text, such as joy, anger, or sadness, and it can encompass human input from sources like images or videos. Sentiment analysis has evolved from just determining polarity to more nuanced tasks such as aspect-based sentiment analysis, which can discriminate between different aspects of a product or service and gauge their individual sentiment.
A dependency parser is a tool used in natural language processing (NLP) to extract grammatical structure from free-form text.
-
Word-Level Classification: Each word is classified based on its relationship with others. Examples of classifications are Subject (nsubj), Object (obj), and Modifiers (e.g. amod for adjectival modification).
-
Arc Representation: These are labeled directed edges, or arcs, between words. They represent a grammatical relationship and provide the basis for constructing the parsing tree.
-
Initial Assignment: The parser begins by giving each word a universal "root" node to define the starting point of the parse tree.
-
Iterative Classification: For every word, the algorithm assigns both a word-level classification and a directed arc to another word, specifying the relationship from the first to the second.
-
Tree Check: Throughout the process, the parser ensures that the set of classified arcs forms a single, non-looping tree, known as a "projective parse tree."
-
Recursive Structure: The tree starts from the "root" node and recursively accounts for word and arc classifications to create dependencies covering the entire sentence.
Here is the Python code:
import spacy
# Load English tokenizer, tagger, parser, NER, and word vectors
nlp = spacy.load("en_core_web_sm")
# Process a sentence using the dependency parser
doc = nlp("The quick brown fox jumps over the lazy dog.")
# Print the dependencies of each token in the sentence
for token in doc:
print(token.text, token.dep_, token.head.text, token.head.pos_,
[child for child in token.children])In this code example, we use the spaCy library to perform dependency parsing on the sentence: "The quick brown fox jumps over the lazy dog." The output will display the word, its word-level classification (dep_), the head word it's connected to, the head word's part-of-speech tag (pos_), and the word's children.
N-grams are sequential word or character sets, with "n" indicating the number of elements in a particular set. They play a crucial role in understanding context and text prediction, especially in statistical language models.
-
Unigrams: Single words
$w_{i}$ -
Bigrams: Pairs of words
$w_{i-1}, w_{i}$ -
Trigrams: Three-word sequences
$w_{i-2}, w_{i-1}, w_{i}$ - And so on...
- Text Prediction: Using contextual cues to predict next words.
- Speech Recognition: Relating phonemes to known word sequences.
- Machine Translation: Contextual understanding for accurate translations.
- Optical Character Recognition (OCR): Correcting recognition errors based on surrounding text.
- Spelling Correction: Matching misspelled words to known N-grams.
Here is the Python code:
from nltk import ngrams, word_tokenize
# Define input text
text = "This is a simple example for generating n-grams using NLTK."
# Tokenize the text into words
tokenized_text = word_tokenize(text.lower())
# Generate different types of N-grams
unigrams = ngrams(tokenized_text, 1)
bigrams = ngrams(tokenized_text, 2)
trigrams = ngrams(tokenized_text, 3)
# Print the generated n-grams
print("Unigrams:", [gram for gram in unigrams])
print("Bigrams:", [gram for gram in bigrams])
print("Trigrams:", [gram for gram in trigrams])The Bag of Words model, or BoW, is a fundamental technique in Natural Language Processing (NLP). This model disregards the word order and syntax within a text, focusing instead on the presence and frequency of words.
- Text Collection: Gather a set of documents or a corpus.
- Tokenization: Split the text into individual words, known as tokens.
- Vocabulary Building: Identify unique tokens, constituting the vocabulary.
- Vectorization: Represent each document as a numerical vector, where each element reflects word presence or frequency in the vocabulary.
Here is the Python code:
from sklearn.feature_extraction.text import CountVectorizer
# Sample data
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
]
# Create BoW model
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
# Visualize outputs
print(vectorizer.get_feature_names_out())
print(X.toarray())The output shows the unique feature names (vocabulary) and the BoW representations of each document.
While simplistic, this model has its limitations:
-
Loss of Word Order: Disregarding word dependencies and contextual meanings can hinder performance.
-
Lacking Context: Assigning the same weight to identical words across different documents can lead to skewed representations.
-
Dimensionality: The vector's length equals the vocabulary size, getting unwieldy with large corpora.
-
Word Sense Ambiguity: Fails to distinguish meanings of polysemous words (words with multiple meanings) or homonyms.
-
Non-linguistic Information: Ignores parts of speech, negation, and any linguistic subtleties.
-
Out-of-Vocabulary Words: Struggles to handle new words or spelling variations.
Naive Bayes classifier is a popular choice for text classification tasks in Natural Language Processing (NLP). It's preferred for its simplicity, speed, and effectiveness.
Naive Bayes makes use of Bag of Words techniques, treating the order of words as irrelevant. It calculates the probability of a document belonging to a specific category based on the probability of words occurring within that category.
- Bag of Words: Represents text as an unordered set of words, simplifying the text and data representation.
- Conditional Independence Assumption: This core assumption of Naive Bayes states that the presence of a word in a category is independent of the presence of other words.
- Efficiency: It's computationally lightweight and doesn't require extensive tuning.
- Simplicity: Easy to implement and understand.
