RAGnarok is a Retrieval-Augmented Generation chatbot frontend for Nemesis. It allows you to ask questions about text extracted from compatible documents processed by Nemesis.
Short explanation: The general idea with Retrieval-Augmented Generation (RAG) is to allow a large language model (LLM) to answer questions about documents you've indexed.
Medium explanation: RAG involves processing and turning text inputs into set-length vectors via an embedding model, which are then stored in a backend vector database. Questions to the LLM are then used to look up the "most similiar" chunks of text which are then fed into the context prompt for a LLM.
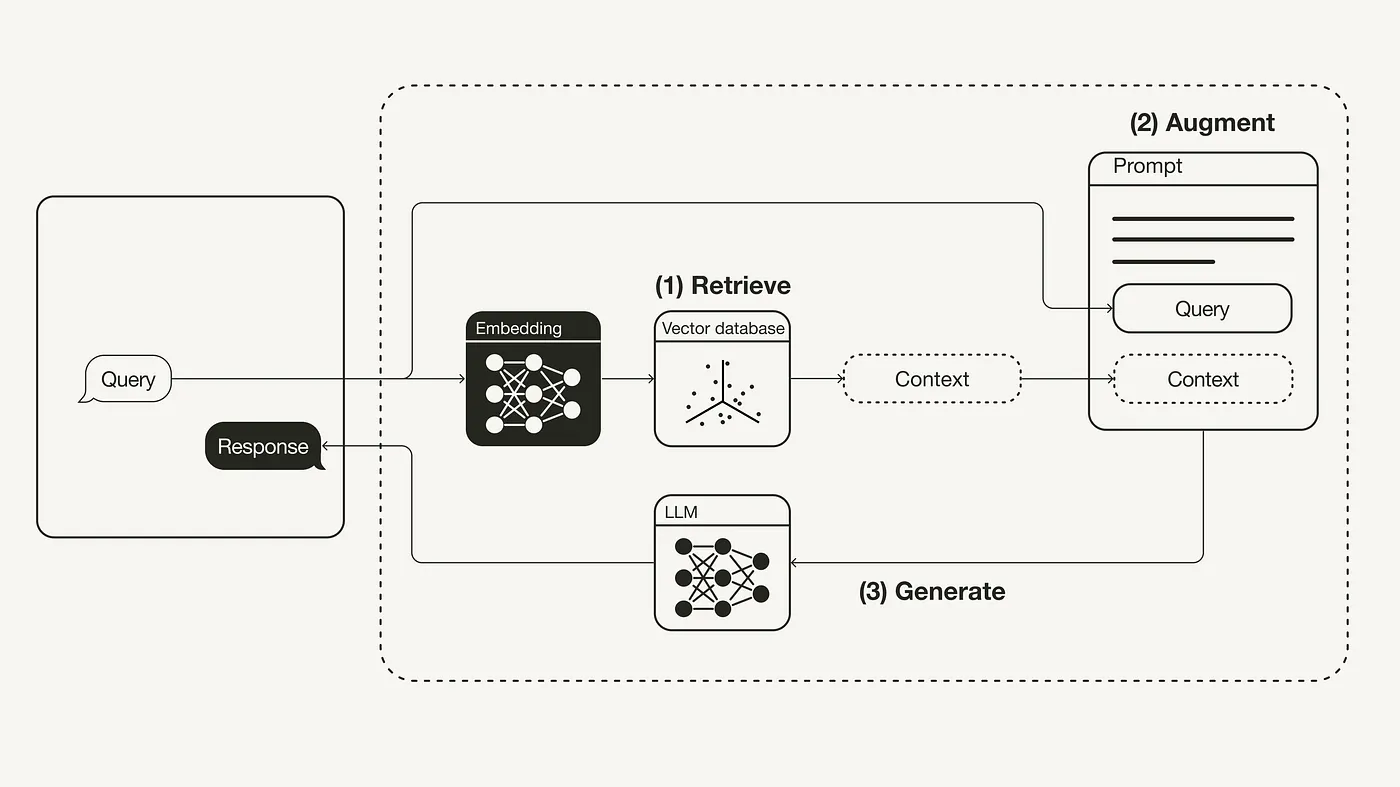
Longer explanation in the rest of the section :)
Even Longer explanation in this blog post.
Retrieval-augumented generation is an architecture where documents being processed undergo the following process:
- Plaintext is extracted from any incoming documents.
- Nemesis uses Apache Tika to extract text from compatible documents.
- The text is tokenized into chunks of up to X tokens, where X depends on the context window of the embedding model used.
- Nemesis uses Langchain's TokenTextSplitter, a chunk size of 510 tokens, and a 15% overlap between chunks.
- Each chunk of text is processed by an embedding model which turns the input text into a fixed-length vector of floats.
- As Pinecone explains, what's cool about embedding models is that the vector representations they produce preserve "semantic similiarity", meaning that more similiar chunks of text will have more similiar vectors.
- Nemesis currently uses the TaylorAI/gte-tiny embedding model as it's fast, but others are possible.
- Each vector and associated snippet of text is stored in a vector database.
- Nemesis uses Elasticsearch for vector storage.
This is the initial indexing process that Nemesis has been performing for a while. However, in order to complete a RAG-pipeline, the next steps are:
- Take an input prompt, such as "What is a certificate?" and run it through the same embedding model files were indexed with.
- Query the vector database (e.g., Elasticsearch) for the nearest k vectors + associated text chunks that are "closest" to the prompt input vector.
- This will return the k chunks of text that are the most similiar to the input query.
- We also use Elasticsearch's traditional(-ish) BM25 text search over the text for each chunk.
- These two lists of results are combined with Reciprocal Rank Fusion, and the top results from the fused list are returned.
- Note: steps 6 and 7 happen in the
nlpcontainer in Nemesis. This is exposed at http://<nemesis>/nlp/hybrid_search
We now have the k most chunks of text most simliar to our input query. If we want to get a bit facier, we can execute what's called reranking.
- With reranking, the the prompt question and text results are paired up (question, text) and fed into a more powerful model (well, more powerful than the embedding model) tuned and known as a reranker. The reranker generates a simliarity score of the input prompt and text chunk.
- RAGnarok uses an adapted version of BAAI/bge-reranker-base for reranking.
- The results are then reranked and the top X number of results are selected.
- Finally, the resulting texts are combined with a prompt to the (local) LLM. Think something along the lines of "Given these chunks of text {X}, answer this question {Y}".