- Low Data Requirements: Can be effective even in situations with smaller training datasets.
Here is the Python code:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
# Sample Data: Emails labeled as either Spam or Ham.
emails = [
("Win a free iPhone", "spam"),
("Meeting at 3 pm", "ham"),
("Verify your account", "spam"),
# More emails...
]
# Separate into features and target
X, y = zip(*emails)
# Split into training and testing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Convert text to a numerical format using CountVectorizer
vectorizer = CountVectorizer()
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
# Fit Naive Bayes to the training data
nb_classifier = MultinomialNB()
nb_classifier.fit(X_train_vec, y_train)
# Evaluate on test data
accuracy = nb_classifier.score(X_test_vec, y_test)
print(f"Accuracy: {accuracy:.2f}")- Out-of-Vocabulary Words: The model may struggle with words it has not seen before. Techniques like smoothing can reduce this issue.
- Word Sense Disambiguation: The model assumes that words have consistent meanings, ignoring nuances. This can be problematic for words with multiple meanings.
- Zipf's Law: The classifier might be influenced by the frequency of words, prioritizing common words and potentially overlooking rare, but valuable, ones.
- Contextual Information: Naive Bayes doesn't consider word context or word order, making it less effective in tasks that require understanding of such nuances (like sentiment analysis or contextual disambiguation).
12. How are Hidden Markov Models (HMMs) applied in NLP tasks?
Hidden Markov Models (HMMs) have a long-standing role in Natural Language Processing (NLP) tasks due to their ability to handle sequential data like text.
From the early days of POS tagging to modern speech recognition and language translation, HMMs have been instrumental in numerous tasks.
- Observations: These are the visible units, representing input words or phrases, making them a natural fit for linguistic tasks.
- States: These invisible units embody underlying linguistic structures or concepts.
- Supervised Learning: Through manually annotated data, an HMM can learn transition and emission probabilities.
- Unsupervised Learning: Algorithms like Baum-Welch can optimize the model when labeled data is scarce or non-existent.
- Description: Determines the part of speech for each word in a sentence.
- HMM Role: The most common application of HMMs in NLP. Each POS tag is a state, and the observed word is the corresponding observed output.
- Description: Identifies entities in text, such as names of persons, locations, or organizations.
- HMM Role: Useful in sequence modeling tasks, where the existence of one entity influences the presence of another (e.g., "United States President").
- Description: Links an entity, usually a nominal phrase, such as a proper name or a pronoun, to its previous references.
- HMM Role: Helps in making coreference decisions based on chains of references and broader context.
- Description: Translates text from one language to another.
- HMM Role: In the pre-sequence to sequence model era, HMMs were used for alignment between two sequences, i.e., source and target sentences.
- Lack of Context: HMMs are limited to local data, which can lead to suboptimal performance, especially in complex tasks requiring global context.
- Scalability Concerns: With growing datasets and evolving language use, constant model retraining and capacity to encompass lexicons become necessary.
Here is the Python code:
import nltk
# Get data
nltk.download('treebank')
nltk.download('maxent_treebank_pos_tagger')
from nltk.corpus import treebank
data = treebank.tagged_sents()[:3000]
# Split data
split = int(0.9 * len(data))
train_data = data[:split]
test_data = data[split:]
# Train the HMM POS tagger
from nltk.tag import hmm
tagger = hmm.HiddenMarkovModelTrainer().train(train_data)
# Evaluate accuracy
accuracy = tagger.evaluate(test_data)
print(f"Accuracy: {accuracy:.2%}")Text Classification is a common Natural Language Processing (NLP) task and SVMs play a key role in this area.
-
Prioritizing Relevance: SVMs aim to non-linearly separate groups of text, making them suitable for tasks like keyword identification and sentiment analysis.
-
Handling Sparse Data: SVMs perform well on high-dimensional, sparse datasets common in NLP tasks.
-
Feature Engineering: SVMs often require careful feature selection, which can be achieved using techniques like TF-IDF or word embeddings.
-
Model Interpretability: While traditionally considered a "black box," text classification with SVM can still gain some interpretability through feature importance analysis.
-
Scaling to Large Datasets: With the help of techniques like stochastic gradient descent, SVMs can handle large text corpora efficiently.
-
Good Out-of-the-box Performance: SVMs don't require extensive hyperparameter tuning, making them attractive for quick, reliable results.
-
Multi-Class Classification: Through strategies like "one-versus-one" or "one-versus-rest" classification, SVMs can handle tasks that involve more than two classes.
-
Kernel Functions: Allow SVMs to operate in a higher-dimensional space to achieve better class separation, without explicitly transforming input data.
-
Hyperplanes and Margins: SVMs are designed to find the hyperplane that maximizes the margin between data points of different classes. This ensures better generalization.
-
Support Vectors: These are the data points critical for defining the separating hyperplane. All other data points are irrelevant for the decision boundary.
Here is the Python code:
from sklearn import svm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# Sample data
corpus = [
'This is good',
'This is bad',
'This is awesome',
'This is terrible'
]
labels = ['positive', 'negative', 'positive', 'negative']
# Text vectorization
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# SVM model
model = svm.SVC(kernel='linear')
model.fit(X_train, y_train)
# Predictions and evaluation
y_pred = model.predict(X_test)
print('Accuracy:', accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))While Random Forests are most commonly associated with classification tasks, they also harbor several advantages for Natural Language Processing (NLP) applications.
-
Textual Data Flexibility: Random Forests can handle both numerical and categorical data, making them suitable for text analysis where features can be a mix of words, phrases, and other linguistic elements.
-
Feature Importance: They provide metrics on the importance of different input features. In NLP, this can reveal which words or n-grams are most influential in making predictions.
-
Efficiency with Sparse Data: Since text data usually results in high-dimensional, sparse feature spaces, Random Forests' decision trees are well-suited to handle this complexity without needing data transformation or dimensionality reduction techniques.
-
Outlier Robustness: Random Forests are less susceptible to overfitting due to noise or outliers in datasets — a common occurrence in unstructured text data.
-
Implicit Feature Engineering: The ensemble nature of Random Forests allows for combining multiple decision trees, which effectively integrates feature engineering across the trees.
-
Memory Efficient: The way that decision trees in a Random Forest are constructed often leads to lower memory requirements compared to other ensemble models like Boosting.
-
Consistency in Predictions: Random Forests tend to make reliable predictions across diverse data, and this holds true for NLP tasks dealing with varying text structures.
-
Reduced Variance: Random Forests are less sensitive to changes in the training data and thus have a reduced risk of overfitting that can be crucial in NLP, especially for tasks like sentiment analysis.
Decision Trees in the context of Natural Language Processing (NLP) are multi-purpose, offering text analysis solutions across sentiment analysis, topic modeling, and language understanding. Here is an overview of how they operate in an NLP setting.
At its core, a Decision Tree is a graph that employs a tree-like structure to make decisions based on conditions or features. In each decision node or leaf node, it employs a decision rule or assigns a class label.
- Feature Selection: Textual features like word presence or frequency can influence decision-making in the tree's nodes.
- Text Classification: The tree aids in assigning labels like "positive" or "negative" based on extracted text features.
-
Text Classification: Assigning documents, paragraphs, or sentences to predefined categories or labels.
-
Sentiment Analysis: Gauging textual content's sentiment and assigning a sentiment label, such as "positive," "neutral," or "negative."
-
Named Entity Recognition: Identifying named entities like names, dates, locations, etc., in text.
-
Document Summarization: Generating abridged versions of documents or textual data.
-
Language Understanding: Assisting in comprehension tasks by recognizing patterns and context within the text.
-
Topic Modeling: Uncovering latent topics within a corpus or a collection of text.
Here is an example of a Decision Tree in the context of text-based sentiment analysis:
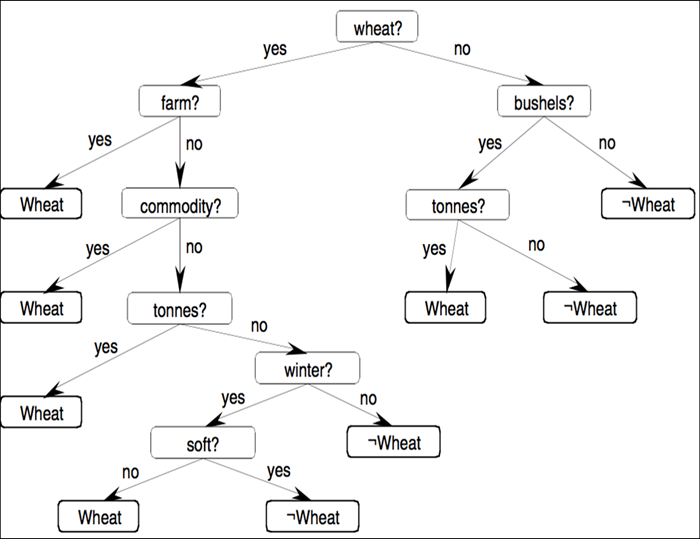
The tree can be interpreted as follows:
-
For a sentence to be classed as "Positive," it needs to meet both conditions: word frequency of "amazing" is above a certain threshold, and "exciting" frequency is below a threshold.
-
Sentences that do not satisfy both conditions are classified as "Negative."
- Overfitting: To tackle this, text-specific pre-processing, pruning, and setting tree depth limits are common strategies.
- Feature Engineering: Efforts are needed to convert raw text into features that Decision Trees can utilize.
Here is the Python code:
# Import necessary libraries
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
# Prepare data
data = {'text': ["This movie was amazing!", "I really disliked the book.", "The play was quite good."],
'label': [1, 0, 1]} # 1 for positive, 0 for negative
df = pd.DataFrame(data)
X = df['text']
y = df['label']
# Text vectorization
vectorizer = CountVectorizer()
X_vectorized = vectorizer.fit_transform(X)
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X_vectorized, y, test_size=0.2, random_state=42)
# Decision Tree model
dt_model = DecisionTreeClassifier()
dt_model.fit(X_train, y_train)
# Predict and evaluate
y_pred = dt_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Explore all 50 answers here 👉 Devinterview.io - NLP